この記事は trocco® Advent Calendar 2023 14日目の記事です。
やったこと
エンジニアの活動の振り返りができるように、Pull Requestのマージ状況やFour Keysを観測できるダッシュボードを作成しました。
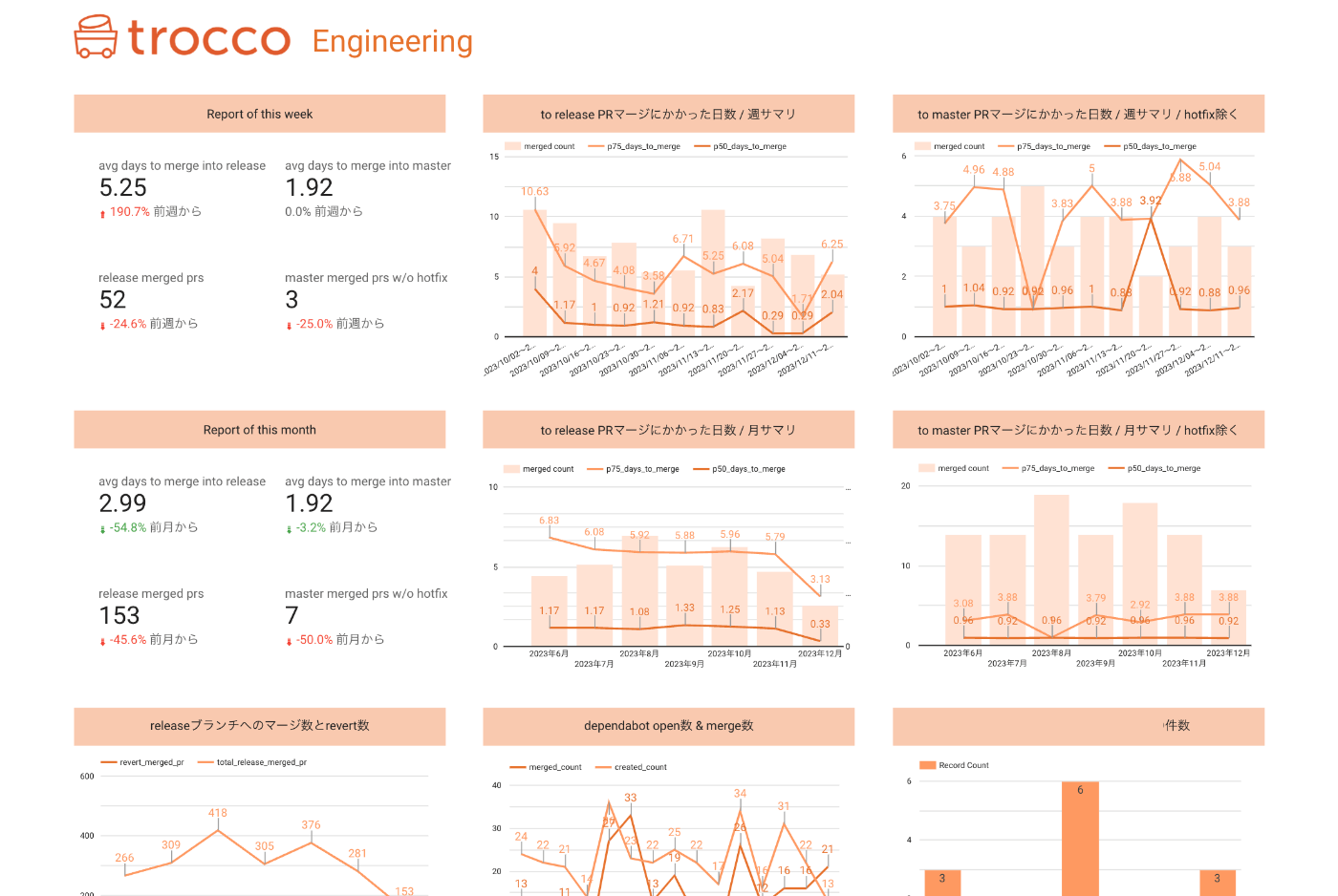
計測項目としては、
- 検証環境用ブランチへのPull RequestのOpenからMergeまでにかかった時間
- 本番環境用ブランチへのPull RequestのOpenからMergeまでにかかった時間
- Revert数
- インシデント数(スプレッドシートで管理のデータソースを利用)
- MTTR(スプレッドシートで管理のデータソースを利用)
- Dependabot Pull Requestのマージ状況
などが含まれます。
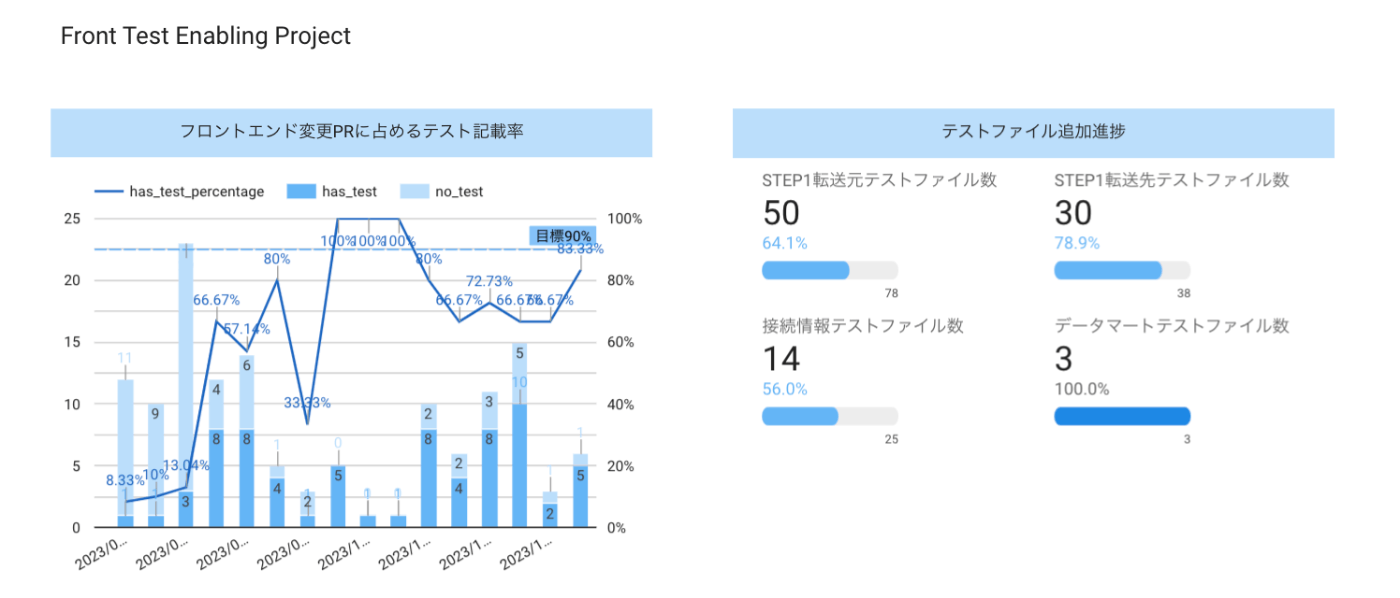
また、フロントエンドテストを書く文化を醸成するプロジェクト[1]のKPIウォッチングのため、テストの記載状況を観測できるようにしました。
