AI つまみアイコンを支える技術
この記事は UEC Advent Calendar 2024 の 6日目として書かれています。
はじめに
2022年に画像生成モデルのStable Diffusionが登場して以来、画像生成AIに関連するサービスや技術について耳にする機会が増えているのではないでしょうか。
2024年12月現在、FLUX.1やStable Diffusion 3.5といった最先端の画像生成モデルは、まるで実写と見間違うほどの高品質な画像を生成することが可能になっています。

「Stable Diffusion 3.5と書かれた看板を持つ猫」
これらの画像生成モデルは、基本的にあらゆるテキストに基づいて画像を生成できるよう設計されています。さらに、これらのモデルを基に追加の学習を加えることで、特定のキャラクターや人物を生成する技術も進歩を遂げています。
つまみアイコン
つまみ (@TrpFrog) は、インターネット上で非常に人気のあるコメディアンの一人です。彼女はユーモラスで機知に富んだ発言を次々と生み出し、その才能は多くのファンを魅了しています。特に、彼女の可愛らしいアイコン画像から想像できないような大胆かつ痛快な発言は、彼女のユニークな魅力の一部となっています。
さらに、つまみは自身がデザインしたつまみアイコンデータセットをコミュニティに向けて公開しています。このデータセットは MIT ライセンスの下で誰でも使用することが可能です。これにより、彼女のユーモアやアートに触発された多くの人々が、さらに新しい作品を生み出すことができる環境が整っています。
 つまみアイコンデータセット (trpfrog/trpfrog-icons)
つまみアイコンデータセット (trpfrog/trpfrog-icons)
本人に許可を得て、このデータセットを活用して学習した Prgckwb/trpfrog-sd3.5-large という画像生成モデルを利用すると、以下のような実際には存在しないつまみアイコンを生成することができます。

さまざまなAIつまみアイコン

勝手にやらせていただきます
本記事では、深層学習に触れたことのない読者にも分かるように Stable Diffusion をはじめとする画像生成 AI にまつわる用語や技術を整理して説明し、AI つまみアイコン生成がどのような仕組みで成り立っているのかを「なんとなく理解できる」ようになる ことを目標とします。
画像生成モデルを支える技術
深層学習で使われる用語整理
以下では、深層学習 (Deep Learning) で使用されている慣習に従って関連する用語を使用します。
一般に AI などと呼ばれる何らかの処理を行うものを モデル と呼びます。
モデルが実際に何を行なっているかのイメージとしてよく使われているのは、「モデルは何らかの関数を近似したもの」 であることです。
今、
深層学習においては ニューラルネットワーク というもので、こういった関数の近似(学習)を行なっていきますが、詳細が気になる方は名著 ゼロから作るDeep Learning を一読することをオススメします。

画像分野における様々なモデルの例
こうしたモデルが事前に集められたデータから何らかの処理を可能にしていく過程を 学習 (train, learning) と呼びます。通常、教師あり学習という方法では、例えば画像生成モデルならテキストと画像のペアデータなどの、モデルの入出力に相当するペアデータを大量に集め、データの裏に隠された入出力変換のルールをモデルに考えてもらう必要があります。
そうして学習したモデルを使い、モデルが頑張って覚えたルールを適用して処理を行うことを 推論 (inference) と呼ぶことにします。画像生成モデルにおいて推論とは実際に画像を生成することを指します。
例えば、つまみアイコンを作成したい時に、画像を生成するための機構を画像生成モデル、このモデルをつまみアイコンデータで学習し、最後に推論(画像生成)することで任意のテキストに沿う画像を作ります。

上の画像では、画像のみからつまみアイコンを生成していますが、実際のユースケースを考えると「どのようなつまみアイコンを生成したいか」をテキストで指定できると出力画像がコントロールできて嬉しいです。
このような生成を 条件付き生成 などと呼び、モデルの学習の際に任意の条件を付与することで実現することが一般的です。

拡散モデル (Diffusion Models)
