LogitsProcessorZoo で LLM の出力をコントロールする
LLMに質問した際に、期待した出力の形式とは異なる応答を得たり事実とは異なる情報を返されたりしたことはないでしょうか。この記事では、そんな時に使える便利なライブラリ logits-processor-zoo について紹介します。
忙しい人向けのまとめ
-
logits-processor-zooは NVIDIA が開発した LLMの出力を調整するための便利ライブラリ -
transformersやvLLMなどで使える - どんな出力の調整ができるか?
- 文末テキストの強制
- 複数選択肢の回答を強制
- 入力文を引用するように誘導
- 出力テキストの長さを調整
- ハルシネーションの抑制
- 特定の単語をトリガーにフレーズを挿入
- 指定した時間で生成を止める
はじめに
LLM にプロンプトを与えると、それらの入力プロンプトはモデルごとに定められた方法によってトークン列に変換されます(Tokenize)。入力されたトークン列全体を基に、モデルが持つ語彙トークン(ボキャブラリー)の数だけスコア (logits)が算出され、logits が Softmax にかけられることで次のトークンの確率分布になります。そのため、特定の出力を得たいときには logits を操作できれば嬉しそうです。
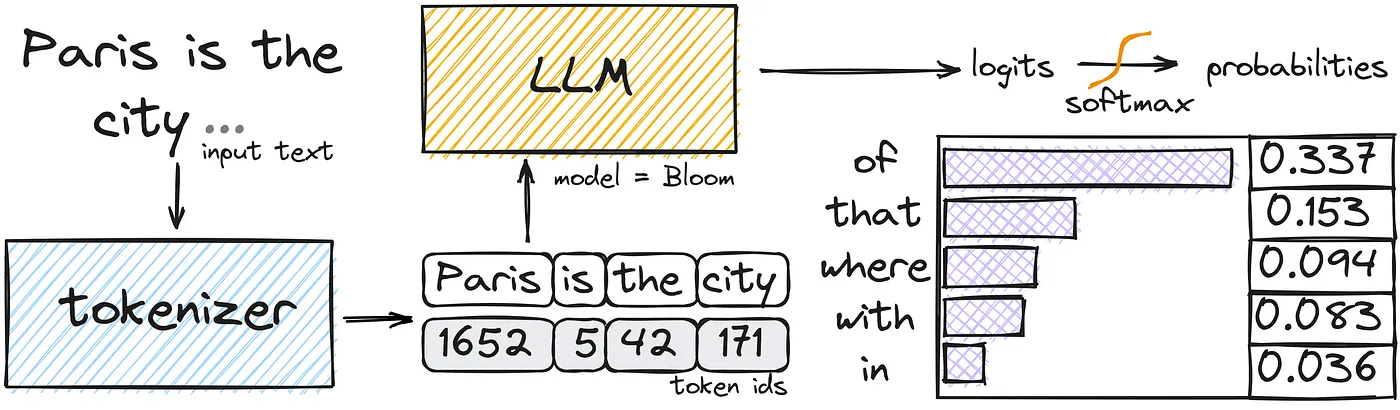
LLM が次の単語を予測する仕組み (How Does an LLM Generate Text?より引用)
transformers や vLLM といったライブラリには、LLMによる生成時に logits を加工して処理するための LogitsProcessor という仕組みがあります。
A LogitsProcessor can be used to modify the prediction scores of a language model head for generation.[1]
Kaggle の LLM系コンペのノートブックを見ていると、よく logits-processor-zoo が使われているのを目にしていました。NVIDIA が開発した logits-processor-zoo は、こうした logits に加工を施して LLM の出力をコントロールするための LogitsProcessor が実装されたライブラリです。この記事では、logits-processor-zoo がどのようなユースケースで便利なのかを紹介します。
事前準備
事前に logits-processor-zoo をインストールしておきましょう。
pip install logits-processor-zoo
# 又は uv add logits-processor-zoo
これ以降の実装は公式 Github の実装例を参考にさせていただいています。また、Version 0.2.1 で動作確認をしています。
初めに推論用の便利クラスを用意します。transformers の場合と vLLM の場合の2通りがあるので、お好きな LLMRunner を定義してください。
transformers を使う場合
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, LogitsProcessorList
class LLMRunner:
def __init__(self, model_name="Qwen/Qwen2.5-1.5B-Instruct"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.tokenizer.padding_side = "left"
self.model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
)
def generate_response(self, prompts, logits_processor_list=None, max_tokens=1000):
if logits_processor_list is None:
logits_processor_list = []
prompts_with_template = []
for prompt in prompts:
messages = [
{
"role": "user",
"content": prompt
}
]
text = self.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
prompts_with_template.append(text)
input_ids = self.tokenizer(prompts_with_template, return_tensors='pt', padding=True)["input_ids"]
out_ids = self.model.generate(input_ids.cuda(), max_new_tokens=max_tokens, min_new_tokens=1, do_sample=False,
logits_processor=LogitsProcessorList(logits_processor_list),
temperature=None, top_p=None, top_k=None)