使ったもの
- trocco®のGitHub GraphQL APIコネクタ
- trocco®のdbtジョブ
- trocco®のワークフロー
- Google BigQuery
- Looker Studio
trocco®のGitHub GraphQL APIコネクタ
https://docs.github.com/ja/graphql 専用のデータ転送コネクタです。
GitHubからPull Request情報やファイル情報、レビュー情報を取得するために利用しました。
単にAPIを叩いてそれを加工するには一手間必要になってくるのですが、troccoの以下の機能を活用することで特別なことをせずにデータを利用しやすい形で転送することができます。
- ページネーション機能
- JSONカラム展開
- プログラミングETL
まずはじめにGraphQLのクエリを書く際に、ページネーション機能を利用し、カーソルを用いてGitHubのPull Request情報やファイル情報を取得します。
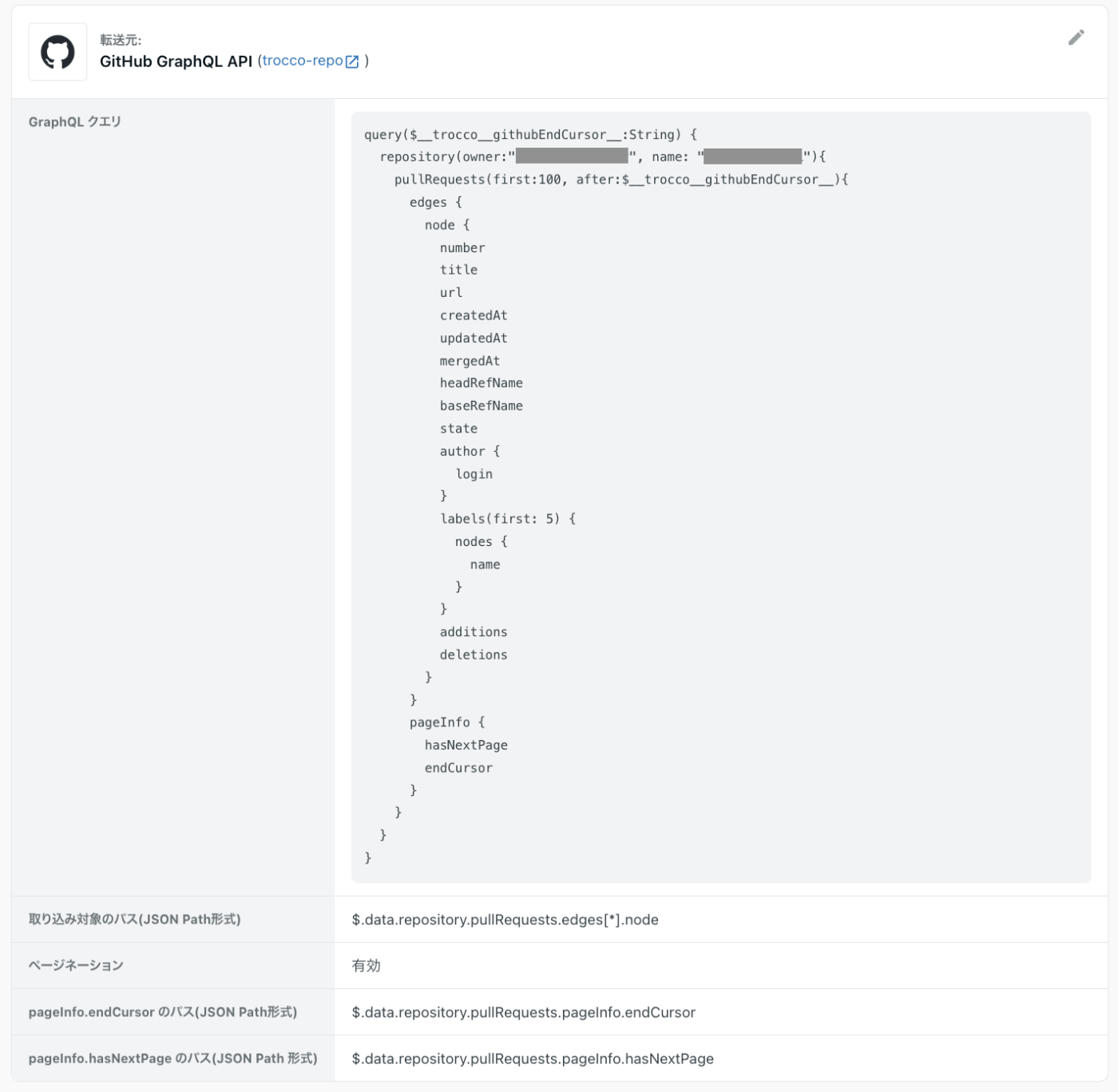
APIのレスポンスにはPR番号やタイトル、マージ日時といった結果がJSONで1カラムに集約された状態で含まれるので、JSONカラムの展開(一階層まで可能)で、別々のカラムに分割します。
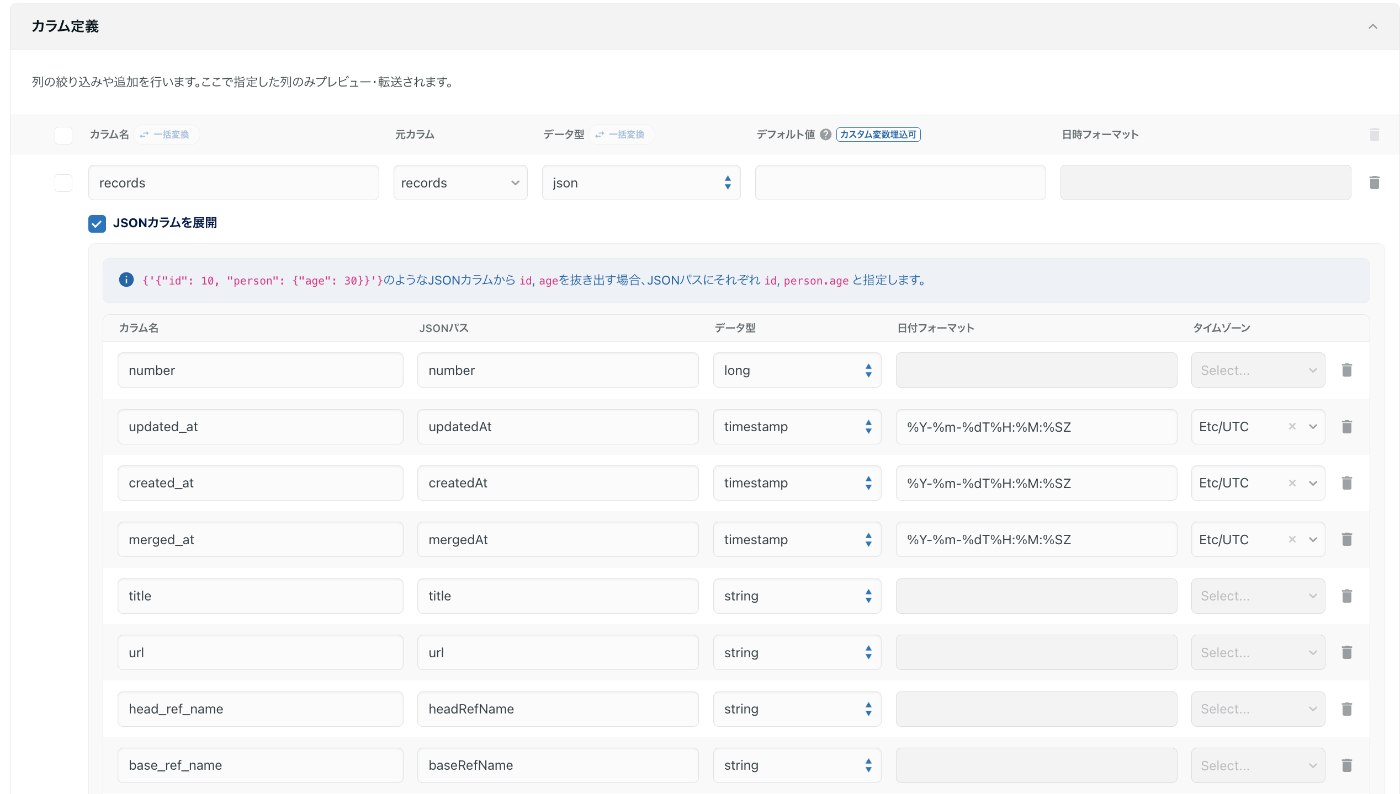
さらにネストしたJSONカラムを展開するために、プログラミングETLを用います。
例えばJSONカラムに入っている配列の情報のうち1つ目だけを抽出したい、といったケースでは
# reviewsのJSONから特定の情報を抽出したい
[
{
"title": "Advanced Settingのseed作成",
"number": 11,
"reviews": "{\"nodes\":[{\"createdAt\":\"2018-07-23T09:24:25Z\"}]}",
"merged_at": "2018-07-24 03:54:23 +0000",
