Grafana アラートメール送信設定手順
Grafanaで、リソース使用率が高い場合にアラートを出し、指定したメールアドレスにアラートメールを送信するための設定手順を示します。
この設定でできること
・リソース使用率が一定値以上のインスタンスがある場合にアラートを出力する方法がわかるようになる
・アラートが発生した場合、指定したメールアドレスに送信できるようになる
今回は、CPU使用率が指定した値以上である時間が何分か続いた場合にアラートメールが送信されるようなアラートルールの作成方法を記載します。
※一番下にCPU以外(メモリ等)のメトリクスの設定についても簡単に記載しています
想定環境
CentOS7またはAlmalinux8
参考にしたサイト
0. アラートルール作成画面を開く
最初に、左メニューの「Alert rules」をクリックし、右の「New alert rule」をクリックしてアラートルール管理画面に入ります。
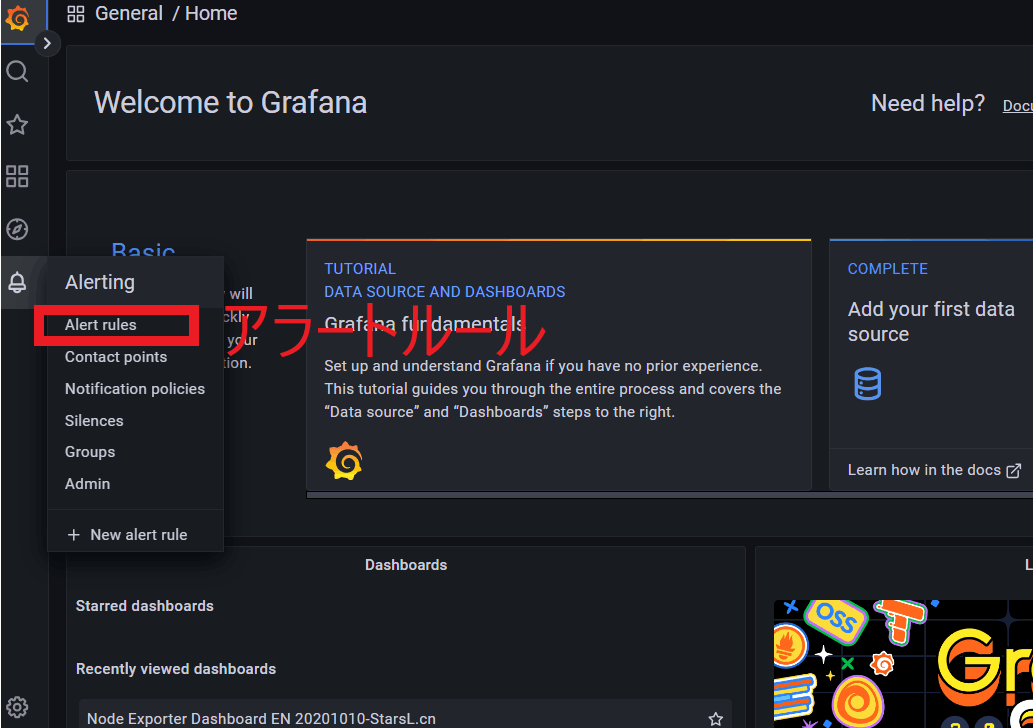
次に、左メニューの「Alert rules」をクリックし、右の「New alert rule」をクリックしてアラートルール管理画面に入ります。
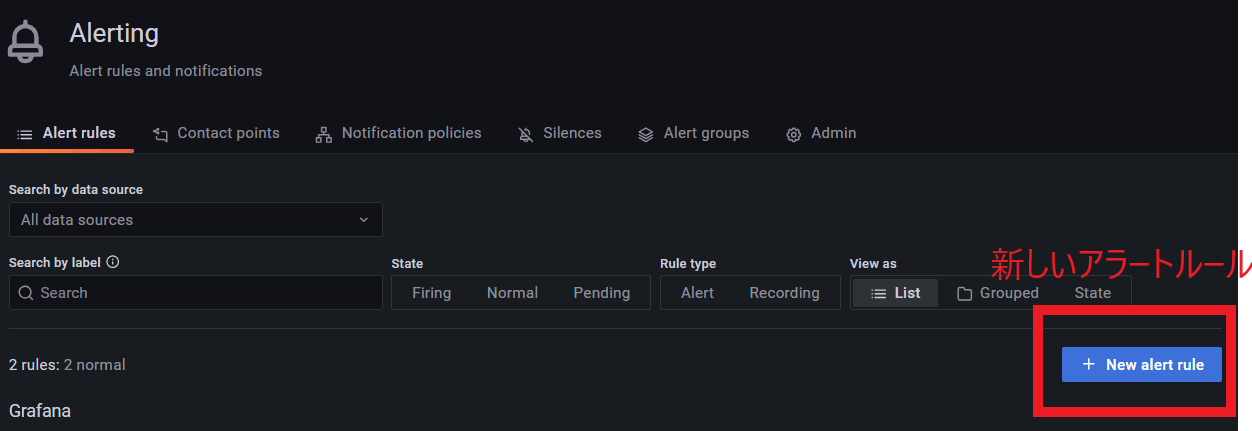
以下アラートルール作成画面
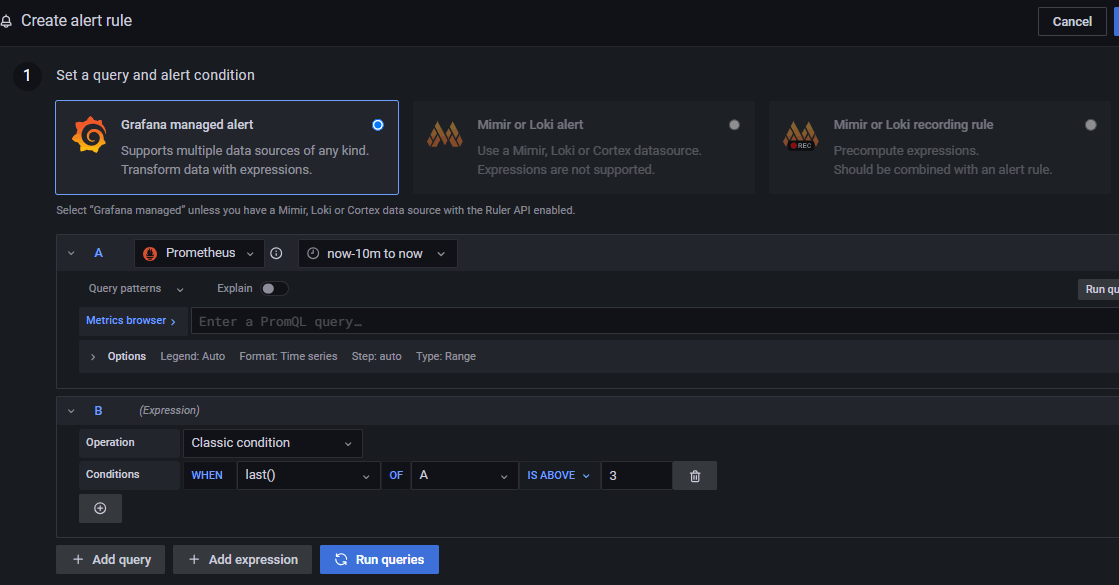
このページでは
1 Set a query and alert condition
2 Alert evaluation behavior
3 Add details for your alert
4 Notifications(←今回は記載不要)
と設定項目が分かれている
1. Set a query and alert condition 設定
ここでは、アラートを設定を行いたいメトリクスについての評価関数(クエリ関数)を作成します。