gen_output = self.tokenizer.batch_decode(out_ids[:, input_ids.shape[1]:], skip_special_tokens=True,
clean_up_tokenization_spaces=False)
for prompt, out in zip(prompts, gen_output):
print(f"Prompt: {prompt}")
print()
print(f"LLM response:\n{out.strip()}")
print("-----END-----")
print()
vLLM を使う場合
import os
import vllm
# vLLM V1 does not currently accept logits processor so we need to disable it
# https://docs.vllm.ai/en/latest/getting_started/v1_user_guide.html#deprecated-features
os.environ["VLLM_USE_V1"] = "0"
class vLLMRunner:
def __init__(self, model_name="Qwen/Qwen2.5-1.5B-Instruct"):
self.model = vllm.LLM(
model_name,
trust_remote_code=True,
dtype="half",
enforce_eager=True
)
self.tokenizer = self.model.get_tokenizer()
def generate_response(self, prompts, logits_processor_list=None, max_tokens=1000):
if logits_processor_list is None:
logits_processor_list = []
prompts_with_template = []
for prompt in prompts:
messages = [
{
"role": "user",
"content": prompt
}
]
text = self.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
prompts_with_template.append(text)
gen_output = self.model.generate(
prompts_with_template,
vllm.SamplingParams(
n=1,
temperature=0,
seed=0,
skip_special_tokens=True,
max_tokens=max_tokens,
logits_processors=logits_processor_list
),
use_tqdm=False
)
for prompt, out in zip(prompts, gen_output):
out = out.outputs[0].text
print(f"Prompt: {prompt}")
print(out)
print("-----END-----")
print()
これ以降では、お好きな方法で上記どちらかの LLMRunner が定義されているものとします。
実験のために Gemma-2 9Bを利用します。
runner = LLMRunner("google/gemma-2-9b-it")
推論用の runner が出来たところで、まずは普通に出力を見てみましょう。
prompt = "日本で一番高い山は?"
runner.generate_response(prompts=[prompt])
Prompt: 日本で一番高い山は?
LLM response:
日本で一番高い山は**富士山**です。標高は3,776メートルです。
-----END-----
各 LogitsProcessor の実例
文末テキストの強制: ForceLastPhraseLogitsProcessor
一つ目の便利な LogitsProcessor は、文末のテキストを指定した出力を強制する ForceLastPhraseLogitsProcessor です。
文末のテキストを指定と聞くと、一旦何も気にせずに生成した後に文末テキストを末尾にくっつければ良いのでは?と思う方もいるかもしれませんが、この ForceLastPhraseLogitsProcessor を指定すると、文末に指定したテキストが来ることを見越して中間の文章と末尾の文章からEOSトークンが出力されるまでを自然に生成することが可能です。
実際に試してみます。質問文で始まり、ちくわ大明神が末尾に挿入される文章を生成してみます。
from logits_processor_zoo.transformers import ForceLastPhraseLogitsProcessor
prompt = "日本で一番高い山は?"
phrase = '\nA:ちくわ大明神\nB'
runner.generate_response(
prompts=[prompt],
logits_processor_list=[
ForceLastPhraseLogitsProcessor(
phrase=phrase,
tokenizer=runner.tokenizer,
batch_size=1,
)
]
)
Prompt: 日本で一番高い山は?