以前からニューラルネットワークで画像を生成する試みはありましたが、2020年頃から Diffusion Model (拡散モデル) と呼ばれるモデルが台頭してきました。拡散モデルは正規分布などのサンプル容易な分布から、複数のステップを経ることで段々と対象の分布への変換を近似するモデルです。
イメージとして以下の図のように、正規分布からサンプリングしたもの(ノイズと呼ばれる)から、徐々にノイズを除去した完全な画像を生成していき、ノイズを除去し終わった出力が我々が見る生成画像として扱われます。

ノイズから画像への変化
一般に、拡散モデルや Diffusion Model というときは、ここで言う 「ノイズを逐次的に除去していく際に使われる深層学習モデル」 を指していることが大多数です。
Stable Diffusion
Stable Diffusion という単語は人によって何を指しているのかが異なります。元々は Latent Diffusion Models[1] と呼ばれる拡散モデルの一種を、巨大な画像とテキストのデータで学習し、高い画像生成能力を持たせて広く一般に使えるように公開されたモデルを指します。そのため、Latent Diffusion Model と言う構造の拡散モデルを学習して画像生成が可能となったモデルが Stable Diffusion と言うわけです。
従来の拡散モデルとの違いは、ノイズ除去を画像空間上で行わずに、画像情報が圧縮された 潜在空間 (Latent Space) 上で行なっている点です。

Latent Diffusion Model におけるノイズ除去の従来手法との比較
VAE
ここで VAE (Variational Auto Encoder) と呼ばれるモデルは、学習によって画像を高度に圧縮することに成功したモデルと言う認識でとりあえず大丈夫です (怒られそう)。
例えば、Stable Diffusion v1.4 で使われている VAE は 縦横
U-Net
さて、ここでノイズを除去するモデルとは実際に何なのでしょうか?
Stable Diffusion においては、U-Net[2] と言うモデルを拡張したものが用いられます。
U-Net は複数ステップ (例えば 1000回) の間、画像の Latent からノイズを徐々に除去していくことで最終的にノイズのないキレイな画像 (Latent) を生成します。学習時の U-Net の1ステップにおいて行われていることは、指定したタイムステップ

U-Net が行なっていること
また、U-Net の予測対象を何にするかは選択肢がいくつかあり、直感的には微小ノイズが除去された Latent そのものを予測するもの(上図最上段)がありますが、多くは当該ステップで加わったであろうノイズを予測する (上図中段) や その他の予測対象(上図最下段)を用いることが一般的です。
今の所一番多いのがノイズを予測して Latent から引いていく上図中段のタイプで、最近の流行のモデルでは v-prediction[3] などの別の予測対象を持つモデルが流行っているイメージです。
さらに、ノイズ除去モデルの構造においては U-Net のみならず DiT (Diffusion Transformer)[4] などのモデルも出てきており、様々なアプローチが生まれています。数え上げるとキリがないので気になる方は調べてみてください。
Text Encoder
最後に Text Encoder についてです。
テキストから画像を生成したい時はモデルにテキストを入力する必要があるのですが、深層学習モデルは "an icon of trpfrog" のような文章をそのままでは理解してくれません。我々人間が文章から品詞や単語の意味などを把握できるように、うまく文章理解を可能に出来ると嬉しそうです。
このモデルの学習過程については割愛しますが、学習済みの Text Encoder がどのように機能しているかを下図に示します。

Text Encoder の動作
このように、Tokenizer によって入力テキストをトークンに分けた数値列にして、その数値列を Text Encoder によって テキスト埋め込み (Text Embedding) としてやります。
最近の拡散モデル
これまで説明してきた内容は、Latent Diffusion Model を基盤とした Stable Diffusion v1 や v2 系列のモデルについてのものでした。序盤に紹介した「さまざまなAIつまみアイコン」はPrgckwb/trpfrog-sd3.5-large というモデルを用いて生成されており、このモデルは Stable Diffusion 3.5 Large をさらに学習した結果得られたものです。
