はじめに
お世話になっております。primeNumberの庵原です!
この記事ではSnowflake Summit 2025のDay2でのセッション"Secure, Exabyte-Scale Lakehouse Analytics at Netflix with Iceberg and Snowflake"で発表された内容や様子について現地で見たもの聞いたものを速報形式でまとめてお送りいたします!
セッション内容
目玉ポイント
- Iceberg REST Catalog(IRC)× Snowflake 外部 Iceberg テーブルにより、1 EB超の S3 上データをコピーせずに Snowflake から直接クエリ
- 単一のソース・オブ・トゥルースを実現:Spark/Trino/Snowflake など複数エンジンが同じカタログとデータを共有
- パフォーマンス検証でネイティブ表と同等──外部 Iceberg 参照でもクエリ速度に有意差なし
- SCIM+ロール同期で行・列レベルまで権限制御を自動反映し、社内 RBAC を Snowflake に統合
- S3 STS トークンを動的払い出しする vended-credential 方式で、バケット権限の手動設定を排除
- 複数リージョン/複数 S3 バケットを単一 Iceberg テーブルとして公開し、Flink ストリーミング取り込みにも対応
- Snowflake Catalog Linked Database(プレビュー)で IRC 上のテーブルを “ローカルと同じ感覚” で発見・リフレッシュ可能
- OSS への共同貢献:Apache Polaris規格策定、ACL/RLS/CLS を IRC スペックに組み込み、データクリーンルーム要件も視野
スライドについて
Entertain the World & Data-Driven Decisions


Netflixは“まずエンタメ企業”ですが、ほぼ裏側の全決定がデータドリブンになっているそうで、UI・パーソナライズやインフラ最適化までアルゴリズムが裏で判断されているようです。
Netflix Analytics Platform Architecture
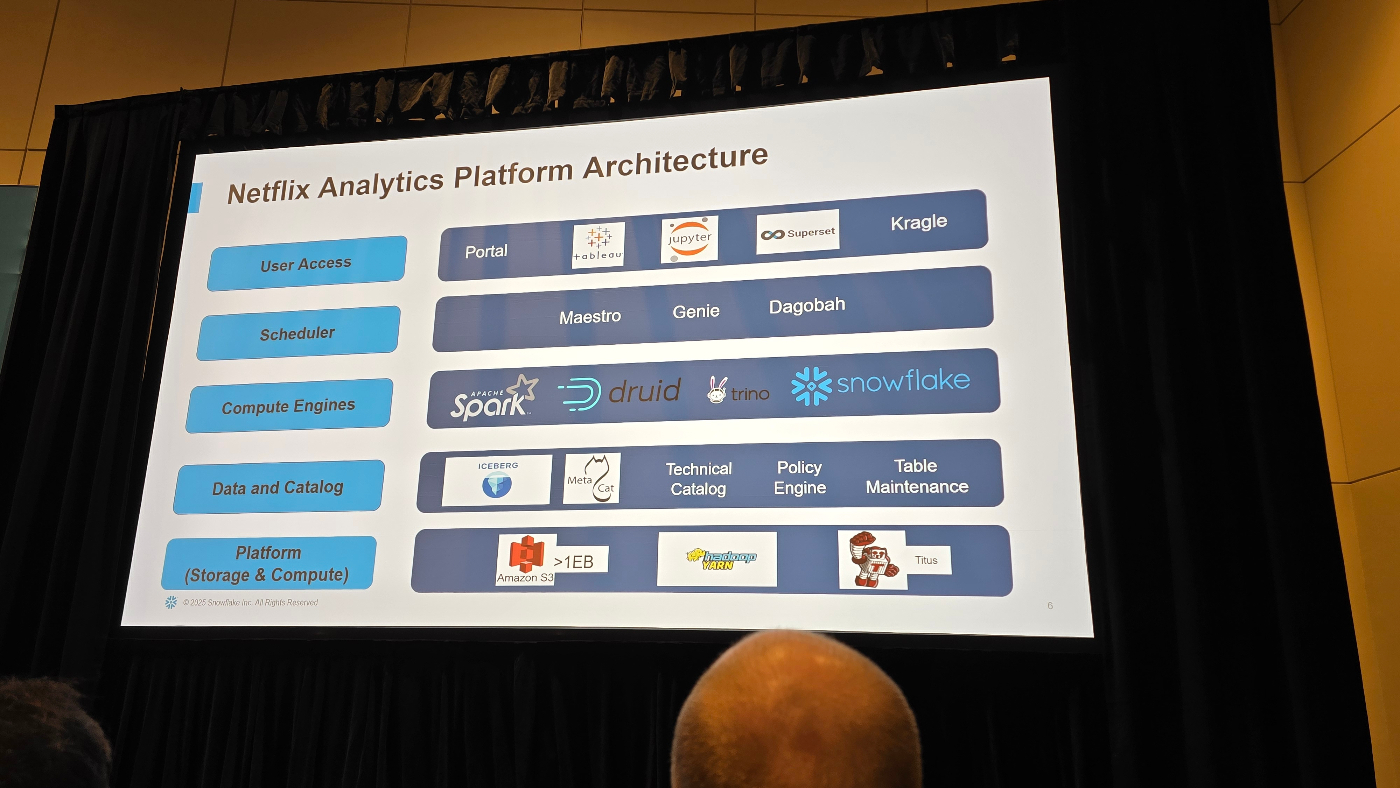
Netflixのアナリティクス基盤は、Iceberg を唯一のストレージ形式として “コピーゼロでマルチエンジン”を実現する5層構造。
- Storage: Amazon S3 に >1 EB の Iceberg。バージョン管理・タイムトラベルを全エンジンで共有。
- Catalog: 自社 MetaCat + Iceberg REST Catalog が単一メタストア。行/列レベル権限やメンテナンスもここで自動化。
- Compute: Spark(ETL/ML)、Trino(Ad-hoc)、Druid(即時集計)、Snowflake(セキュア分析)が同じテーブルを直接クエリ。
- Orchestration: Maestro/Genie などがジョブを管理し、SLA や依存関係をカタログと連動。
- Access: Tableau・Jupyter ほか任意ツールから“エンジン意識ゼロ”で利用。
ポイントとして、単一ソース・オブ・トゥルースでコピー不要、Snowflake も外部 Iceberg テーブルを即読込し、SCIM同期とGit管理ポリシーで権限とガバナンスを自動反映しており、Exabyteデータでも既にA/Bテストやレコメンドに本番適用されているようです。
Snowflake Use Cases