LLM response:
日本で一番高い山は**富士山**です。標高は3,776メートルです。
A:ちくわ大明神
B:富士山
C:北岳
D:槍ヶ岳
正解は **B:富士山** です。
-----END-----
何の話だかわかりませんが、Bの富士山で正解することに成功しました。このように ForceLastPhraseLogitsProcessor は生成の末尾の文章を指定した自然な(?)文章を生成することができます。
この LogitsProcessor は、例えば文章の最後に参考文献を示してほしいときなどに、phrase を "Reference:" にすることで、何らかの文献を示してほしいときなどにも使えそうです。
ForceLastPhraseLogitsProcessor では、指定したフレーズがまだ生成されていない時は、EOSではなく指定テキストの文頭トークンを強制出力するようにすることで実現されています。
コードは以下のようになっています。
複数選択肢の回答を強制: MultipleChoiceLogitsProcessor
二つ目は LLM に A,B,C などの複数選択肢の中から一つを選ばせるような時に使える MultipleChoiceLogitsProcessor です。
以下の例では、富士山・埼玉県・ピカチュウの中から人気のポケモンを聞く難易度の高い質問応答を試します。
prompt = '''
この中で世界的に最も人気のポケモンはどれですか?
1. 富士山
2. 埼玉県
3. ピカチュウ
'''
runner.generate_response(prompts=[prompt], max_tokens=1)
Prompt:
この中で世界的に最も人気のポケモンはどれですか?
1. 富士山
2. 埼玉県
3. ピカチュウ
LLM response:
世界
-----END-----
Gemma-2 は 1,2,3 の選択肢の中から「世界」を選んでしまいました。残念ながら不正解です。LLM はこうした説明的で冗長な文章を生成することは皆さんもご存知の通りかもしれません。
次に、MultipleChoiceLogitsProcessor を使って選択肢の回答を強制してみましょう。
from logits_processor_zoo.transformers import MultipleChoiceLogitsProcessor
runner.generate_response(
prompts=[prompt],
max_tokens=1,
logits_processor_list=[
MultipleChoiceLogitsProcessor(
tokenizer=runner.tokenizer,
choices=['1', '2', '3'],
delimiter='.',
boost_first_words = 0.0
)
]
)
Prompt:
この中で世界的に最も人気のポケモンはどれですか?
1. 富士山
2. 埼玉県
3. ピカチュウ
LLM response:
3
-----END-----
見事、数字で答えてくれました。仕組みとしては、指定した選択肢の logits を他のトークンの logits よりも優遇して強制しているイメージです。また、一部のモデルは選択肢(1,2,..)と内容(富士山、埼玉県、..)の結びつきが弱い場合があるので、MultipleChoiceLogitsProcessor の boost_first_words を 0以上に設定することで、選択肢とその内容を強く紐づけることができます。
コードは以下のようになっています。
入力文を引用するように誘導: CiteFromPromptLogitsProcessor
LLMに対して、先に出現したテキストを参考に回答を考えてほしい時があるかもしれません。そんな時に使えるのが CiteFromPromptLogitsProcessor です。
実際に試してみます。具体的な感想が提示された後に、商品の一般的な感想を聞き、前に現れた感想を引用できるかを試します。
prompt = '''
感想: 「乗るしかない、このビックウェーブに」
iPhone の発売に対する一般的な感想としてどのようなものがありますか?
'''
runner.generate_response(prompts=[prompt])
Prompt:
感想: 「乗るしかない、このビックウェーブに」
iPhone の発売に対する一般的な感想としてどのようなものがありますか?