最近の拡散モデルでは、ノイズ除去モデルやテキストエンコーダーなどの構造が進化し、精度や効率が向上しています。例えば、Diffusion Transformer(DiT)などの新しいアーキテクチャが採用され、よりリアルな画像生成が可能になっています。また、テキストからより豊かな画像を生成するための新しい手法も開発されていますが、こうした技術革新の基本は依然として変わっていません。
また、学習の詳細についてはここで詳しく触れていませんが、Prgckwb/trpfrog-sd3.5-large モデルの学習プロセスを一部可視化した結果を以下に示します。この可視化では、Stable Diffusion 3.5 Largeが初期段階では「trpfrog」という単語を一般的なカエルとして認識していたのが、学習が進むにつれ独自のつまみアイコンを生成できるようになっていく過程が見て取れます。
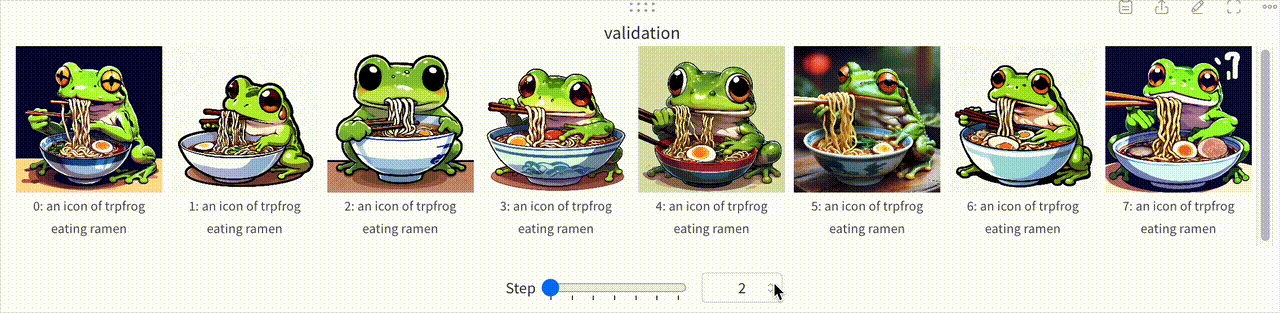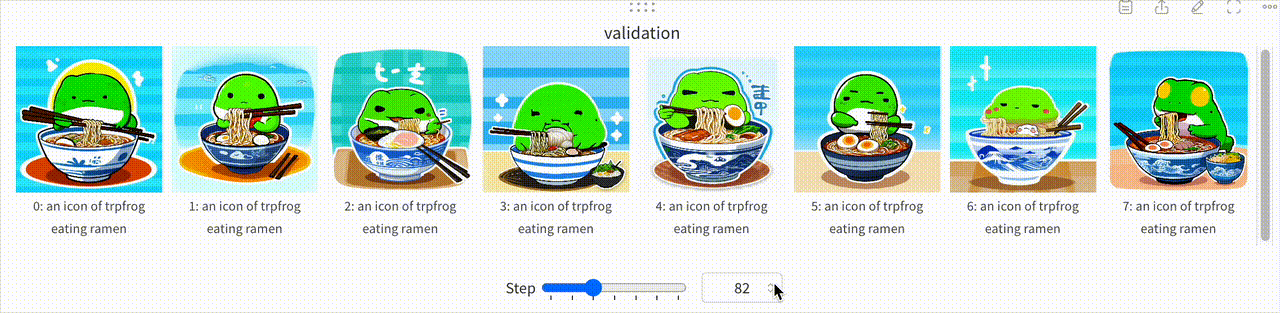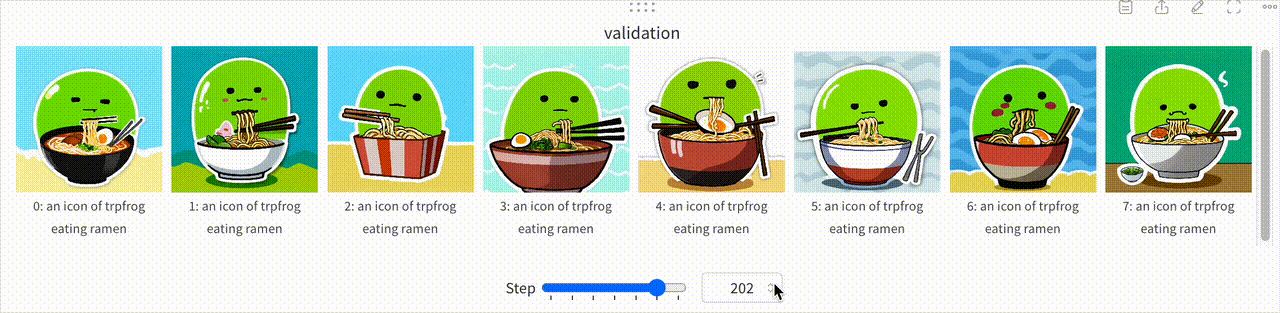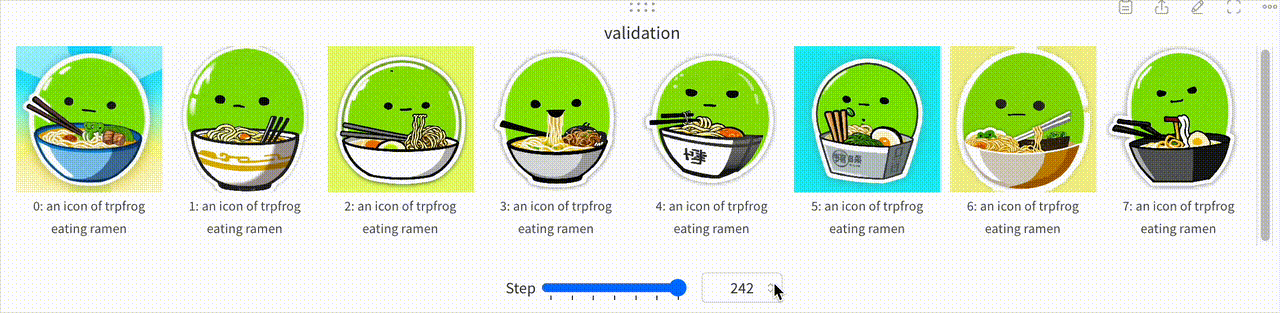
コードで追う Stable Diffusion による画像生成
さて、ここまでの知識があればザックリと Stable Diffusion などの画像生成モデルのことが分かったと言えます。
ここからは学習済みの Trpfrog Diffusion モデル を使って画像生成の流れをコードで掴んでいきましょう。忙しい人向けに章末に全文コードも載せました。
以下のコードは次の環境で動いています。
- torch: 2.5.1+cu118
- diffusers: 0.31.0
- transformers: 4.46.3
- accelerate: 1.1.1
- safetensors: 0.4.5
それではモデルを読み込んでいきます。
import torch
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import UNet2DConditionModel, AutoencoderKL, PNDMScheduler
from diffusers.image_processor import VaeImageProcessor
model_id = 'Prgckwb/trpfrog-diffusion'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# TrpFrog Diffusion を構成するコンポーネントの読み込み
tokenizer = CLIPTokenizer.from_pretrained(model_id, subfolder='tokenizer')
text_encoder = CLIPTextModel.from_pretrained(model_id, subfolder='text_encoder').to(device)
vae = AutoencoderKL.from_pretrained(model_id, subfolder='vae').to(device)
unet = UNet2DConditionModel.from_pretrained(model_id, subfolder='unet').to(device)
# サブコンポーネント
scheduler = PNDMScheduler.from_pretrained(model_id, subfolder='scheduler')
image_processor = VaeImageProcessor()
このコードから、上記で説明した U-Net や VAE といったコンポーネントが確かに存在していることが分かります。
では、これらのモデルを使ってつまみアイコンを生成するために、最初にプロンプトを処理します。
試しに "a photo of trpfrog in winter" と言う文章でつまみアイコンを作っていきます。
prompt = 'a photo of trpfrog in winter' # 自由に変更してください