"created_at": "2018-07-20 07:48:21 +0000"
},
]
以下のような簡単なコードを書いて加工を行うことで、必要な情報のみを抽出することができます。
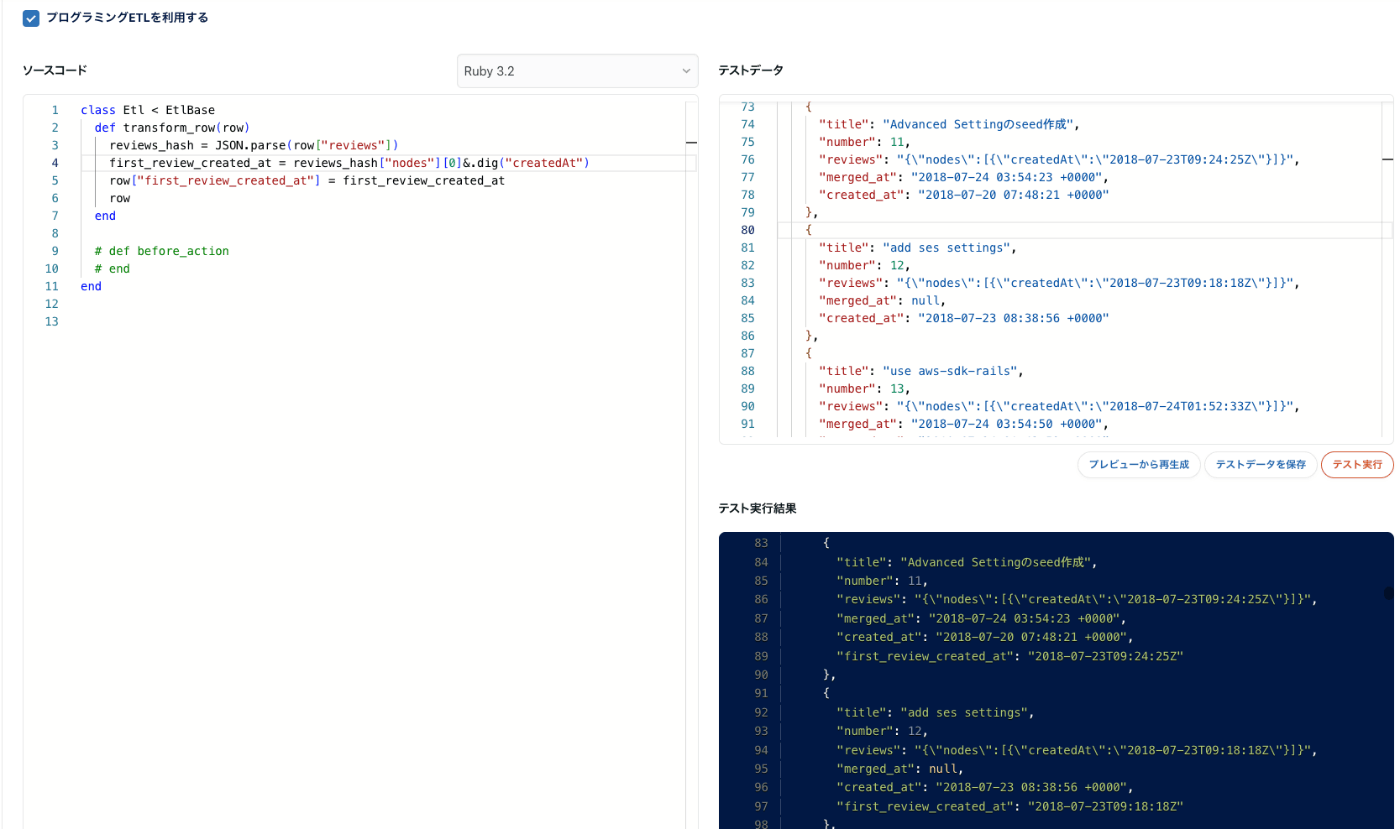
# first_review_created_at を新規に追加
[
{
"title": "Advanced Settingのseed作成",
"number": 11,
"reviews": "{\"nodes\":[{\"createdAt\":\"2018-07-23T09:24:25Z\"}]}",
"merged_at": "2018-07-24 03:54:23 +0000",
"created_at": "2018-07-20 07:48:21 +0000",
"first_review_created_at": "2018-07-23T09:24:25Z"
},
]
trocco®のdbtジョブ
