はじめに
お世話になっております。primeuNumberの庵原です。
処暑の候、いかがお過ごしでしょうか。
今回はGoogle CloudのDatastreamを本番運用開始するにあたって検証した内容や構築に際してつまづいた点やTipsなどを共有できればと思います。
対象
- Datastreamについて興味がある方
- RDBMSからBigQueryへのレプリケーション(複製)の実際のソリューションが気になる方
- DatastreamのTipsやつまづいた点が気になる方
Datastreamについての説明
概要
・MySQL、PostgreSQL、AlloyDB、SQL Server、Oracle データベースからのストリーミング データへのアクセス
・BigQuery for Datastream を使用した BigQuery で、ほぼリアルタイムの分析を実現
・安全性の高い組み込み接続が利用できる使いやすい設定で、価値創出までの時間を短縮
・自動スケーリングに対応したサーバーレス プラットフォーム。プロビジョニングや管理のためのリソースも必要ありません。
・ソース データベースの負荷と中断の可能性を軽減するログベースのメカニズム
ざっくりとした説明ですが、RDBMS上のテーブル等で発生した差分をストリーミング形式で、BigQueryかCloudStorageに格納できる便利なサービスです。
利用料金について
Datastreamの料金は主に「Backfill」と「CDC」の2つで従量課金が行われます。
- Backfill: 初回全件転送のことで、対象にしたいテーブルの現状RDBMSに格納されているすべてのデータを転送すること(初回だけでなく、任意のタイミングでBackfillを行うことも可能)
- CDC: RDBMS側で発生した変更のストリーミングで、逐次的にデータを転送すること
計算は以下のように行えます。
Total_price = Backfill + CDC
例として、以下のような環境でDatastreamを使いたいとします。
- 東京リージョン
- Backfillデータサイズ: 3TB
- CDCデータサイズ: 180GB
- $1 = ¥150
- CDC料金: $2.568/GB
- Backfill料金(500GBを超える場合): $0.514
- Backfillは使い始めの1回のみで、それ以降はCDCのみ利用
Backfill = (backfill size - 500 GB) * backfill price = (3,000 - 500) * $0.514 = $1,285 = ¥192,750
CDC = 180 GB * $2.568/GB = $462.24 = ¥69,336
Total Datastream charge = Backfill charge + CDC charge = ¥192,750 + ¥69,336 = ¥262,086
ということで、初月は¥262,086で、2ヶ月目以降は¥69,336になる計算です。
これはDatastreamを利用するリージョンやCDCで転送するデータ量で差があったり、割引されたりなどで、料金が上下するので、ぜひ利用前に試算して見てください。
利用に際しての事前検証
本番利用に際して、まずは検証を行いました。
ざっくりですが、構成は以下の通りです。
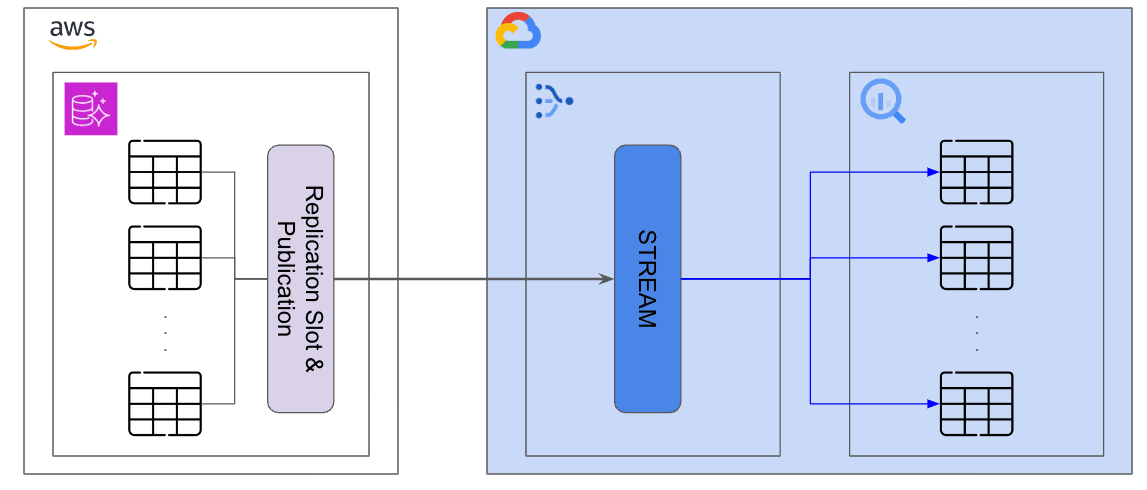
AWS Aurora PostgreSQL上にある数100あるテーブルから、DatastreamのStream(データを流す窓口)を経由してBigQueryにデータを反映させる方針です。
1点特殊な点として、PostgreSQL側にデータが積まれるのが1時間に1回のため、1時間に1回バッチでデータが載ってきたものをストリーミング方式でBigQueryに流す構成となっている点です。
検証時構成
Streamの構成はざっくり以下のような構成です。
resource "google_datastream_stream" "stream" {
display_name = "Postgres to BigQuery Stream"
location = "asia-northeast1"
stream_id = "stream_test"