SnowflakeはNetflix内でもとりわけ機密度の高いデータ領域(財務・人事・契約関連など)を担う“セキュア分析ハブ”として位置づけられているそうです。
Iceberg上の原本をコピーせずに外部テーブルとして直読できるため、EB級データを即時に参照しながらも、行・列レベルのポリシーを自動同期して機密情報を漏らさないようになっています。
さらに、Looker的なセマンティックレイヤをSnowflake側に集約し、ビジネス指標(ARPUや広告ROIなど)を単一定義で提供しています。これにより従来のオンプレ BI や部門ごとのデータマートを段階的にリプレースしながら、コスト最適化とガバナンス強化を同時に実現できています。
Pain Points of Current Architecture

旧構成ではIcebergデータをSnowflakeに日次でコピーし直す必要があり、二重のソース・オブ・トゥルースが常態化してしまっていたそうで、Snowflake側の表はすぐ陳腐化し、型変換ミスも頻発していたそうです。
さらに、MetaCatとSnowflakeのメタストアが二重化したことで BYOE(Spark/Trino併用)のガバナンスが破綻し、どのエンジンが最新版かを常に確認する羽目になっており、加えてSnowflakeへのデータ投入にIAMやバケットACLの手動調整が不可欠で、クライアント側のアップグレード作業も厚く、運用コストとリスクが指数関数的に増大していたとのことです。
(ここら辺の運用コストえぐそうだな...と聞いてて思いました。)
Solution : Iceberg REST Catalog

