テキストデータをGBDTで学習したい!| SentenceTransformers + LightGBM + Polars
はじめに
テキスト列を含む表形式データを解析する必要に迫られた際に,次のような悩みを持つ方がいるかもしれません.
- LightGBM や XGBoost などで扱えるようにテキストデータをうまく扱いたい
- データ数が少なく,NNの学習が過剰になりそう
- 手間なく,簡単にベースラインを構築したい
そこで,sentence_transformers による文埋め込みベクトルを表データとして見て LightGBM による学習を行う手法を紹介します.
急いでいる人向けの全文コード
import lightgbm as lgb
import polars as pl
import torch
from datasets import load_dataset
from sentence_transformers import SentenceTransformer
from sklearn.metrics import roc_auc_score
# IMDb データセットの読み込み
dataset = load_dataset("imdb")
trainval_dataset = dataset["train"].train_test_split(
test_size=0.3, shuffle=True, seed=0
)
train_ds, valid_ds = trainval_dataset["train"], trainval_dataset["test"]
# テキスト埋め込みモデルの初期化
text_encoder = SentenceTransformer("paraphrase-MiniLM-L6-v2")
# テキストを埋め込みに変換
with torch.inference_mode():
train_embeddings = text_encoder.encode(
sentences=train_ds["text"], show_progress_bar=True
)
valid_embeddings = text_encoder.encode(
sentences=valid_ds["text"], show_progress_bar=True
)
# 列名を定義 (emb_0, emb_1, ...)
col_names = [f"emb_{i}" for i in range(train_embeddings.shape[1])]
# DataFrame の作成
df_train = pl.DataFrame(train_embeddings, schema=col_names)
df_valid = pl.DataFrame(valid_embeddings, schema=col_names)
# データセットの作成
train_data = lgb.Dataset(df_train, label=train_ds["label"])
valid_data = lgb.Dataset(df_valid, label=valid_ds["label"])
params = {"objective": "binary", "metric": "auc", "seed": 0}
# LightGBM による学習
model = lgb.train(
params,
train_data,
valid_sets=[train_data, valid_data],
callbacks=[lgb.log_evaluation(10)],
)
# テストデータでの予測
with torch.inference_mode():
test_embeddings = text_encoder.encode(
sentences=dataset["test"]["text"], show_progress_bar=True
)
df_test = pl.DataFrame(test_embeddings, schema=col_names)
test_data = lgb.Dataset(df_test)
# 予測
test_pred = model.predict(df_test)
test_gt = dataset["test"]["label"]
# AUC の計算
score = roc_auc_score(test_gt, test_pred)
print(f"Test AUC: {score:.4f}")
実行環境
dependencies = [
"datasets>=2.21.0",
"lightgbm>=4.5.0",
"polars>=1.6.0",
"scikit-learn>=1.5.1",
"sentence-transformers>=3.0.1",
]
実装
概要
テキストデータからの二値分類タスクを LightGBM で学習し,テストするところまでを目標とし,以下のような流れで実装します.
- データセットの用意
- SentenceTransformer でテキストの埋め込みを取得
- 埋め込み列を Polars DataFrame に変換
- LightGBM で学習・評価
データセット
データセットとして,映画のレビューが肯定的なものか否定的なものかのラベルが振られている imdb データセット を利用します.
例えば以下のようなデータが含まれています.

stanfordnlp/imdb のサンプルデータ
データを読み込んできます.
from datasets import load_dataset
# imdb データセットの読み込み
dataset = load_dataset("imdb")
# 学習と検証用にデータを分割 (Train:Val=7:3)
trainval_dataset = dataset['train'].train_test_split(
test_size=0.3, shuffle=True, seed=0
)
train_ds, valid_ds = trainval_dataset['train'], trainval_dataset['test']
train_ds

テキスト埋め込みの取得
テキスト埋め込みの取得には SentenceTransformers の事前学習済みモデルを利用します.
以下,公式ドキュメントの翻訳
Sentence Transformers(別名SBERT)は、最新のテキストおよび画像埋め込みモデルにアクセスし、使用し、トレーニングするための定番のPythonモジュールです。Sentence Transformerモデルを使用して埋め込みを計算する(クイックスタート)か、Cross-Encoderモデルを使用して類似度スコアを計算する(クイックスタート)ことができます。これにより、セマンティック検索、セマンティックなテキスト類似性、パラフレーズマイニングなど、幅広いアプリケーションが可能になります。
今回は,テキストの埋め込みの用途で使いましょう.例えば,384次元の埋め込みベクトルを生成するモデル (paraphrase-MiniLM-L6-v2) を利用した場合,3つのテキストが (3, 384) の数値列に変換されるイメージです.