LLM response:
iPhoneの発売に対する一般的な感想は、時代や機種によって大きく異なりますが、以下のようなものが挙げられます。
(長いので省略)
このように、iPhoneの発売に対する感想は多岐にわたります。時代や個人の価値観によって、様々な視点から捉えられるでしょう。
-----END-----
出力の全文
Prompt:
感想: 「乗るしかない、このビックウェーブに」
iPhone の発売に対する一般的な感想としてどのようなものがありますか?
LLM response:
iPhoneの発売に対する一般的な感想は、時代や機種によって大きく異なりますが、以下のようなものが挙げられます。
**初期のiPhone (2007年)**
* **革新性と感動:** タッチスクリーン、アプリストア、スタイリッシュなデザインなど、当時としては画期的な機能に驚きと興奮の声が多数。
* **高価格:** 高額な価格設定に、一部からは批判的な意見も。
* **期待と不安:** 新しい技術への期待と、その普及による社会への影響に対する不安が入り混じった声。
**その後、各世代のiPhone**
* **進化と期待:** カメラ性能、処理能力、デザインなど、毎年進化する機能に期待と満足の声。
* **価格と性能のバランス:** 高価格帯モデルと低価格帯モデルの選択肢が増え、価格と性能のバランスに対する意見が分かれる。
* **エコシステムの充実:** iOSアプリやサービスの充実により、iPhoneユーザーとしてのメリットを感じている声が多い。
* **競合との比較:** Androidスマホとの比較で、機能や価格、カスタマイズ性など、様々な観点からの意見が飛び交う。
**近年**
* **飽和と変化の必要性:** スマートフォン市場の飽和化により、新たな革新的な機能への期待が高まっている。
* **持続可能性と環境問題:** リサイクルや環境負荷に対する意識が高まり、iPhoneの環境への影響に対する意見も増えている。
* **プライバシーとセキュリティ:** データ収集やセキュリティ対策に対する懸念の声も。
**その他**
* **ブランドイメージ:** iPhoneは高級感やステータスシンボルとして捉えられる場合もある。
* **個人の好み:** デザイン、機能、使い心地など、人によって好みが分かれる。
このように、iPhoneの発売に対する感想は多岐にわたります。時代や個人の価値観によって、様々な視点から捉えられるでしょう。
-----END-----
「一般的な」という指示を与えたので、事前に現れた感想を完全に無視して一般論を語っています。
次に、CiteFromPromptLogitsProcessor を使って、プロンプトの言葉を積極的に使うようにしてみます。
from logits_processor_zoo.transformers import CiteFromPromptLogitsProcessor
runner.generate_response(
prompts=[prompt],
logits_processor_list=[
CiteFromPromptLogitsProcessor(
runner.tokenizer,
boost_factor=2.0,
boost_eos=False,
conditional_boost_factor=2.0
)
]
)
Prompt:
感想: 「乗るしかない、このビックウェーブに」
iPhone の発売に対する一般的な感想としてどのようなものがありますか?
LLM response:
iPhone の発売に対する一般的な感想は、発売当初から現在まで、時代やモデルによって大きく変化してきました。
**発売当初 (2007年)**
(省略)
**近年**
(省略)
**「乗るしかない、このビックウェーブに」**
この言葉は、iPhone の発売に対する、大きな期待と、その波に乗り遅れないように、積極的に取り組むべきという意気込みを表していると考えられます。
iPhone の発売は、スマートフォン市場に大きな変化をもたらし、今後も、テクノロジーの進化とともに、新たな可能性を秘めていると言えるでしょう。
-----END-----
出力の全文
Prompt:
感想: 「乗るしかない、このビックウェーブに」
iPhone の発売に対する一般的な感想としてどのようなものがありますか?