今回はインスタンス名が「client1:9100」のサーバーにおける直近1分間のCPU使用率の平均値が80%以上である場合にアラートを発生させるようクエリ関数を設定します。
1.1 「A. クエリ関数」
Prometheusクエリ言語(PromQL)を用いて、CPU使用率についてのPrometheusメトリクスの評価を行うクエリ関数を設定する
まず、Aの「Metrics browser」の欄に以下の関数を入力する
avg(rate(node_cpu_seconds_total{instance="client1:9100"}[1m]))
↑ 「あるインスタンス("client1:9100")の直近1分間のCPU使用率の平均値」という意味

instance=""の文字列には監視したいサーバーのインスタンス名(prometheusで設定したインスタンス名)を記載する
1.2 「B.アラート発生の境界値設定」
Bでは、Aで設定したクエリ関数の値がいくつ以上になったらアラートを発生させるのかを設定する
Conditionsの欄に、「Aの指標(CPU使用率)の最新の値が0.8(80%)になったら」という意味で、
WHEN 「last()」 OF 「A」「IS ABOVE」「0.8」と設定した
0.8の部分は自由に値を変えられる
ここで、「Run queries」をクリックすると、現在のCPU使用率でアラート判定のテストが行える
Aの欄には設定したクエリ関数についてのグラフが、 B の欄には境界値以上か以下の判定結果が出力される[1]
以下の画像のように正しくA欄のグラフとB欄の判定が行えればOK
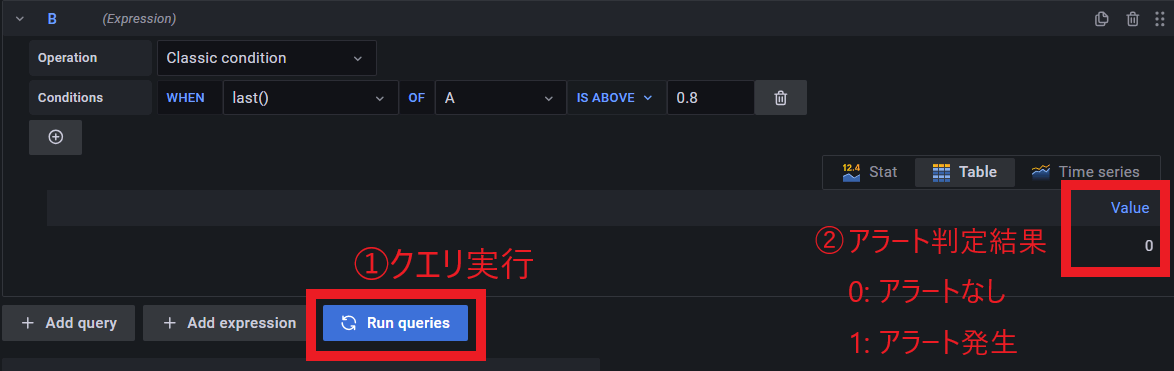
0はクエリ境界値以下でアラートなし、1はクエリ境界値以上でアラート発生
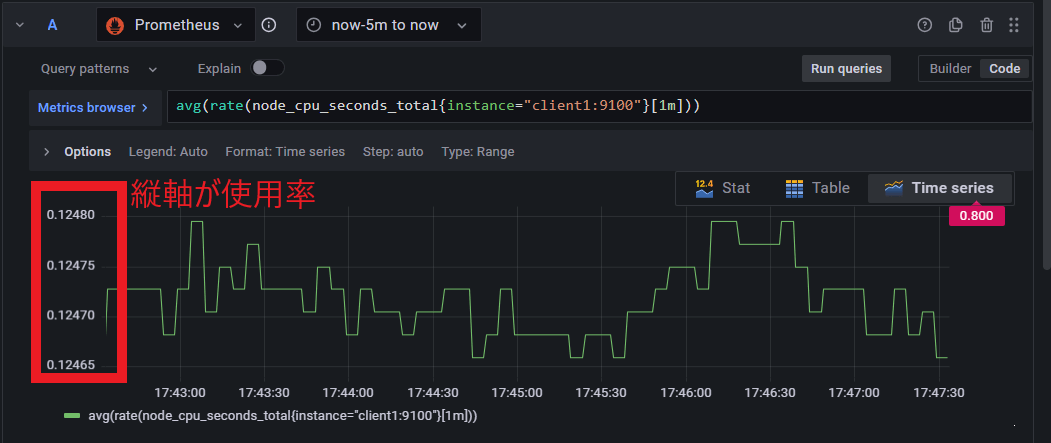
リソースに余裕のあるサーバーなら、おそらく0.1(10%)くらいになる
2 Alert evaluation behavior 設定
