はじめに
ポートでインフラ・SREを担当している @tomoyuki.hori です。
ポートが運営している就活会議というサービスのインフラは、主にECSを使ったコンテナ環境で構築、その監視にDatadogを導入しています。
Datadogは使用していたものの、運用監視の仕組みがまだまだ改善の余地があったため、構築と改善を行ったことを紹介します。
構築前の状況

- 監視項目はあるものの、タグなどでカテゴリー化されておらず、どこに何があるか整理されていなかった
- Monitor(モニター)やダッシュボードは本番環境のみリソース監視でステージングはなし
- 数年前にGUI(コンソール上の設定)で作成されていたMonitorのクエリの見直しの必要があり
現状では、本番環境のみの運用監視であったため、ステージング環境のリソースも監視できるようにしました。
そして今後の運用のことを考え、作成者以外のエンジニアもメンテナンス・オペレーションできるようTerraformでIaC化を行いました。
目的
- Monitor監視とダッシュボード整備によってECSやその他リソースを包括的に監視できる仕組みを構築する
- タグの整備によってモニタリングの可視性を高める
- Monitor(モニター)やダッシュボード本番環境とステージング環境を同じ画面で閲覧、かつ環境別にアラート通知できるようにする
- Terraformを用いてコード化、本番とステージングの両環境の構成管理を自動化、他のサービス監視にも利用できるような再利用性を高める
【前提条件1】 Datadog Provider導入
以下のようにTerraformのDatadog Providerを導入します。
バージョンについては以下の通り
Terraform = v1.4.6
Datadog Provider = latest
terraform {
required_providers {
datadog = {
source = "DataDog/datadog"
}
}
}
provider "datadog" {
api_key = <datadog_api_key>
app_key = <datadog_app_key>
}
api_keyとapp_keyはDatadogのOrganizations Settingsから取得が可能です。
取得したkeyはそのまま記述するのではなく、暗号化や環境変数化するなどする必要があります。
【前提条件2】 AWS Integrationの設定
ECS on Fargateのメトリクスを取得するので、IntegrationsでFargateを選択して、
連携させるひつようがあります。

1. Datadogタグを使う
Datadogで扱うタグはいくつかありますが、今回はエージェントタグを付与します。
弊社サービスはECSコンテナで動いているので、コンテナに対してDatadogエージェントを導入することで、タグを設定することができます。
Datadogタグの目的
タグを使用する目的は以下です。
-
モニタリング監視の可視性向上:
リソースにタグをつけて、カテゴリー化することによって可視性を高める。例えば”production"タグを持つリソースを表示することで、本番環境のリソースに絞って一覧を確認することができる -
アラートの作成と通知のカスタマイズ:
タグを使用してアラートを作成することができる。例えば"production"と"staging"タグをコンテナに付与し、環境毎で通知の割り振りができるようになる。”staging”で障害が発生したら、staging用のSlackチャンネルに通知させることができる -