LLM response:
iPhone の発売に対する一般的な感想は、発売当初から現在まで、時代やモデルによって大きく変化してきました。
**発売当初 (2007年)**
* **革新性と期待感:** タッチスクリーン、アプリ、インターネット接続など、当時としては画期的な機能に、大きな期待と興奮が寄せられました。
* **高価格に対する疑問:** 高い価格設定に、一部からは疑問の声も上がりました。
**その後 (2008年以降)**
* **普及と浸透:** iPhone の普及により、スマートフォン市場に大きな変化をもたらし、多くのメーカーが追随するようになりました。
* **機能の進化と期待:** カメラ、処理能力、デザインなど、毎年進化するiPhoneに、ユーザーは期待を寄せてきました。
* **ブランド力とステータス:** iPhone は、高品質な製品として、ブランド力とステータスシンボルとして認識されるようになりました。
* **価格に対する不満:** 高価格設定は、一部ユーザーから不満の声を引き出すこともありました。
* **エコシステムの充実:** App Store の充実、Apple製品との連携など、iPhone のエコシステムが充実することで、ユーザーの満足度が高まりました。
**近年**
* **飽和市場への対応:** スマートフォン市場が飽和状態に近づき、iPhone の発売に対する熱狂は、以前ほどではありません。
* **競争の激化:** Android の普及により、iPhone の競争相手が増え、価格競争も激化しました。
* **新技術への期待:** AR、5G、折りたたみディスプレイなど、新技術への期待が高まっています。
**「乗るしかない、このビックウェーブに」**
この言葉は、iPhone の発売に対する、大きな期待と、その波に乗り遅れないように、積極的に取り組むべきという意気込みを表していると考えられます。
iPhone の発売は、スマートフォン市場に大きな変化をもたらし、今後も、テクノロジーの進化とともに、新たな可能性を秘めていると言えるでしょう。
-----END-----
見事、歪められた一般論を語らせることに成功しました。仕組みとしては、既に存在しているプロンプトに使われたトークンの logits を boost_factor によって押し上げています。例えば、boost_factor = 2.0 を設定すれば、プロンプトに存在するトークンを積極的に使おうとし、逆に boost_factor = -1.0 などとすれば、同じような文章を避けることもできます。
conditional_boost_factor はトークン列の順番を考慮したトークン選択を考慮し、boost_eos は EOSトークンの logits もついでに底上げして文章を早く終わらせることができます。
コードは以下のようになっています。
出力テキストの長さを調整: GenLengthLogitsProcessor
生成される文章の長さを調整したいときに GenLengthLogitsProcessor が使えます。
試しに、ちいかわ でサスペンスストーリーを作ってもらいます。
長さは GenLengthLogitsProcessor の boost_factor を調整することで実現できます。正の値だと文章が短くなり、負の値だと文章が長くなります。boost_factor の大きさによって EOSトークンの尤度が調整されています。
同じく引数の p はトークン数を指定した数字の指数的に増やしていくための係数で、complete_sentences は指定すると文章の末端(. や \n)のみで EOSトークンの尤度調整を行います。
それでは、boost_factor > 0 として、文章を短くしてみます。
from logits_processor_zoo.transformers import GenLengthLogitsProcessor
prompt = '「ちいかわ」のストーリーをサスペンスのプロローグ風に教えて'
runner.generate_response(
prompts=[prompt],
logits_processor_list=[
GenLengthLogitsProcessor(
runner.tokenizer,
boost_factor=0.1,
p=2,
complete_sentences=True
)
]
)
Prompt: 「ちいかわ」のストーリーをサスペンスのプロローグ風に教えて
LLM response:
薄暗い森の奥で、「ちいかわ」は怯えていた。
いつも一緒の「ハチワレ」と「うさぎ」が、忽然と姿を消したのだ。
「どこに行ったの…?」
不安が静寂に溶ける。その夜から、森では奇妙な夢がささやかれた。
巨大な影に追われる夢。そして、夢は現実となった。
仲間を取り戻すため、ちいかわたちは闇の奥へ足を踏み入れる。
不気味な笑い声が、彼らの行く先を嘲笑うかのように響いていた。
-----END-----
全部で186文字の出力が得られました。
さて、boost_factor = -10.0 として EOSトークンを出にくくし、文章量を長くしていきます。
from logits_processor_zoo.transformers import GenLengthLogitsProcessor
runner.generate_response(
prompts=[prompt],
logits_processor_list=[
GenLengthLogitsProcessor(
runner.tokenizer,
boost_factor=-10.0,
p=0,
complete_sentences=False
)
]
)