ここでは、1で設定したクエリ関数の実行結果を監視するタイミングについての設定を行います。
今回は、1分ごとにクエリを実行し、5分以上(5回以上)クエリ実行結果が境界値以上(1)であった場合に、あらかじめ設定されたアラート動作を行うように設定します。
(今回の場合はアラート動作はメール送信になります。)
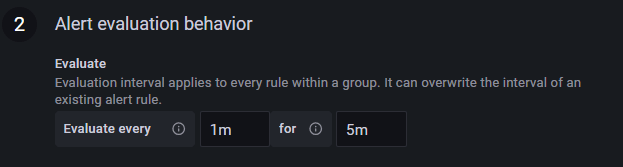
以下のように、Evaluate every (監視の実行間隔)には「 1m (1分ごと)」を指定する。
for (判定から発行までの待機時間)には「 5m (5分間)」を指定する
「Preview alerts」をクリックして、State「アラート発行状態」が「Normal」や「Alerting」など表示されることを確認する


3 Add details for your alert 設定
ここでは、ルール名やルールを保存するフォルダ等の設定をします。
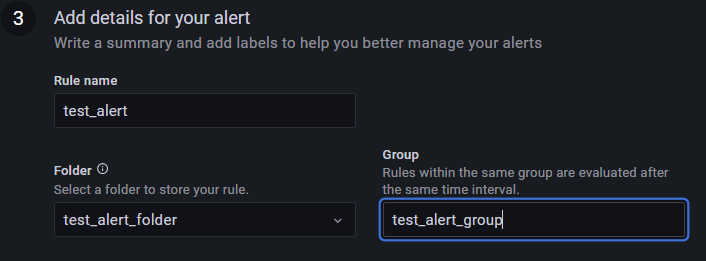
Rule nameには今回は「test_alert」を設定する
Folderはルールを保存先フォルダであり、最初は存在しないので「+Add new 」をクリックし今回は「 test_alert_folder 」フォルダを新規作成する
valuation group には今回は「 test_alert_group 」と入力する
その下にメール通知先のNotifications設定があるが、一旦空欄で画面右上の「Save」をクリックしてアラートルールを保存する
4. 一旦動作確認
アラートルール一覧の画面に戻り、以下のように新しいフォルダ「test_alert_folder」と、その中にtest_alertという名前のアラートルールが表示されていることを確認する
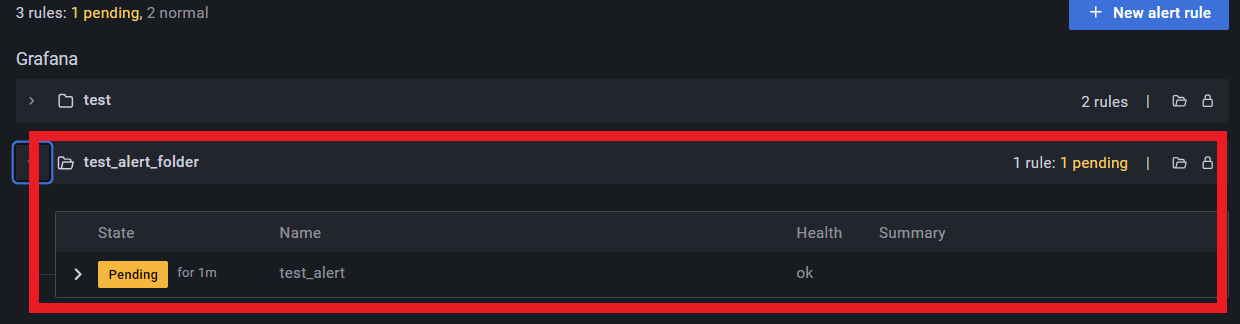