ダッシュボードの作成とカスタマイズ:
タグを使用することで、特定のタグに関連するリソースのメトリクスやイベントをまとめたダッシュボードを作成。これにより、本番・STGの環境毎やサービス毎に一つのダッシュボードで監視し、関連するデータを視覚化することができる
エージェントタグはデフォルトで、/etc/datadog-agent/datadog.yamlとなってますが、ECSタスク定義でも設定可能です。
付与するタグとしては以下2つ
・ serviceタグ
・ envタグ
Datadogの中では、envとserviceは予約済タグとして扱われます。
envについてはproductionとstagingに分けて、両環境にタグづけできます。
Datadogエージェント導入
タグを導入するにあたり前準備が必要となります。
以下のDocsを参考にAWS ECS on Fargate 内でDatadogのコンテナエージェントをインストールします。
Datadog Agent バージョン 6.1.1 以降が必要とのこと。
- コンテナ名に
datadog-agentなどdatadogのコンテナだと分かるように記入 - タスク定義にエージェントのイメージを指定

タスク定義のjsonファイルを使用してもOKです。
{
"containerDefinitions": [
"name": "datadog-agent",
"image": "datadog/agent:7",
"environment": [
~
]
}
コンテナ環境変数追加
実際にタグを追加する作業になります。
以下のように環境変数を追加します。(GUIでもOK)
ECS タスク定義の場合
"environment": [
{
"name": "ECS_FARGATE",
"value": "true"
},
{
"name": "DD_ENV",
"value": "production"
},
{
"name": "DD_SERVICE",
"value": "<service_name>"
},
],
もしくはこのような方法でもOK
"environment": [
{
"name": "ECS_FARGATE",
"value": "true"
},
{
"name": "DD_TAGS",
"value": "env:production service:<service_name>"
}
],
タグが使えるようになる
上記の設定を行った後、メトリクスのタグなどで使えるようになります。
以下のようにenv:productionとenv:stagingのようにタグを取得できています。
これによって本番とステージング両方のリソースのデータを個別に取得・閲覧が可能となりました。

2. Datadog Monitor(モニター)
Datadog Monitor(モニター)でCPUやメモリの監視などリソースのメトリクス、タグを指定して、細かく分析ができます。
また、Datadog Monitor(モニター)はメールやSlackなどの通知チャネルを指定でき、送信できる機能も備わっています。
工夫ポイント
Datadog Monitor(モニター)の設定では以下のポイントに注力しています。
- 既存のメトリクス・クエリの見直し
- 一つのMonitorで本番とステージング両方を監視できるように設定
- アラート通知は本番は本番のSlackチャネルと、環境毎に通知されるフローを作成する