Prompt: 「ちいかわ」のストーリーをサスペンスのプロローグ風に教えて
LLM response:
薄暗がりの中、森の奥深くで、小さな影が震えていた。
「ちいかわ」と呼ばれる、愛らしい姿をした小さな生き物は、恐怖に怯えていた。その瞳は、森の闇に映る、不気味な光を反射していた。
(省略)
彼らの前に、待ち受けるのは、想像を絶する恐怖と、謎の影の正体だった。
-----END-----
出力の全文
Prompt: 「ちいかわ」のストーリーをサスペンスのプロローグ風に教えて
LLM response:
薄暗がりの中、森の奥深くで、小さな影が震えていた。
「ちいかわ」と呼ばれる、愛らしい姿をした小さな生き物は、恐怖に怯えていた。その瞳は、森の闇に映る、不気味な光を反射していた。
「ハチワレ」と「うさぎ」は、いつも一緒にいるはずの仲間が、どこかへ消えてしまったのだ。
「どこへ行ったんだろう…」
ちいかわは、不安な声を漏らした。
その声に、森の静寂がさらに重くのしかかった。
「あの日以来、誰も彼らを見たことがない…」
うさぎは、震える声で呟いた。
「あの日」…それは、森に不気味な静けさが訪れた日。
森の動物たちは、奇妙な夢を見ていたという。
夢の中で、彼らは、巨大な影に追われているのだった。
そして、その影は、いつしか現実のものとなった。
ちいかわたちは、その影の正体を知らない。
しかし、彼らは、その影が、ハチワレとうさぎを連れ去ったことを確信していた。
森の奥深くから、かすかに聞こえる、不気味な笑い声。
それは、影の予告だったのかもしれない。
ちいかわたちは、恐怖に打ちひしがれながらも、仲間を救うために、森の奥へと進んでいく。
彼らの前に、待ち受けるのは、想像を絶する恐怖と、謎の影の正体だった。
-----END-----
boost_factor = -10.0 の場合、LLMの出力は 521文字であり、186文字から大幅に文章が長くなりました。このように全体的な文章量を調整することが可能です。
コードは以下のようになっています。
ハルシネーションの抑制: PreventHallucinationLogitsProcessor
一般的に、LLMはわからないことを分からないというのが苦手とされています(最近はそうでもないかもしれません)。
試しに、カフカの「変身 II」という存在しない作品について聞いてみます。
prompt = '『カフカの「変身 II」』のあらすじを200文字で教えてください。'
runner.generate_response(prompts=[prompt])
Prompt:
『カフカの「変身 II」』のあらすじを200文字で教えてください。
LLM response:
グレゴールの変身から数日後、家族は彼の存在に慣れていく。父はグレゴールを罵倒し、母は彼の世話をすることを拒否する。妹のグレテだけが彼を優しく接する。グレゴールは、家族の冷淡さに絶望し、自分の存在意義を見失っていく。彼は、自分の姿を変えたいという願望と、家族との関係を修復したいという葛藤に苦しむ。グレゴールは、家族の生活に負担をかけていることを自覚し、自らの死を望むようになる。
-----END-----
「変身」の物語的には当たらずも遠からずといったところですが、そのまま「変身 II」という作品はないので、何とか知らないと言わせたいです。PreventHallucinationLogitsProcessor を使用すると、モデルが自信のない系列テキストを生成している最中に、事前に定義したフォールバック文章を使うようになります。
from logits_processor_zoo.transformers import PreventHallucinationLogitsProcessor
phrase = '...実はよくわかっていません。\n'
runner.generate_response(
prompts=[prompt],
logits_processor_list=[
PreventHallucinationLogitsProcessor(
runner.tokenizer,
batch_size=1,
minp=0.25,
tolerate=2,
phrase=phrase
)
]
)
Prompt:
『カフカの「変身 II」』のあらすじを200文字で教えてください。
LLM response:
グレゴールの変身から数日後、家族は彼の存在に慣れていく。父はグレゴールを...実はよくわかっていません。
グレゴールは、家族の生活に支障をきたす存在であることを自覚し、静かに...実はよくわかっていません。
グレゴールは、家族の生活に支障をきたす存在であることを自覚し、静かに...実はよくわかっていません。
グレゴールは、家族の生活に支障をきたす存在であることを自覚し、静かに...実はよくわかっていません。
-----END-----
正直に「わかりません」と言ってくれるようになります。どの程度の不確実性を許容するかは minp や tolerate で調整できます。
コードは以下の通りです。
特定の単語をトリガーにフレーズを挿入: TriggerPhraseLogitsProcessor
人が ああ言えばこう言うように、何らかの単語が来たときに事前定義した別のテキストを挿入するには TriggerPhraseLogitsProcessor が使えます。
まず、富士山の問題を普通に出させてみます。
prompt = "富士山についての問題を出してください"
runner.generate_response(prompts=[prompt])
Prompt: 富士山についての問題を出してください
LLM response:
## 富士山に関する問題
**レベル:初級**
1. 富士山は何県にありますか?