転送ジョブで転送したテーブルに含まれるデータに対し、Looker Studioの方で集計・分析する際に複雑な条件を書かずに済むように、さらなるデータの加工を行いました。
trocco®データマート機能でも対応可能ですが、今回はGit管理が可能なdbtジョブを利用しました。
例: PRに紐づくファイルの一覧をJSONから展開してBQの別テーブルに保存する
WITH json_data AS (
SELECT
`number` AS pr_number,
files AS files_json
FROM
`project.dataset.github_release_merged_pull_request_with_files`
),
edges AS (
SELECT
pr_number,
JSON_EXTRACT_ARRAY(files_json, '$.edges') AS edges
FROM
json_data
),
nodes AS (
SELECT
pr_number,
JSON_EXTRACT_SCALAR(edge, '$.node.path') AS file_path,
CAST(JSON_EXTRACT_SCALAR(edge, '$.node.additions') AS INT64) AS additions,
CAST(JSON_EXTRACT_SCALAR(edge, '$.node.deletions') AS INT64) AS deletions
FROM
edges,
UNNEST(edges.edges) AS edge
)
SELECT
pr_number,
file_path,
additions,
deletions
FROM
nodes
例がJSON展開ばかりになってしまいましたが、他にもLooker Studioでは難しい集計処理をSQLで行なっています。
trocco®のワークフロー
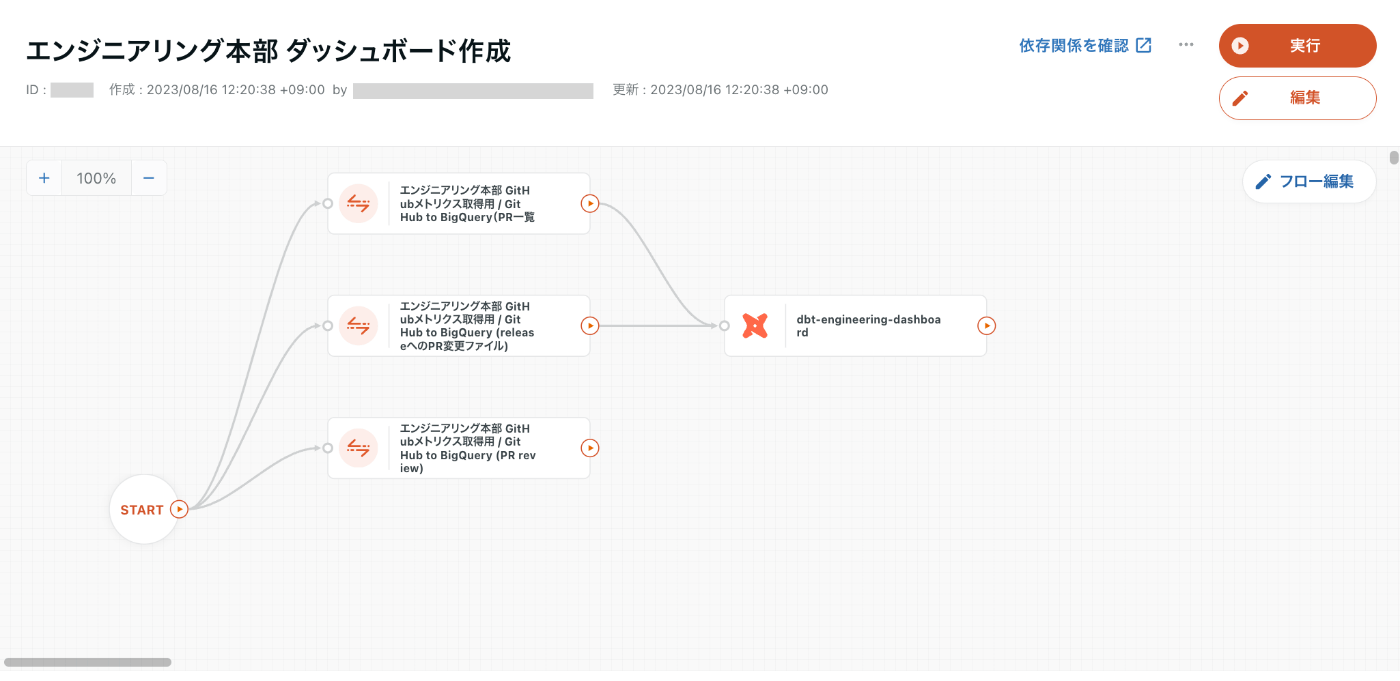
GitHub → BigQueryへの転送ジョブとdbtジョブの依存関係を定義してスケジュールします。UIで簡単に設定できて便利。
