はじめに
ポートのSREを担当している @taiki.noda です。
弊社で実施しているインフラ勉強会でDatadog社が出している『クラウド時代のサーバー&インフラ監視』を読んでまとめたので、紹介します。
『クラウド時代のサーバー&インフラ監視』はこちらからダウンロードできます。
第1章:絶えざる変化
クラウドへの移行は、運用についても根本的な変化をもたらしました。現在はインフラストラクチャが動的で絶えず変化する時代であり、監視についても新しいツールや手法が求められています。
- クラウドの登場によりインフラストラクチャ、アプリケーションが複雑で動的なものになっている
- インフラストラクチャの変化に伴い、インフラストラクチャのユニット数、変更頻度、関係するエンジニア数、監視されるツールとサービスの数、も増加している

弾力的、動的、そしてエフェメラル(短命)になるインフラストラクチャ
- 無限のクラウドリソースをオンデマンドで素早く利用できるようになったため、現在のインフラストラクチャは弾力的であり、エフェメラル(短命)になっている
ペットと家畜の違い
動的なインフラストラクチャでは、個別のサーバーに着目してもあまり意味はありません。 各コンピュートインスタンスやコンテナは、大規模なサービスをサポートする機能を実行 するための単なる交換可能な歯車に過ぎません。
- よく用いられる比喩で、ペットは名前があって特別なもの。家畜は群れの一部で、個体よりも群全体の健康が重要になる
- インフラストラクチャのコンポーネントは家畜として考える必要があり、既存のホストレベルに焦点を当てるのではなく、サービスとして捉えることが重要
DevOps
「DevOps」では、開発チームと運用チーム間の緊密なコラボレーションが非常に重要に なり、開発、展開、運用の段階を通じて両方のチームがサービスに携わります。DevOps では、ソフトウェアを効率的かつ安全にテスト、展開、および管理できように、コミュニケー ション、コラボレーション、再現性、および自動化に重点が置かれます。
継続的デリバリ
- 変更内容を簡単かつ自動的にテストできるようになる
- バグ修正、新機能を早くリリースできる
- 迅速にロールバックできる
可観測性
- 可観測性とはインフラストラクチャ、アプリケーションのすべてのコンポーネントのメトリクスを測定し、すべての情報を一元化して運用の全体像を再現できることを意味する
監視におけるモダンなアプローチ
モダンな監視システムに求められる最重要機能について要件が書かれている
集計機能の組み込み
- タグやラベルを使用し、メトリクスをセグメント化して集計
- ホストレベルではなくサービスレベルで問題を捉えることができる
包括的な監視対象
- インフラストラクチャのすべてのレイヤーを監視する
- メトリクス間での相関により、サービス間の相互作用を把握できる
スケーラビリティ
- インフラストラクチャが拡張・縮小されるときに動的に検知して自動的に監視を開始する
高度なアラート作成
- 高度な監視システムでは、柔軟性のあるアラートが提供される
- 相対的変化についてのアラート
- 外れ値と異常値の自動検出
- ベースラインの変化に対する柔軟なアラート
コラボレーション
- エンジニアが迅速に問題を発見、修正できるようにする必要がある
- コミュニケーションチャンネルとの連携
第2章:優れたデータを収集せよ
以下を実現するために、データの分類とその用途を説明している
- 不要なアラートを抑えつつ、潜在的な問題を知らせるアラートを自動的に生成する
- 迅速な調査を可能にして、パフォーマンスの問題の原因を特定する
メトリクス
- 特定の時点におけるシステム関連の値
- 以下3つの項目に分類している
- ワークメトリクス
- リソースメトリクス
- イベント

ワークメトリクス
- システムのトップレベルのヘルスを示す
- 次の4つのサブタイプに分類すると便利
-
スループット
- ある時間単位で実行している作業量
-
成功
- 正常に実行した作業の割合
-
エラー
- エラーになった結果数
- 他のメトリクスよりも重大な意味を持ち、対策がすぐに必要となるものがある
- エラーになった結果数
-
パフォーマンス
- コンポーネントが処理をどれほど効率的に実行しているかの定量的な指標
-
スループット

