Open1
Stable Diffusion v1, v2 の Attention について
Stable Diffusion v1 系列のモデル.
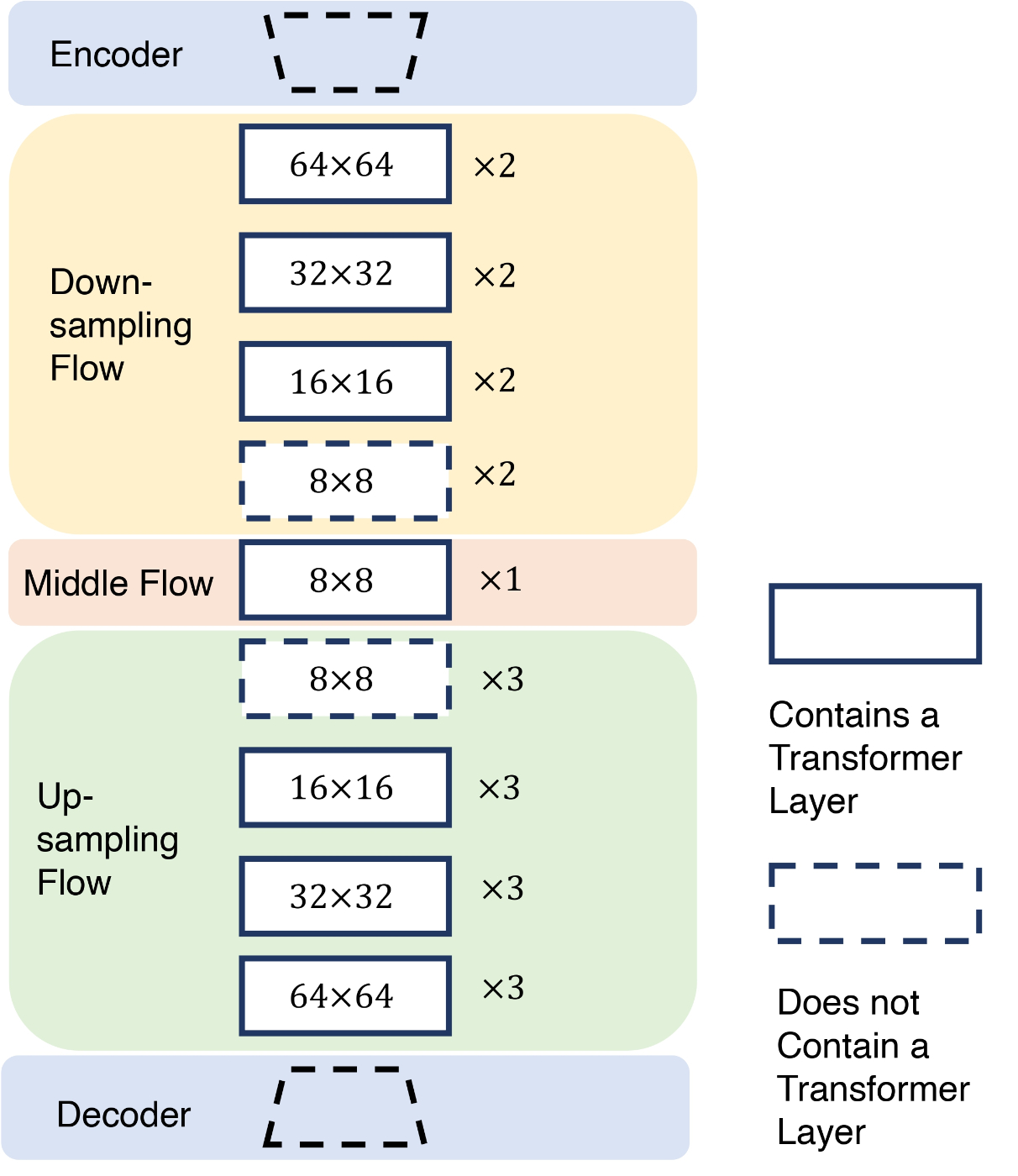
U-Net 内の Attention ブロックについての概要 (DiffSeg[1] より引用)
U-Net の Attention
U-Net 内を通る Latent Scale と index の関係
| Scale | Indices |
|---|---|
| 64 | [1, 2, 14, 15, 16] |
| 32 | [3, 4, 11, 12, 13] |
| 16 | [5, 6, 8, 9, 10] |
| 8 | [7] |
Self/Cross Attention の違い
| Query | Key | Value | |
|---|---|---|---|
| Self | Latent 画像特徴 | Latent 画像特徴 | Latent 画像特徴 |
| Cross | Latent 画像特徴 | 外部条件特徴(e.g. テキスト埋め込み) | 外部条件特徴 |
Self-Attention のテンソル形状
各バッチ次元の 16 (=2x8) は Classifier-free guidance による x2 と、Multi-head Attention による x8.