import torch
from sentence_transformers import SentenceTransformer
# テキスト埋め込みモデルの初期化
text_encoder = SentenceTransformer('paraphrase-MiniLM-L6-v2')
# テキストを埋め込みに変換
with torch.inference_mode():
train_embeddings = text_encoder.encode(
sentences=train_ds['text'],
show_progress_bar=True
)
valid_embeddings = text_encoder.encode(
sentences=valid_ds['text'],
show_progress_bar=True
)
埋め込みを DataFrame に変換
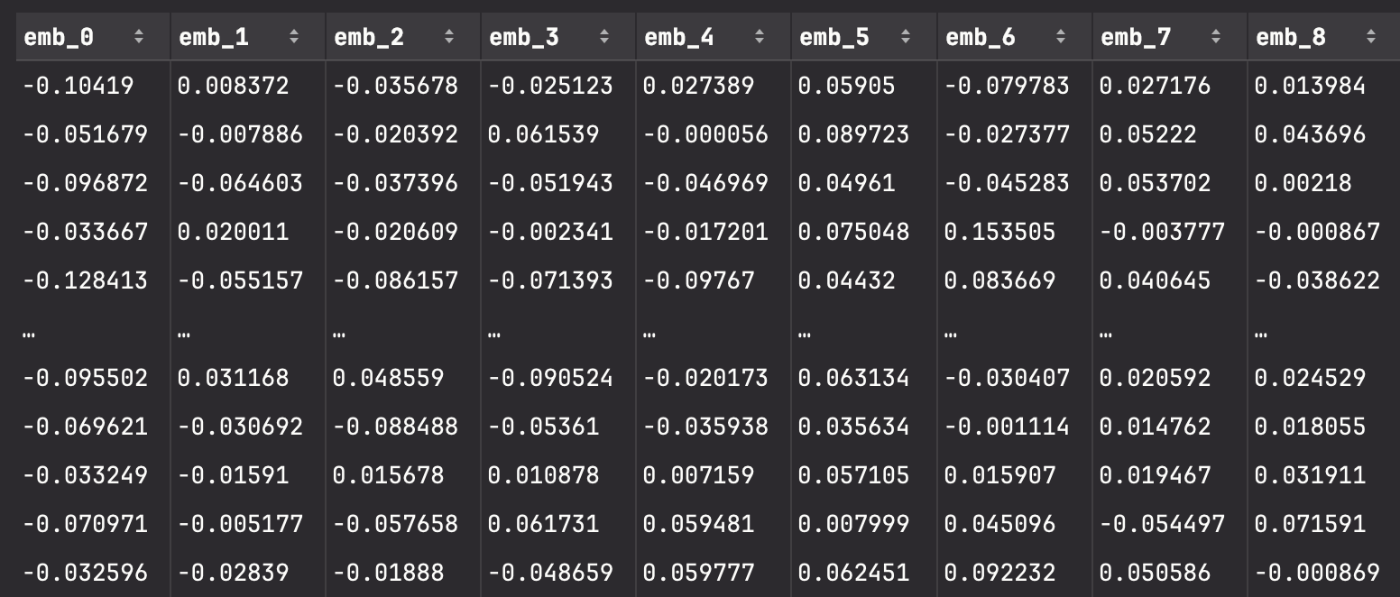
先ほど得られたテキストデータの埋め込みベクトルを Polars の DataFrame に変換してみます.384次元の数値列の各次元に対して emb_0, emb_1, ..., emb_383 の列を割り当てて収納していくイメージです.
# DataFrame の作成
import polars as pl
# 列名を定義 (emb_0, emb_1, ...)
col_names = [f'emb_{i}' for i in range(train_embeddings.shape[1])]
# DataFrame の作成
df_train = pl.DataFrame(train_embeddings, schema=col_names)
df_valid = pl.DataFrame(valid_embeddings, schema=col_names)
df_train
この結果,次のような DataFrame ができています.
LightGBM で学習
得られた DataFrame を LightGBM で学習してみます.ハイパーパラメータ等はほぼ初期値で2クラス分類モデルを構築します.
# LightGBM による学習
import lightgbm as lgb
# データセットの作成
train_data = lgb.Dataset(df_train, label=train_ds['label'])
valid_data = lgb.Dataset(df_valid, label=valid_ds['label'])
params = {
'objective': 'binary',
'metric': 'auc',
'seed': 0
}
# モデルの学習
model = lgb.train(
params,
train_data,
valid_sets=[train_data, valid_data],
callbacks=[
lgb.log_evaluation(10)
]
)
学習ログ
[LightGBM] [Info] Number of positive: 8754, number of negative: 8746
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.011728 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 97920
[LightGBM] [Info] Number of data points in the train set: 17500, number of used features: 384
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.500229 -> initscore=0.000914
[LightGBM] [Info] Start training from score 0.000914
[10] training's auc: 0.847384 valid_1's auc: 0.798287
[20] training's auc: 0.885864 valid_1's auc: 0.825493
[30] training's auc: 0.909950 valid_1's auc: 0.841223
[40] training's auc: 0.927438 valid_1's auc: 0.852182
[50] training's auc: 0.941279 valid_1's auc: 0.859451
[60] training's auc: 0.952425 valid_1's auc: 0.86405
[70] training's auc: 0.961207 valid_1's auc: 0.868189
[80] training's auc: 0.968746 valid_1's auc: 0.872177
[90] training's auc: 0.974574 valid_1's auc: 0.875339
[100] training's auc: 0.979661 valid_1's auc: 0.877507
テストデータで評価して見ます.
# テストデータでの予測
from sklearn.metrics import roc_auc_score
with torch.inference_mode():
test_embeddings = text_encoder.encode(
sentences=dataset['test']['text'],
show_progress_bar=True
)
df_test = pl.DataFrame(test_embeddings, schema=col_names)
test_data = lgb.Dataset(df_test)
# 予測
test_pred = model.predict(df_test)
test_gt = dataset['test']['label']
# AUC の計算
score = roc_auc_score(test_gt, test_pred)
print(f'Test AUC: {score:.4f}')
結果,Test AUC: 0.8621 が得られ,無事テキストデータを LightGBM で学習させることができました.
まとめ
SentenceTransformers + LightGBM + Polars を用いてテキストデータの二値分類タスクの学習と評価を行いました. コンペ等で使う場合には様々な課題が依然として残るものの,簡単なベースライン構築には役立つのではないかと思います.何か他の知見がある方は教えてください.
Discussion