リソースメトリクス
- サーバーのリソースにはCPUなどの物理コンポーネントがある
- データベースなどの上位レベルのコンポーネントも、他のシステムがそのコンポーネントを要求する場合もリソースとして捉えることができる
- システムの各リソースについては次の4つの領域をカバーするメトリクスを収集する
-
使用率
- 使用されているリソースキャパシティの割合
-
サチュレーション
- リソースが処理できていない作業量
-
エラー
- 内部エラー
-
可用性
- リソースが要求に応答した時間の割合
-
使用率

その他のメトリクス
- ワークでもリソースでもないメトリクスも原因調査に役に立つ場合がある
- キャッシュヒット率やデータベースロック数
イベント
- 変更、アラート、スケーリングイベントなど
タグ付け
- 現在のインフラストラクチャは常に流動的
- 一時的な変化の全データを監視対象にすると、SN比(信号雑音比)が非常に低くなる場合がある
- タグを使用することで、複数ホストの集計パフォーマンスを監視できる
メトリクスタグとは?

監視のためのより良いデータとは
- 収集すべきデータには、4つの特徴がある
簡単に理解できる
- 素早く判断できる必要がある
粒度
- メトリクス収集頻度が低すぎたり高すぎると、有意なデータが得られなくなる場合がある
スコープ別のタグ付
- データと複数のスコープを関連付けて保持することが大切
長期間の保持
- あまりにも早い段階でデータを破棄すると、過去に何が起こったのかを示す重要な情報が失われる
すべてを収集する
要点についてまとめている
- すべてを計測し、合理的な範囲でできる限り多くのワークメトリクス、リソースメトリクス、イベントを収集する
- 急激な増加・減少を把握できるように十分な粒度でメトリクスを収集する
- 適切な範囲でメトリクスとイベントにタグをつけ、少なくとも1年間は保持する
第3章:本当に重要な問題についてアラートを発行する
- アラートは原因を迅速に特定し、サービスの中断を最小限に抑えることができる
- しかし、アラートが常に効果的であるとは限らない。
- 例えば、大量の誤ったアラートに本当の問題が埋もれてしまう
アラートの緊急レベル
記録するアラート(重大度が低い場合)
- 介入しなくても解決されることが多い
- 将来的に参照または調査する時に利用できる
通知するアラート(重大度が中程度の場合)
- 介入が必要だが、すぐに対応する必要はない
- メールを送信するか、チャットで通知するのが良い
緊急メッセージを送信するアラート(重大度が高い場合)
- 発生した時間に関わらず、即時対応が必要となる
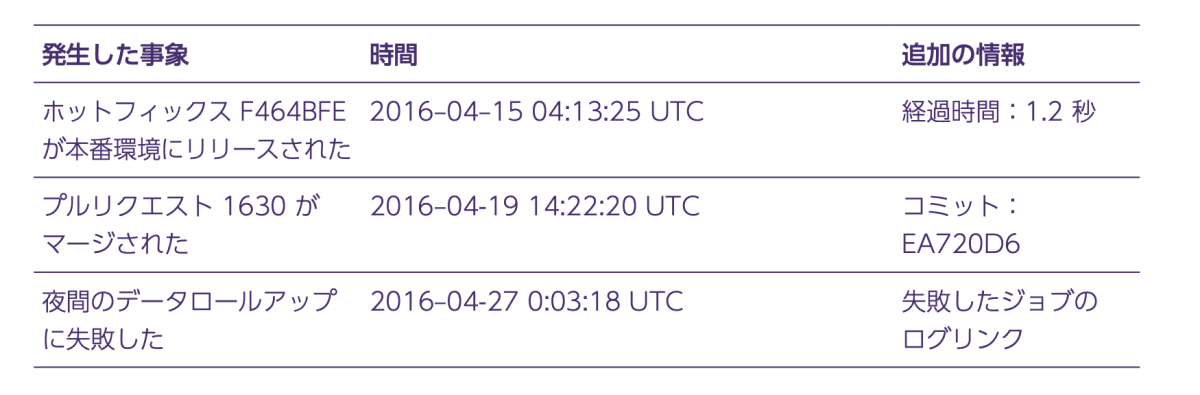
アラートのためのデータと診断のためのデータ
- 以下の表は、前章で説明したさまざまなデータタイプの例をさまざまなレベルのアラート 緊急度にマッピングしたもの