| Index | Query Shape | Key Shape | Value Shape | Attention Probability Shape |
|---|---|---|---|---|
| 1 | (16, 4096, 40) | (16, 4096, 40) | (16, 4096, 40) | (16, 4096, 4096) |
| 2 | (16, 4096, 40) | (16, 4096, 40) | (16, 4096, 40) | (16, 4096, 4096) |
| 3 | (16, 1024, 80) | (16, 1024, 80) | (16, 1024, 80) | (16, 1024, 1024) |
| 4 | (16, 1024, 80) | (16, 1024, 80) | (16, 1024, 80) | (16, 1024, 1024) |
| 5 | (16, 256, 160) | (16, 256, 160) | (16, 256, 160) | (16, 256, 256) |
| 6 | (16, 256, 160) | (16, 256, 160) | (16, 256, 160) | (16, 256, 256) |
| 7 | (16, 64, 160) | (16, 64, 160) | (16, 64, 160) | (16, 64, 64) |
| 8 | (16, 256, 160) | (16, 256, 160) | (16, 256, 160) | (16, 256, 256) |
| 9 | (16, 256, 160) | (16, 256, 160) | (16, 256, 160) | (16, 256, 256) |
| 10 | (16, 256, 160) | (16, 256, 160) | (16, 256, 160) | (16, 256, 256) |
| 11 | (16, 1024, 80) | (16, 1024, 80) | (16, 1024, 80) | (16, 1024, 1024) |
| 12 | (16, 1024, 80) | (16, 1024, 80) | (16, 1024, 80) | (16, 1024, 1024) |
| 13 | (16, 1024, 80) | (16, 1024, 80) | (16, 1024, 80) | (16, 1024, 1024) |
| 14 | (16, 4096, 40) | (16, 4096, 40) | (16, 4096, 40) | (16, 4096, 4096) |
| 15 | (16, 4096, 40) | (16, 4096, 40) | (16, 4096, 40) | (16, 4096, 4096) |
| 16 | (16, 4096, 40) | (16, 4096, 40) | (16, 4096, 40) | (16, 4096, 4096) |
Cross-Attention のテンソル形状
各バッチ次元の 16 (=2x8) は Classifier-free guidance による x2 と、Multi-head Attention による x8.
| Index | Query Shape | Key Shape | Value Shape | Attention Probability Shape |
|---|---|---|---|---|
| 1 | (16, 4096, 40) | (16, 77, 40) | (16, 77, 40) | (16, 4096, 77) |
| 2 | (16, 4096, 40) | (16, 77, 40) | (16, 77, 40) | (16, 4096, 77) |
| 3 | (16, 1024, 80) | (16, 77, 80) | (16, 77, 80) | (16, 1024, 77) |
| 4 | (16, 1024, 80) | (16, 77, 80) | (16, 77, 80) | (16, 1024, 77) |
| 5 | (16, 256, 160) | (16, 77, 160) | (16, 77, 160) | (16, 256, 77) |
| 6 | (16, 256, 160) | (16, 77, 160) | (16, 77, 160) | (16, 256, 77) |
| 7 | (16, 64, 160) | (16, 77, 160) | (16, 77, 160) | (16, 64, 77) |
| 8 | (16, 256, 160) | (16, 77, 160) | (16, 77, 160) | (16, 256, 77) |
| 9 | (16, 256, 160) | (16, 77, 160) | (16, 77, 160) | (16, 256, 77) |
| 10 | (16, 256, 160) | (16, 77, 160) | (16, 77, 160) | (16, 256, 77) |
| 11 | (16, 1024, 80) | (16, 77, 80) | (16, 77, 80) | (16, 1024, 77) |
| 12 | (16, 1024, 80) | (16, 77, 80) | (16, 77, 80) | (16, 1024, 77) |
| 13 | (16, 1024, 80) | (16, 77, 80) | (16, 77, 80) | (16, 1024, 77) |
| 14 | (16, 4096, 40) | (16, 77, 40) | (16, 77, 40) | (16, 4096, 77) |
| 15 | (16, 4096, 40) | (16, 77, 40) | (16, 77, 40) | (16, 4096, 77) |
| 16 | (16, 4096, 40) | (16, 77, 40) | (16, 77, 40) | (16, 4096, 77) |
Attention Probability の計算
上の表の Attention Probability は以下のように計算されている.
diffusers の AttnProcessor だと、次の関数で計算している.
-
Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion, Junjiao Tian, Lavisha Aggarwal, Andrea Colaco, Zsolt Kira, Mar Gonzalez-Franco, CVPR2024 ↩︎