text_inputs = tokenizer(
prompt,
padding='max_length',
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors='pt',
)
text_inputs_ids = text_inputs.input_ids # (1, 77)
print(text_inputs_ids)
ここで、入力したプロンプトが数値列に変換されていることが確認できます。長さが 77 個分のトークンに分かれているのはバッチ処理の際にテキストごとの長さが異なると困るので padding を加えてトークン長を固定しているからです。これによって全部で 77 個のトークンの並びになりました。
tensor([[49406, 320, 1125, 539, 635, 79, 11438, 530, 2541, 49407, ..., 49407]])
このトークン列を Text Encoder に突っ込んでやります。そうすると、77個のトークンそれぞれについて 768の埋め込み次元を持つテキスト埋め込み prompt_embed が出来ました。
prompt_embed = text_encoder(text_inputs_ids.to(device))[0] # (1, 77, 768)
print(prompt_embed)
tensor([[[-0.3884, 0.0229, -0.0522, ..., -0.4899, -0.3066, 0.0675],
[ 0.0290, -1.3258, 0.3085, ..., -0.5257, 0.9768, 0.6652],
[ 1.1565, 0.1318, 0.7895, ..., -2.1024, -1.1519, -0.3311],
...,
[ 0.0252, 1.7729, -0.4041, ..., -2.2320, 0.3916, 0.6093],
[ 0.0217, 1.7649, -0.3808, ..., -2.2402, 0.3929, 0.5926],
[ 0.0612, 1.7842, -0.3595, ..., -2.2426, 0.4416, 0.5968]]])
上記で説明をしていない部分ですが、拡散モデルでテキスト条件に対して出力画像の多様性とテキストへの忠実度のトレードオフをコントロールするための仕組みとして Classifier-free Guidance[5] と言うものがあります。
誤解を恐れずに言えば、指定したいテキストと空白テキストの二つの埋め込みを使って拡散モデルの推論を行い、それらの出力の線形補完をしてやることで、生成時のハイパーパラメータでプロンプトへの多様性と忠実度を操作できるようになります。
数式で書くと次のようなイメージです。pred_cond, pred_uncond をそれぞれ指定したテキスト、空白プロンプトでの U-Net の出力として、
読者の方々の中には、出したくないものを指定する Negative Prompt を聞いたことのある人がいるかもしれません。
Negative Prompt は Classifier-free Guidance において、空白のプロンプトを入れている部分を「出したくない要素のテキスト記述」に変更するだけで実現できます。
では、後に Classifier-free Guidance で使うための空白プロンプトの埋め込み (Negative Embedding) を用意します。
negative_prompt = '' # 指定するとそれが出にくくなる
uncond_inputs = tokenizer(
negative_prompt,
padding='max_length',
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors='pt',
)
negative_prompt_embed = text_encoder(
uncond_inputs.input_ids.to(device)
)[0] # (1, 77, 768)
そして、これら二つのテキスト埋め込みを concat して一つにまとめます。
prompt_embed = torch.cat([negative_prompt_embed, prompt_embed]) # (2, 77, 768)
これにてテキストの処理が完成しました!もう少し画像生成に近づいていきます。