- そのSlackに流れるアラート通知内容が誰が見ても分かりやすいようにする
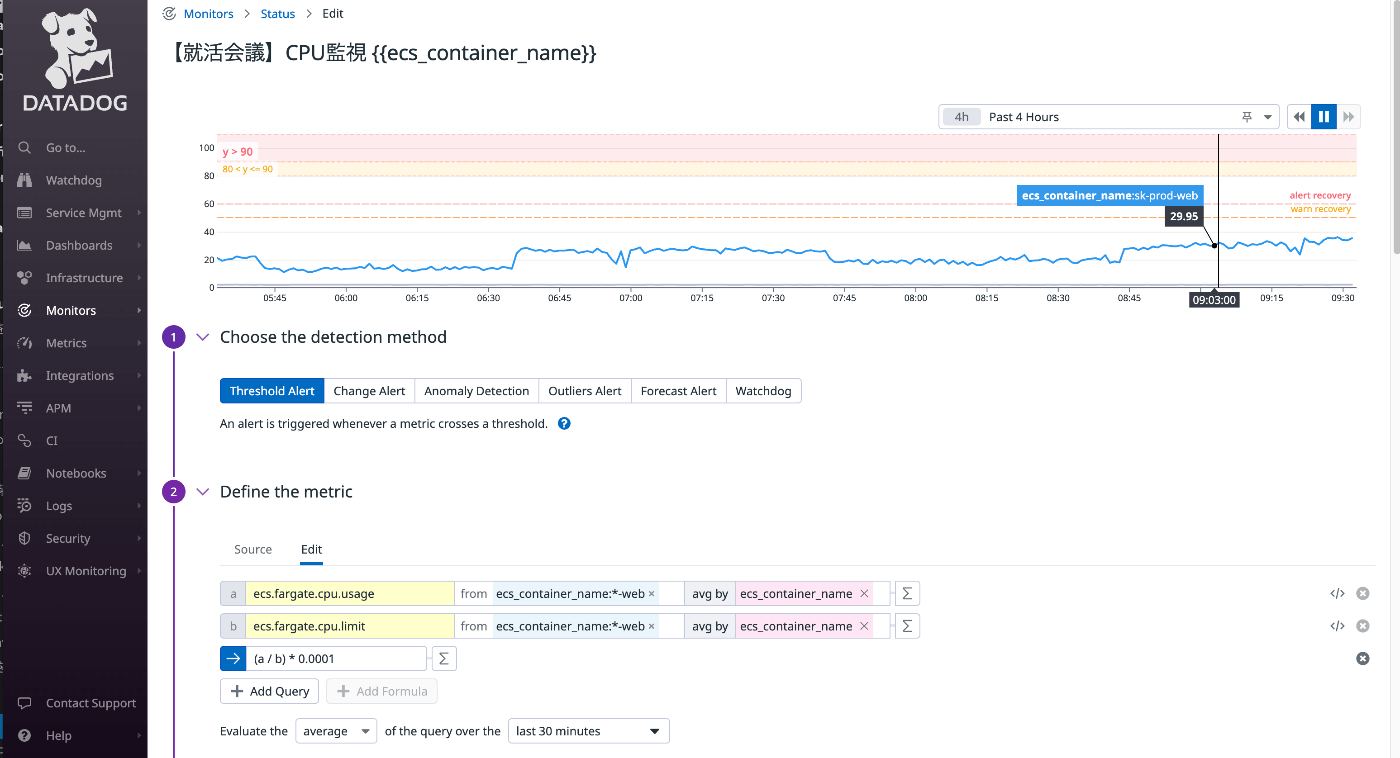
Datadog Monitor(モニター)のCPU監視を例に

例としてCPU監視をあげます。
Terraformで書くと以下のようになりました。
resource "datadog_monitor" "container_web_cpu_utilization" {
evaluation_delay = 0
include_tags = true
message = <<-EOT
{{#is_match "ecs_container_name.name" "prod"}}
### アラート内容
{{#is_warning}}
- {{ecs_container_name}} のCPU使用率80%超過
{{/is_warning}}
{{#is_alert}}
- {{ecs_container_name}} のCPU使用率90%超過
{{/is_alert}}
### 対応
- AWSコンソールよりECSの{{ecs_container_name}}コンテナの状態を確認し、CPU使用率上昇の原因を特定すること
https://ap-northeast-1.console.aws.amazon.com/ecs/v2/clusters/syukatsu-kaigi-jp/tasks?region=ap-northeast-1
### 通知先
@slack-production-channel
{{/is_match}}
{{#is_match "ecs_container_name.name" "stg"}}
### アラート内容
{{#is_warning}}
- {{ecs_container_name}} のCPU使用率80%超過
{{/is_warning}}
{{#is_alert}}
- {{ecs_container_name}} のCPU使用率90%超過
{{/is_alert}}
### 対応
- AWSコンソールよりECSの{{ecs_container_name}}コンテナの状態を確認し、CPU使用率上昇の原因を特定すること
https://us-west-2.console.aws.amazon.com/ecs/v2/clusters/syukatsu-kaigi-stg-jp/tasks?region=us-west-2
### 通知先
@slack-staging-channel
{{/is_match}}
EOT
name = "CPU監視 {{ecs_container_name}}"
new_group_delay = 0
no_data_timeframe = 0
notify_audit = false
notify_by = []
notify_no_data = false
priority = 0
query = "avg(last_30m):(avg:ecs.fargate.cpu.usage{ecs_container_name:*-container} by {ecs_container_name} / avg:ecs.fargate.cpu.limit{ecs_container_name:*-container} by {ecs_container_name}) * 0.0001 > 90"
renotify_interval = 20
renotify_occurrences = 0
require_full_window = true