アラート緊急度の設定方法
- これは本当に問題か?
- 問題にならない事象で目立つアラートや緊急メッセージを送信すると、本当に深刻な問題が見過ごされる恐れがある
- この問題に対する注意は必要か?
- この問題は緊急か?
症状に関する緊急メッセージ
- 原因ではなく症状に基づいて緊急メッセージを作成する
- 症状
- Webサイトの直近の3分間の反応が非常に低速である
- 考えられる原因
- データベースのレイテンシが高い
- アプリケー ションサーバーで障害が発生した
- Memcached がダウンした
- 負荷が高い etc.
- 症状
- 内部的な問題が起きていても、Webサイトが素早く応答しているのであれば、ユーザーはサーバーの負荷を気にすることはない
長期間継続するアラートの定義
- 症状に基づいて緊急メッセージを作成すれば、バックエンドのシステムアーキテクチャがどのように変わっても、システムが正常に機能しなくなった場合は、アラート定義を更新しなくても適切な緊急メッセージを受け取ることができる
このルールの例外:早期警戒のサイン
- いくつかのメトリクスについては早期警戒しないといけないものがある
- 深刻な症状が今後すぐに発生し、緊急介入が必要となるような、許容できない問題が発生する可能性が高いことを示す
- 典型的な例としては、ディスク容量
- ディスク容量が不足しているとシステムは回復しない恐れがあり、わずか数秒でシステムが完全に停止してしまう場合も多くある
- ディスク容量が低下する状況を予測し、ログや他の場所にあるデータなど、データを削除することで、自動的な対策を構築する
"症状"について真剣に捉える
本章の要点についてまとめている
- 緊急対応が必要となる問題の兆候が、システムの動作で検出された場合や、重大な問題および重要なリソースの上限に達しようとしている場合にのみ、緊急メッセージを送信する
- インフラストラクチャで実際の問題が検出される場合、これらの問題が全体のパフォーマンスに影響を与えていない場合であっても、必ずアラートは記録しておくように監視システムを設定する
第4章:パフォーマンス問題の調査
- 根本原因の診断は、監視システムで体系化が最も遅れている領域
- 根本原因を効率的に見つけて修正するために役立つ明 確な方向性を持ったアプローチについて説明する
データに関する復習
- 第2章の振り返りをしている
すべてはリソースと考えることができる
- 最上位レベルでは、処理を実施している各システムは他のシステムに依存している可能性がある

調査手順
- 問題が発生している可能性があることがアラートで通知されたら、次の手順を活用して、体系的 な調査を実施できる
- ワークメトリクスから最初に取り掛かる
- 最初に、初期段階で問題を明確に説明できるようにする
- 次に、問題が発生している最上位システムのワークメトリックを調査する
- 問題の原因を示したり、少なくとも調査の方向性を決定したりするために役立つ
- リソースの詳細な調査
- システムが使用しているリソース(物理リソース、およびシステムのリソースとして機能しているソフトウェアや外部サービス)を調べる
- 何かを変更したか?
- アラートとメトリクスと相関する可能性があるその他のイベントについ ても検討する
- コードリリース、内部アラート etc.
- アラートとメトリクスと相関する可能性があるその他のイベントについ ても検討する
- 修正する(そして忘れずに記録する)
- ワークメトリクスから最初に取り掛かる
必要となる前にダッシュボードを構築する

- 迅速に調査し、作業に集中するために、あらかじめダッシュボードを設定しておく
- 上位レベルのアプリケーションメトリクス用にダッシュボードを 1 つ設定
- サブシステム別にダッシュボードを 1 つ設定
- 各システムのダッシュボードは、そのシステム自体のリソースメトリクスとそのシステムが依存するサブシステムの主要なメトリクスと一緒に、そのシステムのワークメトリクスを表示できるようにする
- イベントデータを利用できる場合、関連するイベントをグラフに重ね合わせて、相関性を分析する
終わり
前編では4章までみていきました。
現代のインフラストラクチャの変化から、監視の変化について。
メトリクスの分類や、原因調査の手順などについて解説されていました。
後編ではグラフについてや、ELBやDockerなど具体的な監視対象をもとに何を考えれば良いのかについて、まとめていきます。
参考
クラウド時代のサーバー&インフラ監視 | John Matson, K Young
(画像、引用は全て『(クラウド時代のサーバー&インフラ監視 | John Matson, K Young)』から引用したものです。)

ポート株式会社は、「社会的負債を、次世代の可能性に。」をパーパスに掲げ、人材領域およびエネルギー領域を主力事業とした事業を展開しています。人材領域では、「キャリアパーク!」「就活会議」「みん就」などのサービスを提供しています。
Discussion