GeminiAPIで作るマルチモーダルチャットアプリ
概要
Gemini APIを利用して、デスクトップ上で動作するチャットアプリを作成しました!
この記事では使用した技術を簡単に紹介します。
機能
- GUI上で、チャット形式で会話が行える
- メッセージ送信と同時にPCのスクリーンショットも入力に使用する(マルチモーダル)
- これまでの会話履歴を保存する
- テキスト、音声での回答

デモ動画
GitHub
技術構成
FletでGUIを作る
実装はすべてPythonで、デスクトップでの動作にはFletというフレームワークを使用しています。
サンプルが充実しており、その中から「Chat」というサンプルコードをもとにして、自分好みに見た目を整えました。
Gemini APIでチャットを始める
会話相手はGeminiを選びました。
Google AI StudioでAPIキーを発行した後、すぐにGemini APIを利用できます。
挙動を試すだけなら以下のコードで確認ができます。(Gemini API クイックスタートより)
import google.generativeai as genai
import os
# モデルの初期化
genai.configure(api_key=os.environ["API_KEY"])
model = genai.GenerativeModel('gemini-1.5-flash')
# テキストの生成
response = model.generate_content("Write a story about a AI and magic")
print(response.text)
各言語別のチュートリアルページもあります。
マルチモーダルに対応する
マルチモーダル入力はテキストだけの生成と同じ、GenerativeModel.generate_contentメソッドで実現できます。
たとえば画像を説明してもらうプロンプトは以下のようになります。

マルチモーダルの例もチュートリアルページに記載されています。
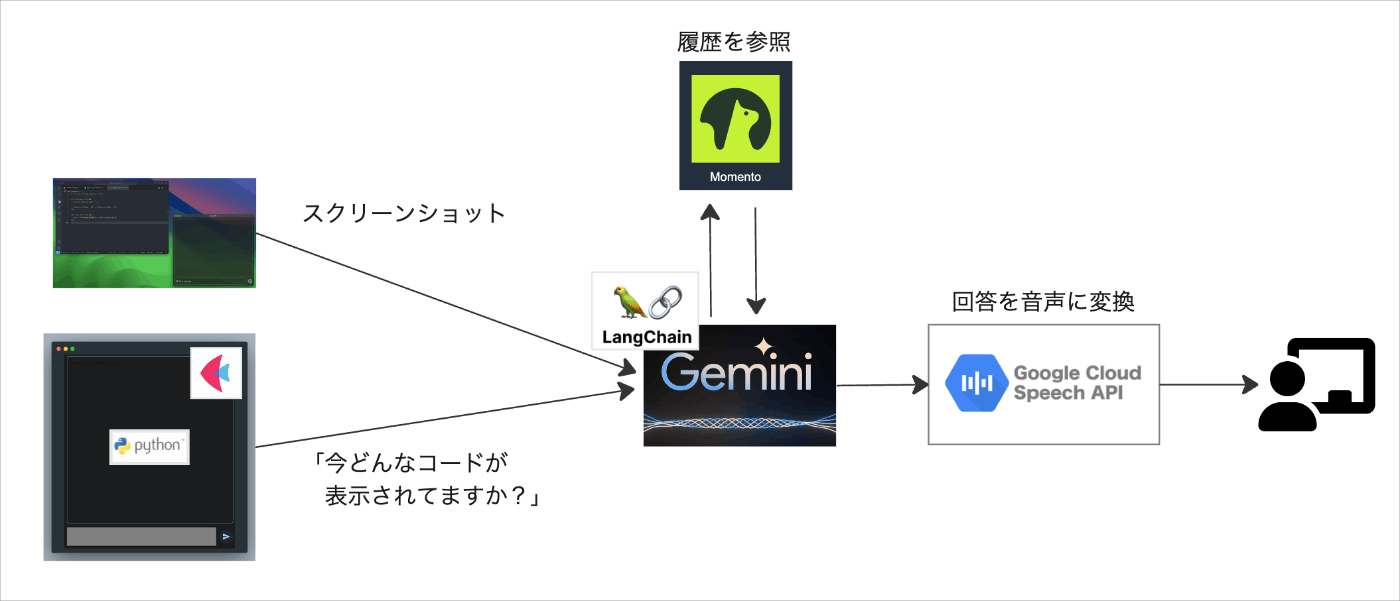
本アプリケーションでは、テキストの送信と同時にPC画面のスクリーンショットを撮影・入力しています。
会話履歴を保存する
LLMをAPIで利用する場合、ステートレスであるため過去の会話履歴を覚えていません。
そのためMomentoを利用して会話履歴をキャッシュしています。
本アプリケーションではLangChainからMomento Cacheを利用しています。
Geminiの返答を履歴に追加し、ユーザーが入力を行うときにこれまでの会話履歴を一緒に入力しています。これにより過去の情報をもとに回答を返してくれます。
音声でも回答してもらう
Geminiの返答をチャット欄に表示すると同時に、GoogleのText-to-Speechを利用して音声ファイルを作成・再生することで音声回答を行っています。
こちらも各言語別のチュートリアルページがあります。
ja-JP-Standard-Dという種類の音声を利用しました。
voice = texttospeech.VoiceSelectionParams(
language_code="ja-JP",
name="ja-JP-Standard-D",
ssml_gender=texttospeech.SsmlVoiceGender.MALE,
)
audio_config = texttospeech.AudioConfig(audio_encoding=texttospeech.AudioEncoding.MP3)
以下ページにて、利用できる音声のサンプルを聞けます。
料金
ここまで紹介した技術は、制限が来るまでは無料で利用できます。
- Gemini
- 無料
- Momento Cache
- 毎月最初の5GBまでは無料で利用できます。(料金表)
- Google Text-to-Speech
- 音声には種類があり、「Standard voices」という種類では400万文字までは無料で利用できます。(料金表)
最後に
Gemini APIを利用してアプリケーションを作成するなかで、最初想像していたよりもさまざまなことが実現できるなと感じました。
生成AIでできることは日に日に増えているので、この先も拡張・改善を続けていきたいな とわくわくしています!
Discussion