tags = [
"service:<service_name>"
]
timeout_h = 0
type = "query alert"
monitor_thresholds {
critical = "90"
critical_recovery = "60"
warning = "80"
warning_recovery = "50"
}
}
ポイントとしてはmessageとqueryの部分です。
Datadog Monitor(モニター)のmessage
messageの部分はヒアドキュメントで記述していますが、
ポイントとしては、変数を使用した条件分岐の記述をしている点です。
Datadogにはis_matchという変数を使用して以下のように条件分岐の記述が可能です。
{{#is_match "<タグ変数>.name" "<比較文字列>"}}
これは、<比較文字列> が <タグ変数> に含まれている場合に表示されます。
{{/is_match}}
今回の場合は<タグ変数>にecs_container_name、<比較文字列>をprodとしています。
これはメトリクス検知したタグ変数名にprodという文字列が含まれていたら、条件に書かれている処理を行うという意味です。
ECSのコンテナ名にprodとstgが含まれており、それぞれどちらかのコンテナが閾値を超えたら、環境別にSlack通知される仕組みです。
ちなみに上記では、is_warningとis_alertで閾値がcritical 90%とwarning 80%を超えた場合でも条件分岐をしているので、
Datadogのmessage変数は柔軟に使用できます。
あとは、messageの内容を詳しく書いて、対処方法なども加えてあげると、誰が見ても「何が起こっているか」「何をすればよいか」がわかって親切かなと思います。
Datadog Monitor(モニター)のquery
queryの部分は、ワイルドカードを使用しており、prodとstg両方のメトリクス検知を可能にしています。
以下の記述はコンテナのCPU使用量を取得しています。
avg:ecs.fargate.cpu.usage{ecs_container_name:*-container} by {ecs_container_name}
上記で、コンテナ名であるprod-containerとstg-containerがあったとすると、
両方のCPU使用量をデータとして取得し、モニタリングが可能となります。
以下のようにprodとstg両方のコンテナのメトリクスを取得しています。
ちなみに
以下の記述のタグは、あくまでMonitorに付与するタグのことで、
Datadogタグとはまた用途が違います。
Monitorの監視項目を複数作成するため、分かりやすいようにカテゴリー化しています。
tags = [
"service:サービス名"
]
3. Datadog Dashboard(ダッシュボード)
最後にDatadog Dashboard(ダッシュボード)の構築について紹介します。
今回作成した作成したダッシュボード
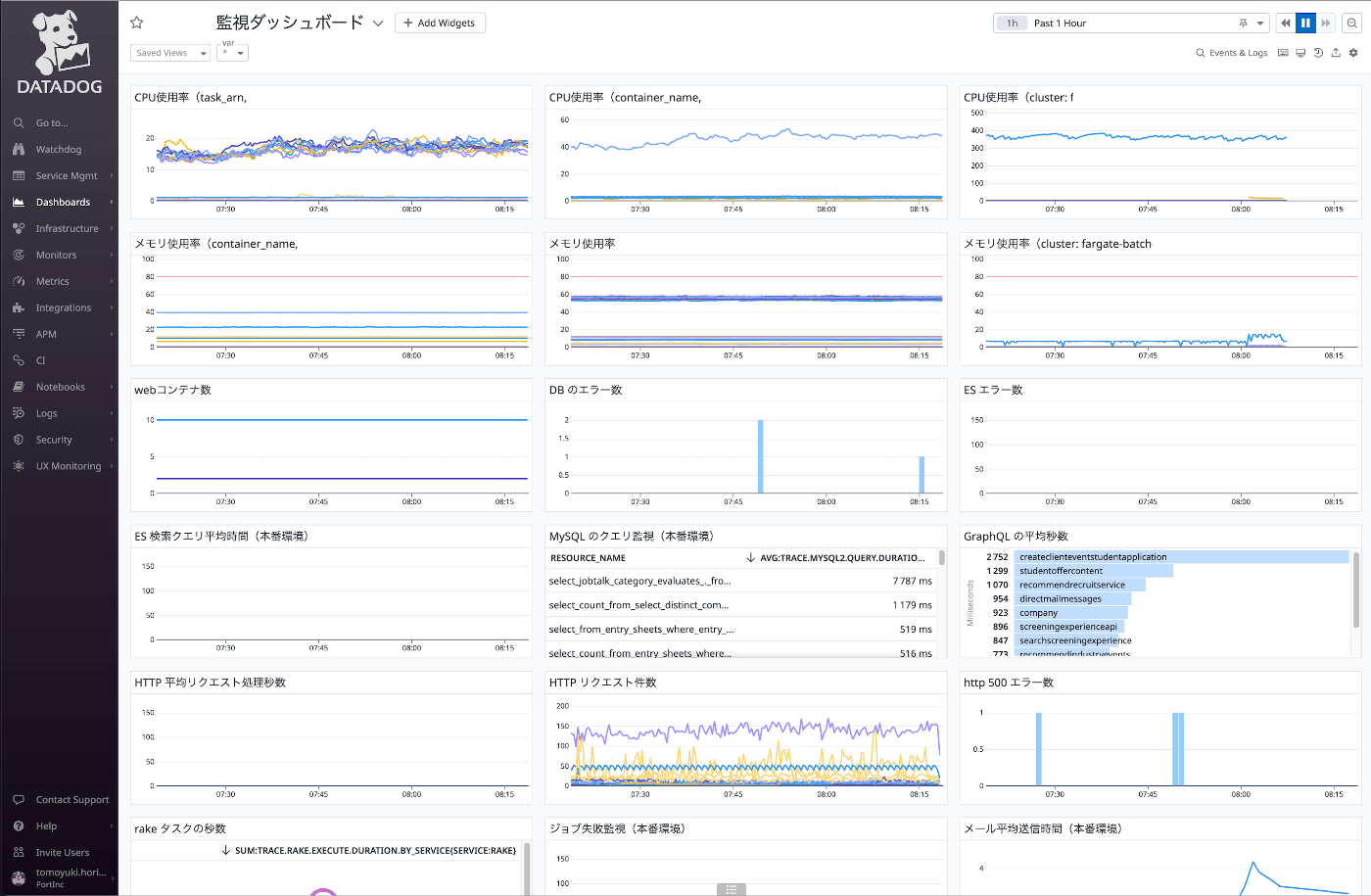
主な項目としては
- コンテナのCPU・メモリ等のリソース監視(クラスター、タスクID、コンテナ名ごとに細かく分離)
- DBのエラー数、ディスク読み取り回数
- ALBのレスポンスタイム、エラー数
ダッシュボードに関してもTerraformで管理することができます。
resource "datadog_dashboard" "dashboard_name" {