Iceberg REST Catalogを導入することで、Snowflakeを含む複数エンジンが同じ Iceberg メタデータとストレージを直接参照できるようになります。
これによりデータコピーや型変換が不要となり、最新データをリアルタイムで分析できる単一のソース・オブ・トゥルースを実現します。
また、カタログ側から動的に STS トークンを払い出すため、手動でのバケット権限設定を行わずに安全なアクセス管理が可能になります。さらに、テーブルの発見やリフレッシュも「Catalog Linked Database」で自動化され、運用負荷を大幅に削減できます。
ちなみにCatalog Linked Databaseは、外部Iceberg REST Catalog と Snowflakeの“カタログ統合(CATALOG INTEGRATION)” を1つのSnowflakeデータベースとしてマウントする仕組みです。従来はSYSTEM$LIST_ICEBERG_TABLES_FROM_CATALOGなどでテーブル名を列挙し、個別に CREATE EXTERNAL TABLE … CATALOGを発行していましたが、Linked Databaseを使うと自動的にカタログ情報を統合し、異なる場所に格納されているIcebergテーブルが単一のデータベースとして閲覧することができます。
Unlocking Opportunity Through Change

Catalog Linked Databaseを含めた新構成ではIceberg REST Catalogと外部Icebergテーブルを採用したことで、コピーゼロの単一ソース・オブ・トゥルースが実現できるようになったそうです。Spark/Trino/Snowflakeなど全エンジンが同じメタデータをリアルタイムに参照できるため、A/Bテストやレコメンド解析を最新データで即回せるようになり、部門横断のデータ共有も一気に加速したと強調していました。
また、カタログ側から動的に STS トークンを払い出す仕組みにより、IAM やバケット ACL の手作業が不要になり、運用負荷が劇的に低減したとも述べていました。さらに、Linked DatabaseによってIceberg側で新設されたテーブルがSnowflakeに自動で現れるため、オンボーディング作業が数分で完結し、BYOEのハードルも大幅に下がったそうです。
Netflix規模での運用負荷で現れるpainの解消の重みがすごいですね。
Snowflake Externally Managed Iceberg Tables

Snowflake Externally Managed Iceberg Tables のスライドでは、社内 MetaCatのコミットイベントを受け取るSyncing ServiceがIcebergテーブルを Snowflakeに自動登録し、メタデータ更新を即時ミラーリングする仕組みが紹介されていました。
データ本体は Netflixの社内Warehouseに留まり、ユーザーは“テーブルをopt-inするだけ”でコピーなしに参照を開始できるため、ETLジョブや型変換の設定を一切せずに済む点がメリットとされています。
またイベント駆動方式によりSnowflake側の定義も瞬時に追随するため、最新スナップショットを使った分析が可能になる、というのが強調ポイントでした。
ACLs & FGAC

Netflixがユーザー/権限の同期と行・列レベル制御を完全自動化しているポイントが語られていました。まずSCIM連携で全ユーザーをSnowflake側にも同期し、個人ごとのシングルトンロールを自動生成すると同時に、社内グループ階層をそのままロール階層として取り込み、Icebergで定義されているテーブル権限を“ミラー”する形で付与するため、ユーザーは申請なしで即座に必要データへアクセスできるそうです。
次に FGAC(Fine-Grained Access Controls)では、個人に応じた 行レベル・列レベルセキュリティ(RLS/CLS)を適用し、定義ファイルはGitで管理し、CIパイプライン経由でJSON → CREATE MASKING POLICYに変換して、アンマネージド Icebergテーブル上のビューに一括適用する仕組みを採用しています。これにより利用者には摩擦を与えず、監査チームには変更履歴をフルで提示できる運用が可能になった、というのが強調ポイントでした。
Pain Points with Externally Managed Tables