desired_state = "RUNNING"
source_config {
source_connection_profile = google_datastream_connection_profile.source.id
postgresql_source_config {
publication = "pub_test"
replication_slot = "rs_test"
}
}
destination_config {
destination_connection_profile = google_datastream_connection_profile.destination.id
bigquery_destination_config {
data_freshness = "900s"
source_hierarchy_datasets {
dataset_template {
location = "asia-northeast1"
}
}
merge {}
}
}
backfill_none {}
}
設定内容をかいつまんで説明すると、
- PostgreSQL→BigQueryを想定
- 接続プロファイルは別途作成済み
- data_freshness(鮮度)はRDBMS側とBigQuery側の宛先とのデータ遅延の発生許容時間を指す。900秒であれば15分遅延が発生することを許容するという意味になる
- 今回は0秒/900秒/3600秒を検証
- backfillは行わない
- Datastream前に別の方法でデータ更新パイプラインを組んでいたので、そちらで溜めていたデータを流用し、Backfillコストを削減するようにした(Tips紹介で細かく解説します)
- backfillを行いたい場合は、
backfill_all {}としてするとできます
検証結果
パフォーマンス面
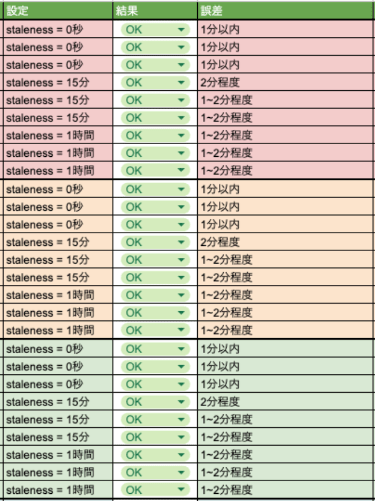
いくつかのテーブルで行なったテストですが、1時間に1回1テーブルあたり約2万 ~ 10万行の転送を行いました。
結果としては鮮度を変えても遅くとも2分以内にはRDBMSで発生した差分がBigQueryに反映されることがわかりました。
コスト面
コストも利用前の試算とほぼ一致していたため、問題はありませんでした。
検証時につまづいた点 & Tips
1. BigQueryの利用料金が膨れ上がった
Terraformの設定項目内に、merge {}とありますが、これはDatastreamがPostgreSQLから取得したデータをINSERT/UPDATE/DELETE/TRUNCATEを自動的に適用してくれるモードを選択していました。
しかし、2024年8月現在この更新ロジックはすべてBigQueryのフルスキャンによって処理が行われるそうで、例えば1TBのテーブルに対して更新をかける際は毎回1TBのスキャンがかかっていることになります。
これは宛先のBigQueryテーブルをパーティション分割テーブルとして設定していても同じでした。
下記のIssueTrackerでこの言及がなされています。
これの原因で、使い方にもよりますが、Datastreamの利用料金は10万円程度なのに、BigQueryに利用料金が数十 ~ 数百万まで膨れ上がってしまう可能性があります。
対応策としては、merge {}→append_only {}に変更し、PostgreSQL側の変更をログ形式にただ積み上げるように設定し、更新クエリを別途実行するように変更しました。
下記の図のように、Datastream経由のPostgreSQL側の変更をログ形式にただ積み上げる一時テーブルを用意し、本番用のテーブルにはMERGE INTOをスケジュール実行するパイプラインを別個で実装しています。
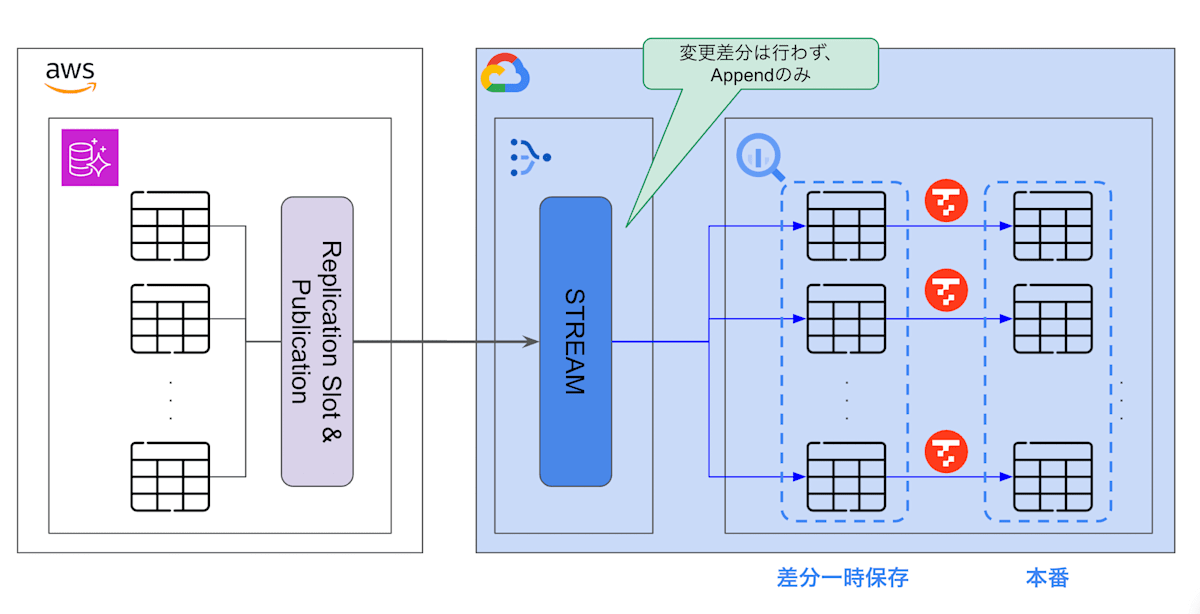
ただ注意点としては、今回は特殊なケースとして大元のPostgreSQLへの更新が1時間に1回のバッチ更新だったため、今回のユースケースが合致していますが、常にRDBMSの差分をBigQueryにパーティションによるプルーニングを効かせた状態でストリーミングしたい場合は、Dataflowなどを利用することを検討すると良いでしょう。