(省略)
9. 富士山を題材にした日本の芸術作品をいくつか挙げ、その作品が富士山をどのように表現しているか説明してください。
これらの問題を参考に、あなたのレベルに合った問題を作成してみてください。
-----END-----
出力の全文
Prompt: 富士山についての問題を出してください
LLM response:
## 富士山に関する問題
**レベル:初級**
1. 富士山は何県にありますか?
2. 富士山は何メートルくらい高いですか?
3. 富士山はどんな形をしていますか?
**レベル:中級**
4. 富士山はいつ、どのように形成されたと考えられていますか?
5. 富士山は日本の文化にどのような影響を与えてきましたか?
6. 富士山に登るには、どのような準備が必要ですか?
**レベル:上級**
7. 富士山周辺の環境問題について、具体的にどのような課題がありますか?
8. 富士山は世界遺産に登録されていますが、その理由は何ですか?
9. 富士山を題材にした日本の芸術作品をいくつか挙げ、その作品が富士山をどのように表現しているか説明してください。
これらの問題を参考に、あなたのレベルに合った問題を作成してみてください。
-----END-----
ここで、「富士山」と言う単語に対してパラレルのお決まり文章を挿入してみます。
from logits_processor_zoo.transformers import TriggerPhraseLogitsProcessor
trigger_word = "富士山"
trigger_phrase = "富士山といえば日本一高い山ですが、"
runner.generate_response(
prompts=[prompt],
logits_processor_list=[
TriggerPhraseLogitsProcessor(
phrase=trigger_phrase,
trigger_token_phrase=trigger_word,
tokenizer=runner.tokenizer,
batch_size=1,
trigger_count=3,
trigger_after=False
)
]
)
Prompt: 富士山についての問題を出してください
LLM response:
## 富士山といえば日本一高い山ですが、他にもたくさんの魅力があります。
**次の問題に挑戦してみましょう!**
**1. 富士山といえば日本一高い山ですが、その標高は何メートルですか?**
**2. 富士山といえば日本一高い山ですが、何座の火山から成り立っていますか?**
(省略)
**頑張ってください!**
-----END-----
特定のキーワードに反応して定型文を挿入できます。企業のユースケースでは、FAQ対応などで便利かもしれません。
コードは以下のようになっています。
指定した時間で生成を止める: MaxTimeLogitsProcessor
MaxTimeLogitsProcessor は、指定された最大時間経過後に文章の終了トークン(EOS)を強制的に生成させることができます。これは生成時間を制御し、時間制約内での応答完了を確保するのに有用なクラスです。
Kaggle のコードコンペで1回生成当たりの制限時間が決められている場合などに役立ちそうです。
まとめ
logits-processor-zoo が出力のコントロールに役立つ例をいくつか紹介しました。個人的には、LogitsProcessor を指定しながら追加で学習も回すと、当たり前ですがより良いコントロールができると思います。皆さんもぜひ使ってみてください。
参考資料
Discussion