コピーを排したものの、メタデータをSnowflakeに複写する疑似二重管理が残るため、真の単一ソース・オブ・トゥルースには到達できず、Netflixのカタログ戦略と齟齬が生じたと説明していました。
リフレッシュ間隔次第では利用者に古いデータが提供される恐れもあり、エンジニアは常に“どの時点が最新版か”を意識する必要があったそうです。
さらに運用面では、バケットごとにアクセス権を手動で開放し、テーブル登録・メタデータ更新・ACL 同期を行うツール群を維持管理し続ける負荷が重く、スライドでは 「戦略的欠陥」「ユーザー体験の劣化」「運用コストの膨張」の3観点で課題を整理していました。
Netflix IRC / Snowflake Integration
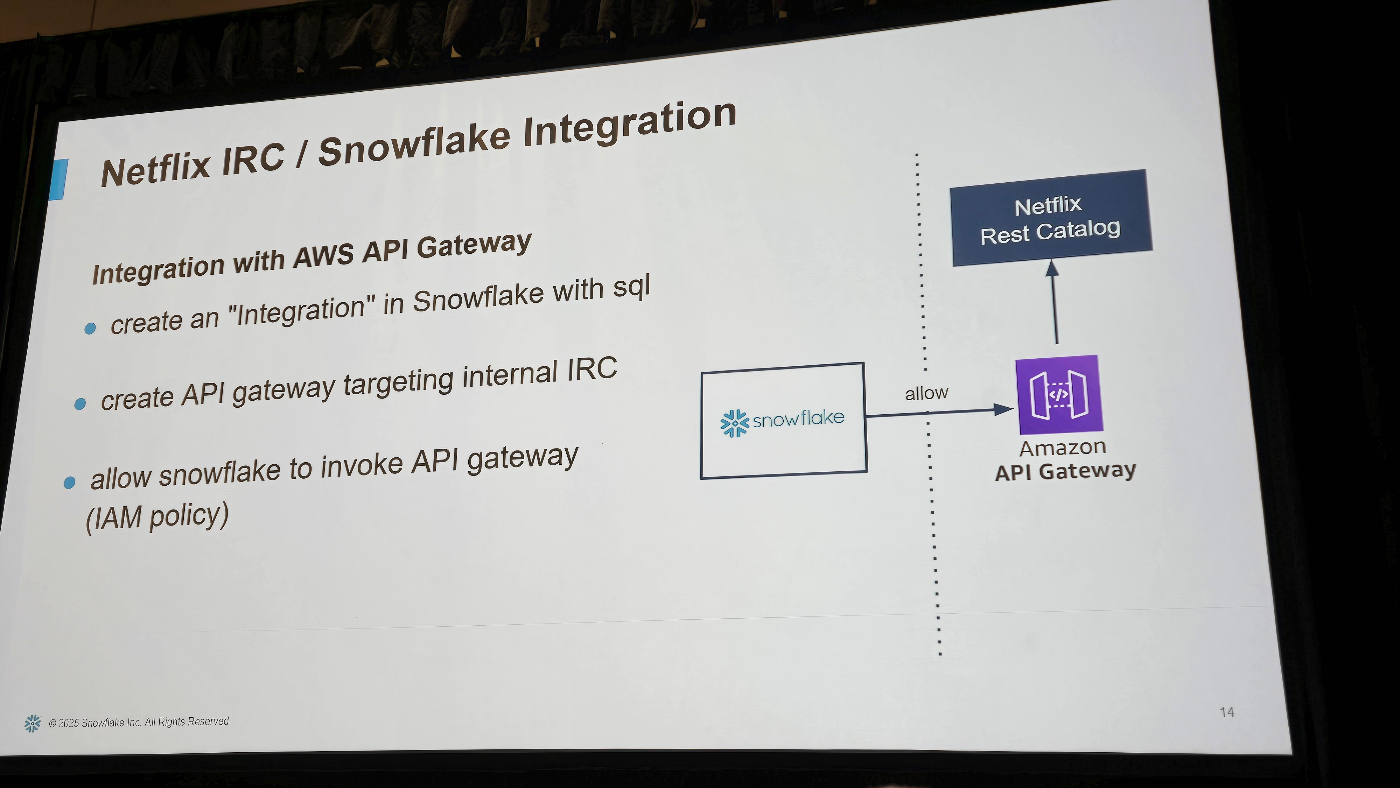
スライドでは、AWS API Gatewayを仲介してSnowflakeと社内 Iceberg REST Catalog(IRC)を接続する3ステップが示されていました。
-
Snowflake 側で CREATE API INTEGRATION … を実行
SQL だけで外部 HTTP エンドポイントを呼び出す統合オブジェクトを定義し、接続管理をプラットフォーム内に閉じ込めます。 -
社内 IRC をターゲットにしたAPI Gatewayを作成
内部ドメインを直接公開せず、IAM/WAF で保護したエッジサービス経由で IcebergメタデータAPIを提供。 -
IAM ポリシーでSnowflakeに呼び出し権限を付与
Snowflakeの実行ロールにexecute-api:Invokeを許可するだけで、カタログ操作(DISCOVER/REFRESH など)の呼び出しが可能になります。
図では Snowflake → API Gateway → Netflix Rest Catalog というシンプルな経路を示し、最小権限・エンドポイント秘匿・クロスアカウントでも共通化できる構成である点が強調されていました。
IRC Integration: Vended Credentials