title = "監視ダッシュボード"
restricted_roles = ["ロールID"]
reflow_type = "auto"
layout_type = "ordered"
template_variable {
defaults = ["*"]
name = "var"
}
widget {
timeseries_definition {
legend_columns = [
"avg",
"max",
"min",
"sum",
"value",
]
legend_layout = "auto"
show_legend = false
title = "メモリ使用率(container_name, cluster: cluster-name-*)"
marker {
display_type = "error solid"
value = "y = 80"
}
request {
display_type = "line"
on_right_yaxis = false
formula {
formula_expression = "(query1 / query2) * 100"
}
query {
metric_query {
data_source = "metrics"
name = "query1"
query = "avg:ecs.fargate.mem.usage{ecs_container_name:*-container,cluster_name:cluster-name-*} by {container_name}"
}
}
query {
metric_query {
data_source = "metrics"
name = "query2"
query = "avg:ecs.fargate.mem.hierarchical_memory_limit{ecs_container_name:*-container,cluster_name:cluster-name-*} by {container_name}"
}
}
style {
line_type = "solid"
line_width = "normal"
palette = "dog_classic"
}
}
yaxis {
include_zero = true
max = "auto"
min = "auto"
scale = "linear"
}
}
}
}
widget(ウィジェット)はたくさんあるので、1つだけ提示しています。
ウィジェットのレイアウトなどかなり細かく設定できるので、便利だと思います。
最後に
今回はポート社のDatadogとTerraformを使った運用監視の仕組み構築について紹介しました。
やってみての所感
- タグを設定することによって監視項目が綺麗にカテゴリー化されて、みやすくて扱いやすくなった
- やはりIaC化は中長期的な運用を考えるとすごく便利
- DatadogはUI/UXに優れて柔軟に使えて最高
といったように手前味噌ですが、非常に満足いくようになりました。
特にTerraformでIaC化することで、新しい項目を追加したいとか、別のアカウントにも再利用したりとかの場面に、すごく便利だと思います。

ポート株式会社は、「社会的負債を、次世代の可能性に。」をパーパスに掲げ、人材領域およびエネルギー領域を主力事業とした事業を展開しています。人材領域では、「キャリアパーク!」「就活会議」「みん就」などのサービスを提供しています。
Discussion