画像はあえて境界値を小さくしたので最初からPending(アラート作動待機)となっている
この状態が設定した5分間継続したらFiringとなりアラートメールが送信される
今回はNormalと表示されていればOK
5. アラートメッセージ送信先の登録
現段階ではこのアラート発生時の通知先を何も登録していないので、通知先を登録する設定を行います。
左メニューの「Contact points」をクリック
画面右の「+ New contact point 」をクリック
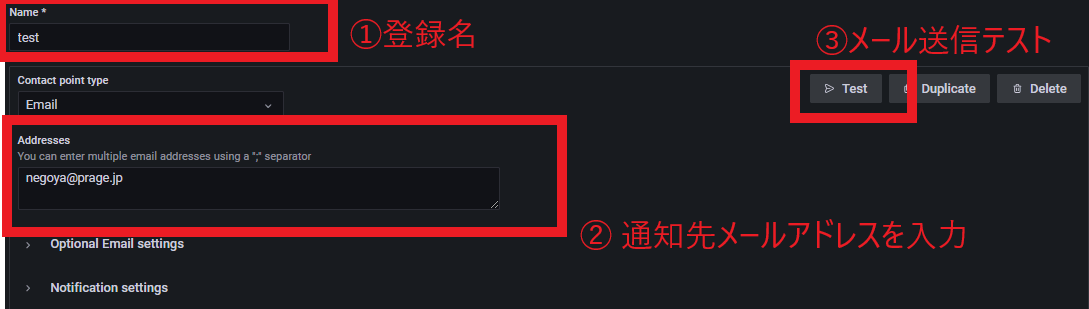
①通知先名、②メールアドレスを入力し、③送信テストをしてGrafanaからメールを送信できるか確認する
※ ここでメールが送信できない場合、以下を参考にGrafanaのメール送信設定を修正する必要あり
6. アラートメッセージ送信先設定
今登録したアラートメッセージ送信先とラベルを紐づける
「 Alerting 」から「 Notification policies 」を選択
「 + New policy 」をクリックして新規ポリシー作成

Contact pointに先ほど作成した通知先名を指定し、「save policy」をクリックして保存する
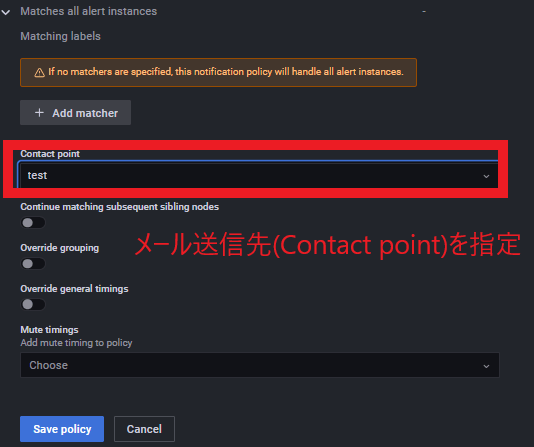
この設定で、すべてのインスタンスのアラートがここで指定したメールに送信される
7. アラートメール送信テスト
実際にCPU使用率を上げ、アラートを発生させてメールが送信されるか確認する
監視対象のサーバーで以下のように不可をかけてサーバーのCPU使用率を高くするとアラートを出しやすい
[testuser@testhost ~]$ yes > /dev/null
Alert rulesを確認し、不可をかけて1分以内にステータスが「Pending」に変化しているのを確認する
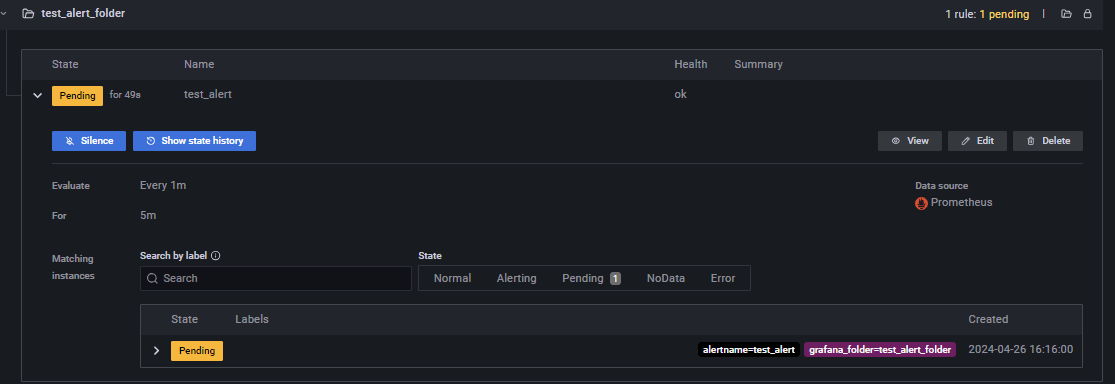