こちらのsatokiyoさんの記事がとてもわかりやすく参考になりました。
2. Datastreamが自動生成するテーブルにパーティション設定が入れられない
Datastream経由で自動生成するテーブルにはパーティション設定がDatastream側から入れられません。
もし入れたい場合はCREATE OR REPLACE TABLE ~ を使って、キーを設定する必要があります。
張り替えの際は、Streamを一時停止させてから行う必要があり、RDBMS側に若干の負荷がかかる可能性があるので、慎重に行いましょう。
3. Datastreamが自動生成するテーブルのカラムが変更できない
PostgreSQLに限らず、MySQLやOracleもそうなのですが、PostgreSQL側のデータ型に応じて、BigQueryの型が一意に決まってしまいます。
マッピングについては上記を参照いただきたいのですが、例えばPostgreSQL側でTIMESTAMP型の場合、BigQuery側でもTIMESTAMP型になります。ユースケースとして、BigQuery側はDATETIME型を利用したかったので、「不便だな〜」と思っていましたが、更新用のMERGE SQLでCASTを行っているため、問題にはならずに済みました。とは言えmerge {}を使う場合は、確実に固定になるので、少し不便に感じる場面があるかもしれません。
4. 対象にしたいテーブル/スキーマが多すぎるとGUIが激重になる
DatastreamはGoogleCloud側に設定画面があり、Terraformで設定している内容をGUIベースで設定できるためとても便利です。が、どのテーブル/スキーマを対象にするのかの設定を行う画面が、数千から数万のテーブルのデータベースを対象にすると表示が固まって動かなくなります。
「1つテーブル追加したいな〜」と思っても毎回タブが落ちるので、Terraformを使うかSDK経由で設定することを強く推奨します。
5. 課金対象のデータサイズについて
Datastreamでデータを連携する際、連携したデータサイズに基づいて計算が行われますが、公式ドキュメントでは以下のような記載があります。
請求額は、ソースから宛先にストリーミングされる未加工(非圧縮)のデータサイズに基づいて計算されます。Datastream では、宛先にストリーミングされるデータに対してのみ料金が発生します。
この「未加工(非圧縮)のデータサイズに基づいて計算されます。」という部分が肝で、例えばPostgreSQLであれば、元テーブルのデータの型とデータの値がそのまま圧縮等されていない状態のデータサイズを基に料金が計算されます。
内部での処理は圧縮されたデータを用いて処理している可能性はありますが、課金対象のデータサイズについてはあくまで「未加工(非圧縮)のデータサイズ」によって左右されることを認識しておく必要があります。
データサイズがどうなっているかの簡単な検証
雑な検証ですが、PostgreSQL14→BigQueryの連携を、以下のSQLを使って検証を行ってみました。
-- publicationとreplication slotの作成
CREATE PUBLICATION pub_test FOR ALL TABLES;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('rs_test', 'pgoutput');
-- 同じDDLでテーブル名が違うものを用意
CREATE TABLE public.test_tbl1 (
column001 double precision,
column002 double precision,
column003 double precision,
column004 double precision,
column005 double precision,
column006 double precision,
column007 double precision,
column008 double precision,
column009 double precision,
column010 double precision
);