学習済み拡散モデルは、その学習過程において、正規分布をテキスト条件に合う画像分布への変換を行うことが可能になっています。そのため、正規分布から latent の形にあうノイズをサンプリングしてきます。簡単に言えば、ノイズ画像を適当に作るところから始めます。
latent は 4チャンネルで生成画像よりも小さな次元
# 正規分布からのサンプリングで再現性確保をするために乱数シードを固定
seed = 1117
generator = torch.Generator(device=device).manual_seed(seed)
# Generate random latents
latents = torch.randn(
size=(1, 4, 512 // 8, 512 // 8),
device=device,
generator=generator,
) # (1, 4, 64, 64)
あとは、U-Net の力でこのノイズから何度もノイズを除去していき、キレイな画像を作っていきます。
ループに入る前に、「何度も」を何回行うか決めておきます。
拡散モデルのサンプリング手法は実に多様な種類があり、本来 1000のステップを用いて学習されたモデルであっても、そのサンプリングを簡略化して短いステップで画像生成を実現可能です。
# 何回のステップで画像を生成するか決める
n_steps = 50
scheduler.set_timesteps(n_steps)
timesteps = scheduler.timesteps
print(timesteps)
実際に 50ステップで画像生成するときに利用されるタイムステップをみてみると、1000~1 がうまいこと50個に分けられたリストが出てきます。
tensor([981, 961, 961, 941, 921, 901, 881, 861, 841, 821, 801, 781, 761, 741,
721, 701, 681, 661, 641, 621, 601, 581, 561, 541, 521, 501, 481, 461,
441, 421, 401, 381, 361, 341, 321, 301, 281, 261, 241, 221, 201, 181,
161, 141, 121, 101, 81, 61, 41, 21, 1])
では、50回のループを回して画像を生成しましょう。
from tqdm.auto import tqdm
# どの程度プロンプトに従わせるか
guidance_scale = 7.5
for i, t in enumerate(tqdm(timesteps)):
# CFG 用に2個必要 (negative, positive)
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(
latent_model_input, timestep=t,
) # (2, 4, 64, 64)
# VRAM の消費を抑える
with torch.no_grad():
# U-Net でノイズを予測
noise_pred = unet(
latent_model_input,
timestep=t,
encoder_hidden_states=prompt_embed,
)['sample'] # (2, 4, 64, 64)
# Classifier-free guidance (CFG)
noise_pred_uncond, noise_pred_cond = noise_pred.chunk(2)
noise_pred = (
guidance_scale * noise_pred_cond
+ (1 - guidance_scale) * noise_pred_uncond
)
# 予測したノイズを引いて一つ前のステップの latent を取得
latents = scheduler.step(noise_pred, t, latents).prev_sample
latents = (1 / 0.18215) * latents # (1, 4, 64, 64)
# VAE で Latent -> Image に Decode
image = vae.decode(latents, generator=generator).sample # (1, 3, 512, 512)