このまま5分たつと、状態が「Firing」になり、指定した通知先名にメールが送信されるのでメールを確認する
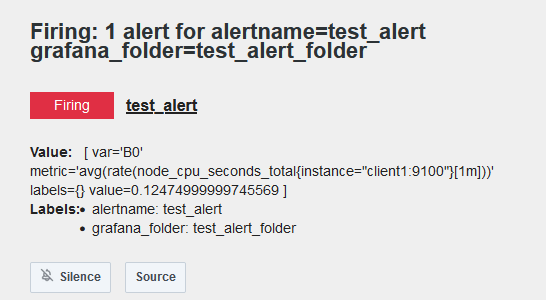
このようなメールが届く
8. 補足
本記事ではCPU使用率のメトリクスについての設定方法について記載しましたが、
「# 1. Set a query and alert condition 設定」のAのクエリ関数を変更すれば、メモリやディスク使用率等あらゆるリソースについてアラートを出せます
以下いくつかの指標の設定例(Aのクエリをこれにして、「Run queries」を実行してみてください)
使用率はCPUと同じく0.0~1.0の範囲です
・client1:9100のメモリ使用率(現在の使用率)
1 - (node_memory_MemAvailable_bytes{instance="client1:9100"} / node_memory_MemTotal_bytes{instance="client1:9100"}
・client1:9100のディスク使用率(/dev/vda2の使用率)
device="/dev/vda2"を抜いて実行すると他の監視中ディレクトリも確認できます
1 - node_filesystem_avail_bytes{instance="client1:9100",device="/dev/vda2"} / node_filesystem_size_bytes{instance="client1:9100",device="/dev/vda2"}
Dashboardも同じPrometheusクエリで動作しているのでダッシュボードの編集画面からも色々なクエリを確認することができます
-
正しく境界値やアラート発生のが設定できているか不安な場合は、Bの「IS ABOVE」以降の値を0もしくは0.01のように極端に小さい値にすると必ず境界値以上になるので、値を変化させて動作を確認するのもよい ↩︎
Discussion