CREATE TABLE public.test_tbl2 (
column001 double precision,
column002 double precision,
column003 double precision,
column004 double precision,
column005 double precision,
column006 double precision,
column007 double precision,
column008 double precision,
column009 double precision,
column010 double precision
);
-- 値あり
INSERT INTO public.test_tbl1 (column001,column002,column003,column004,column005,column006,column007,column008,column009,column010)
SELECT 1E-307, 1E-307, 1E-307, 1E-307, 1E-307, 1E-307, 1E-307, 1E-307, 1E-307, 1E-307
FROM generate_series(1, 10000);
-- 値なし(null)
INSERT INTO public.test_tbl2 (column001,column002,column003,column004,column005,column006,column007,column008,column009,column010)
SELECT null, null, null, null, null, null, null, null, null, null
FROM generate_series(1, 10000);
データ転送の結果、以下の通りでした。

連携しているのは共に10,000行であるため、各行のサイズはそれぞれ、230Byteと190Byteになります。
Double precision型は8Byteのため、理論上80Byteになるはずですが、だいぶ値がずれています。
(この結果について言及することができる知識を当方は現状持ち合わせていません、大変申し訳ないです。)
おそらくですが、Datastream内部で処理する際のparse後のデータサイズが関係しているか、PostgreSQLのReplication Slotのアウトプットのpluginに用いているpgoutputのフォーマットに依存しているのではないかと推察しています。
ちなみに、pg_logical_slot_get_binary_changesを使って中身をpeekしてみると以下のような内容でした。

6. 一時テーブルのライフサイクルについて
Datastreamの話からは若干それますが、Datastreamのモードをappend_only {}に変更したと先述しましたが、特に何もしないと一時テーブルにデータが溜まり続けてしまいます。
TROCCOのようなサービスを使っていたり、BigQueryのスケジュールクエリを設定すればDELETE文を定期的に実行して削除することも可能ですが、できれば楽したいので、パーティション有効期限を設定しています。
この設定もDatastream側からは行えないので、下記のようなクエリを実行して適用させます。
ALTER TABLE mydataset.mytable
SET OPTIONS (
-- Sets partition expiration to 2 days
partition_expiration_days = 2);
7. Backfillは必ずしも必要ない
先述の通り、別パイプラインでPostgreSQL→BigQueryの連携を行なっていたため、データ連携をDatastreamに切り替えた後にすでに連携済みのデータを再度Backfillして同じ内容を連携し直す必要があるのではないか?と当初は思っていましたが、結論から言うと不要でした。
ただ2点注意する必要があります。
1点目はDatastreamから連携されるデータはDatastreamから連携されていることを明確化するために、データセットかテーブル名に元のPostgreSQLのスキーマ名が自動的に入る仕様になっています。