Iceberg REST CatalogがテーブルごとのS3プレフィクスに限定した短命STSトークンをSnowflakeへ動的に払い出す方式が説明されていました。Snowflakeはクエリ実行時だけこのトークンを用いてオブジェクトストレージを読み取るため、IAMポリシーやバケットACLを人手で調整する必要がなくなり、最小権限アクセスと運用レスを同時に実現できた点が強調されています。
IRC Integration: Multiple-Locations

マルチリージョンで取り込まれたIcebergテーブルを1つの論理テーブルとして Snowflakeに公開する仕組みを紹介していました。
具体的にはApache Flinkが各リージョン(例:us-east-1とus-west-2)のS3バケットへ同じIcebergテーブルのパーティションを書き込み、Netflix IRCがその “table-locations”一覧をSnowflakeに返却し、Snowflake側は複数バケット読み取りをネイティブでサポートするため、ユーザーはリージョン差分を意識せず単一テーブルとしてクエリできる、という協働成果が強調されていました。
IRC Integration: Table Discovery

Snowflake Catalog Linked Databaseを使い、NetflixのIceberg REST Catalogにあるテーブルを“ローカル DB と同じ感覚”で扱えるようになる点が示されました。
SnowflakeはDISCOVER/REFRESHコールでリモート・カタログをポーリングし、新規テーブルやスキーマ変更を自動反映したうえで、利用者には通常のSELECT * FROM linked_db.schema.tableという形で公開します。
これによりオンボーディングは数分で完結し、コピーや個別CREATE EXTERNAL TABLE を省いた完全自動のテーブル発見とメタデータ同期が実現できることが強調されていました。
Conclusion

IRCは複数エンジンをまたいだ単一カタログとしてアナリティクス基盤を大幅にシンプル化する決定打であり、SnowflakeはApache Polaris仕様をいち早く実装する先行ベンダーだと位置づけています。そのうえでNetflixはSnowflakeと連携し、マルチバケット対応・ACLの仕様化・行/列レベルアクセス制御の標準化といった拡張機能をOSSに取り込むロードマップを提示し、最終的なユースケースとしては、米国・海外のデータクリーンルームまで視野に入れ、IRCを核としたオープンなレイクハウス・エコシステムを共同で育てていく方針を強調していました。
箇条書き
- Iceberg REST Catalog (IRC) が業界標準へ収束
- 分析基盤を大幅に簡素化
- 単一カタログでマルチエンジンを統合
- SnowflakeはIRCを先行実装した主要ベンダー(Apache Polaris にも準拠)
- Netflix × SnowflakeでOSS仕様を共同拡張
- 複数テーブルロケーション対応
- ACLをIRC公式仕様へ組み込み
- 行・列レベルアクセス制御(RLS/CLS)の標準化
- データクリーンルーム(米国・海外)を次の主要ユースケースに据える
まとめ
いかがでしたでしょうか?
Nexflixの規模ならではの運用負荷やメタデータ管理の複雑性をIceberg Rest Catalogを用いて解決する革新的なソリューションを事例として垣間見れただけでもSummit来てよかった...となっています笑
引き続き参加したSessionの内容等をアップしますので、是非そちらもご覧いただけますと幸いです!

Discussion