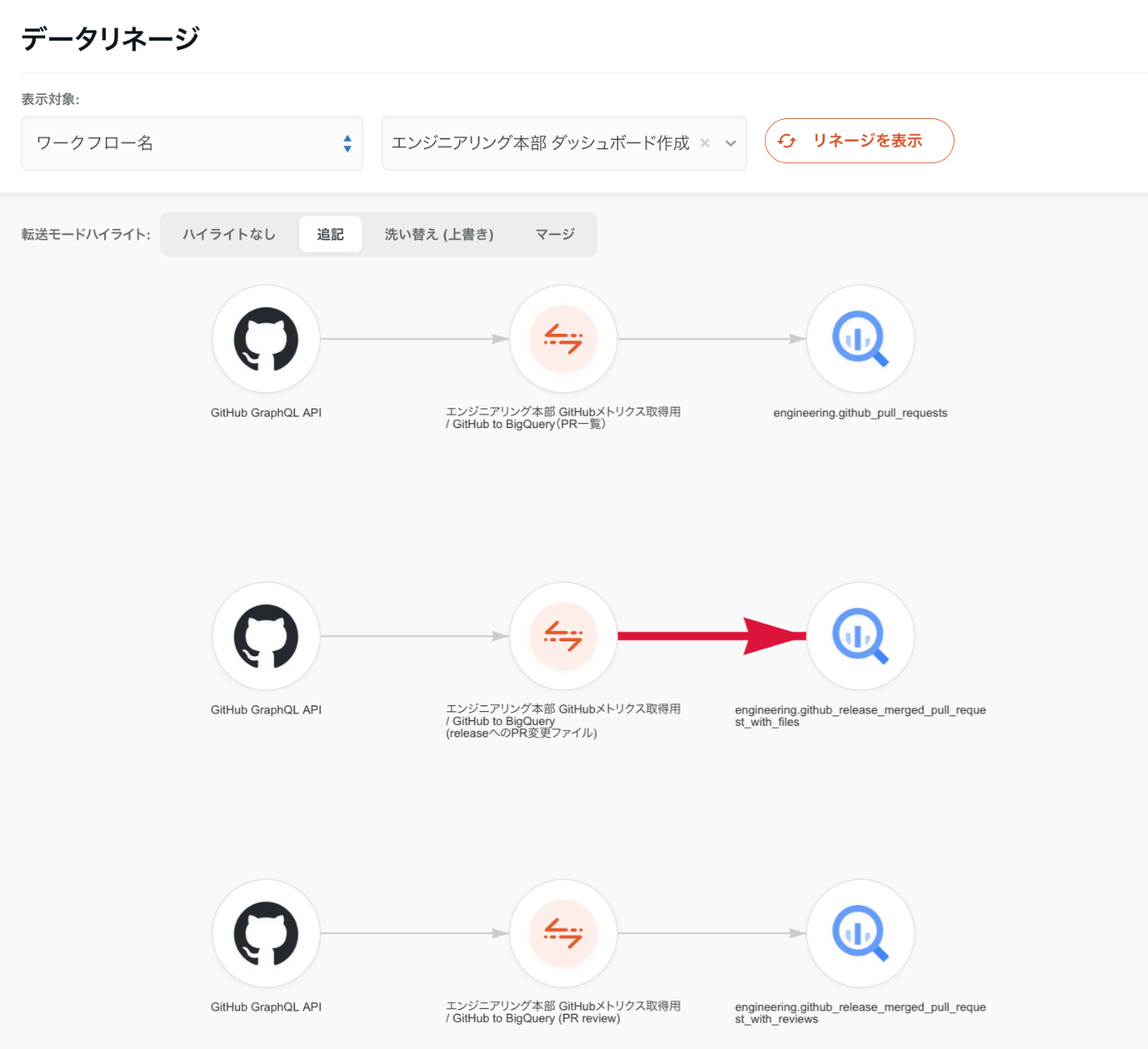
ワークフローを設定するとデータリネージ機能でBigQueryに作成されるテーブル名を確認することができたりします。dbtジョブのリネージは現在未対応ですが、いつか見れるようにしたい...!
Looker Studio
社内のデータ分析で使われているため利用。特別な設定はしていないため、ここでは割愛します。
まとめ
いかがでしたでしょうか? trocco® を使うことで簡単にデータの転送から加工までできました 🙌
現在は毎週エンジニアが集まる定例MTGがあるので、その中で時間を取ってダッシュボードを見ながら振り返りを行なっています。最近はSREエンジニアが作成したSLOに関する項目のウォッチングも一緒に行なっています。
理想的には目標を決めた上でパフォーマンスを計測した方がいいのと、まだまだインサイトが得られやすい集計方法が確立されていないので、徐々に運用は改善していきたいです。続編をお待ちください!

Discussion