image = image_processor.postprocess(image.detach())[0] # (512, 512) の PIL画像
image
最終的に指定したプロンプトに沿ったつまみアイコンが生成できました!わいわい

"a photo of trpfrog in winter" で生成されたつまみアイコン
コード全文
import torch
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import UNet2DConditionModel, AutoencoderKL, PNDMScheduler
from diffusers.image_processor import VaeImageProcessor
from tqdm.auto import tqdm
model_id = 'Prgckwb/trpfrog-diffusion'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# TrpFrog Diffusion を構成するコンポーネントの読み込み
tokenizer = CLIPTokenizer.from_pretrained(model_id, subfolder='tokenizer')
text_encoder = CLIPTextModel.from_pretrained(model_id, subfolder='text_encoder').to(device)
vae = AutoencoderKL.from_pretrained(model_id, subfolder='vae').to(device)
unet = UNet2DConditionModel.from_pretrained(model_id, subfolder='unet').to(device)
# サブコンポーネント
scheduler = PNDMScheduler.from_pretrained(model_id, subfolder='scheduler')
image_processor = VaeImageProcessor()
prompt = 'a photo of trpfrog in winter' # 自由に変更してください
negative_prompt = '' # 指定するとそれが出にくくなる
text_inputs = tokenizer(
prompt,
padding='max_length',
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors='pt',
)
text_inputs_ids = text_inputs.input_ids # (1, 77)
prompt_embed = text_encoder(text_inputs_ids.to(device))[0] # (1, 77, 768)
uncond_inputs = tokenizer(
negative_prompt,
padding='max_length',
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors='pt',
)
negative_prompt_embed = text_encoder(
uncond_inputs.input_ids.to(device)
)[0] # (1, 77, 768)
prompt_embed = torch.cat([negative_prompt_embed, prompt_embed]) # (2, 77, 768)
seed = 1117
generator = torch.Generator(device=device).manual_seed(seed)
# Generate random latents
latents = torch.randn(
size=(1, 4, 512 // 8, 512 // 8),
device=device,
generator=generator,
) # (1, 4, 64, 64)
n_steps = 50
scheduler.set_timesteps(n_steps)
timesteps = scheduler.timesteps
# どの程度プロンプトに従わせるか
guidance_scale = 7.5
for i, t in enumerate(tqdm(timesteps)):