そのため、特にmerge {}モードを利用する際はデータセット名かテーブル名を変更する必要があります。
2点目はDatastreamがデータ転送に用いるdatastream_metadataカラムを追加する必要がある点です。
具体的に以下のSQLを実行する必要があります。
-- merge {}の場合
ALTER TABLE mydataset.mytable ADD COLUMN datastream_metadata STRUCT<uuid STRING, source_timestamp INT64>;
-- append_only {}の場合
ALTER TABLE mydataset.mytable ADD COLUMN datastream_metadata STRUCT<uuid STRING, source_timestamp INT64, change_sequence_number STRING, change_type STRING, sort_keys ARRAY<STRING>>;
ほぼおまじないみたいなものなので、細かい説明は省きますが、PostgreSQL側のlsnを同期して保持している形です。
検証 + 本番適用を通じて感じたDatastreamの良さ
パフォーマンスとコストのバランスが完璧
現状、過去7日間でRDBMSで発生した変更イベントが1億件近くありましたが、エラーも発生せず、平均(P50)だけ見たら1秒程度で処理が完了するようになっています。
上でも記載しましたが、Stalenessやスループットを含めたパフォーマンスが運用に耐えうるサービスでありながら、コスト感が跳ね上がっている印象を持たず、現実的な点が率直にとても良いと感じました。
設定が直感的
Terraformの設定内容から伺えますが、転送元と転送先、データの流れ方を定義するだけですぐに始められる点がとても良いなと感じました。
特に今回PostgreSQLを利用する際には、PostgreSQLのCDCの枠組みを活用してDatastreamに転用している形ですが、PostgreSQLの深い知識がなかったとしても設定を行うだけで動作し、PostgreSQLの環境に過度な負荷をかけないようになっている点もとても良いなと感じています。
メンテナンス・モニタリングの容易性
Datastreamのメンテナンス面では、どのテーブルを対象にするのかの設定が簡単であったり、Backfillをやり直すのがボタン1つでできるなど、設定の変更がとにかく簡単です。
またTerraformでの設定やSDKによる設定も行うことができるため、コード管理も可能です。
モニタリングの面では、いつどのテーブルに対して何行連携したか、どこで失敗したかをログエクスプローラで確認することができます。また、直近のデータ連携のスループット、Stalenessの統計情報、システム全体の遅延具合も確認することができ、Google Cloudのアラートポリシーを用いて通知設定を作成することもできるので、何らかの理由でデータ連携が遅延し始めている際に通知を行うことが可能です。
最後に
様々な観点から検証を行い、色々失敗しましたが、先述の通りDatastream自体は良いサービスでとても直感的に使いやすいな〜と率直に思いました。現在はSnowflakeにもPostgreSQLとMySQL向けにCDC Connectorが発表されたりとホットな領域なので、様々なソリューションを選択できる良い時代ですね。
これからもデータエンジニアリングに関する情報を発信していくので、これまでの記事も含めてよろしくおねがいいたします!

Discussion
非常に参考になる内容でした!ありがとうございます!
一点、自分の理解と異なる部分があって、
とのことですが、これってstalenessをdatastreamの設定から変更していますか??
自分の理解だと、stalenessはdatastreamで転送設定を一度作成すると、以降変更するときは転送先のテーブル側で変更かけないといけないと思っていて、もし検証の前提が違いそうであれば、テーブル側でstalenessを変更して鮮度がどう変わるか確認できるといいかも、と思いました!
参考までに自分が調べた時の情報を貼っておきます。