# CFG 用に2個必要 (negative, positive)
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(
latent_model_input, timestep=t,
) # (2, 4, 64, 64)
# VRAM の消費を抑える
with torch.no_grad():
# U-Net でノイズを予測
noise_pred = unet(
latent_model_input,
timestep=t,
encoder_hidden_states=prompt_embed,
)['sample'] # (2, 4, 64, 64)
# Classifier-free guidance (CFG)
noise_pred_uncond, noise_pred_cond = noise_pred.chunk(2)
noise_pred = (
guidance_scale * noise_pred_cond
+ (1 - guidance_scale) * noise_pred_uncond
)
# 予測したノイズを引いて一つ前のステップの latent を取得
latents = scheduler.step(noise_pred, t, latents).prev_sample
latents = (1 / 0.18215) * latents # (1, 4, 64, 64)
# VAE で Latent -> Image に Decode
image = vae.decode(latents, generator=generator).sample # (1, 3, 512, 512)
image = image_processor.postprocess(image.detach())[0] # (512, 512) の PIL画像
# 生成画像を保存
image.save('generated_image.png')
参考サイト
本記事を読んで、さらに画像生成モデルの深掘りをしてみたい読者向けに、素晴らしい記事リストを載せるので是非読んでみてください。
- SSII2023 [SS1] 拡散モデルの基礎とその応用 ~Diffusion Models入門~
- 世界に衝撃を与えた画像生成AI「Stable Diffusion」を徹底解説!
- henatips さんのブログ
- HuggingFace の拡散モデルチュートリアル(英語)
- How diffusion models work: the math from scratch (英語)
- Step-by-Step Diffusion: An Elementary Tutorial (英語)
まとめ
本記事では、画像生成モデルに関する基礎的な概念を初学者向けにわかりやすく解説しました。この記事をきっかけに、さらに深掘りしたい方は関連する書籍や論文を参照されることをお勧めします。また、作成したつまみアイコン生成モデルはまだ改善の余地があります。興味がある方は、モデルの学習を試してみてはいかがでしょうか。Huggingface のページの Upvoteも励みになりますので、ぜひお願いします‼️
-
Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022. ↩︎
-
Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer International Publishing, 2015. ↩︎
-
Salimans, Tim, and Jonathan Ho. "Progressive distillation for fast sampling of diffusion models." arXiv preprint arXiv:2202.00512 (2022). ↩︎
-
Peebles, William, and Saining Xie. "Scalable diffusion models with transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023. ↩︎
-
Ho, Jonathan, and Tim Salimans. "Classifier-free diffusion guidance." arXiv preprint arXiv:2207.12598 (2022). ↩︎
Discussion