機械学習の勉強を始め、二カ月でkaggle銅メダルを取るまで
はじめに
先日、Kaggle - LLM Science Exam において169位/2662(top7%)で銅メダルを取ることができました。機械学習の勉強を始めてからここまでを簡単に振り返ってみようと思います。
機械学習の勉強を始めた経緯
現在、都内の大学院に通う修士一年です。工学部ですが、情報系専攻ではありません。プログラミングに関しては、大学ではC言語を少し勉強した程度で、主にインターンなどでPythonを勉強しました。就職活動を行う中でエンジニアに興味を持ち、その中でもデータサイエンティストに興味を持つようになりました。
しかし、自分はpandasを使ったデータ分析の経験が少しあるくらいで、AIや機械学習については、まったく勉強したことはありませんでした。そこで、どのように勉強しようか調べていく中で、KaggleやSIGNATEなどのデータ分析コンペティションの存在を知りました。ただ普通に勉強するだけでは面白くないので、コンペティションを通して機械学習の勉強をすることにしました。
機械学習の勉強を開始
コンペを始める前に、本を一冊だけ呼んで機械学習の基礎を勉強しました。 一週間くらいかけて一周し、機械学習とはどういうものなのか、重回帰や決定木、クラスタリングといった機械学習についての様々な言葉を初めて学びました。
SIGNATEに参加
いきなりKaggleから始めるのは難しそうだったので、まずはSIGNATEから始めてみることにしました。
最初に【第36回_Beginner限定コンペ】従業員の離職予測 に参加しました。
以下の記事を参考に、ChatGPTを使いながらコンペの一連の流れを勉強しました。
とりあえずこれで取り組み方が分かったので学生限定の懸賞付きコンペにチャレンジすることにしました。 中古自動車の情報(車種・走行距離など)をもとに、中古車の価格を予測するというコンペでした。
チームで参加できるコンペだったので、せっかくならチームで話しながら楽しくやりたいと思い、Xで募集を探し、チームを組みました。チームメンバーは全員分析コンペ初参加者でしたが、自分以外は情報系の専攻で、機械学習にとても詳しい方たちでした。分からないことは積極的にチームメンバーに聞き、適宜以下の書籍を参照しながらコンペに取り組みました。
最終的に提出した解法は以下の通りです。
前処理
- manufacturerの表記ゆれを修正(wagen,volkswagenをvolkswagenに統一など)
- yearが2023より大きいものは-1000する
- odometerが負のものと1e6以上のものをNaNに置き換え
- stateの欠損値をregionから決定
特徴量作成
- カテゴリ変数はtarget encoding
- odometerをビニング処理
- 数値を対数変換
- 特徴量重要度が高いもの同士を探索的にすべての組み合わせを試し、priceとの相関が高い、または特徴量重要度が高いものを残す
学習
- 1層目に3つのモデル、2層目に2つのモデルを使用したスタッキングモデル
- 使用モデルはすべてLightGBMで、それぞれハイパーパラメータを変更
しばらく10位台で停滞していましたが、最後にビニング処理を変更したことが効いてPublic LBは7位に浮上!金メダルが取れるかと思いきや、Private LBで転落し、最終的には16位/379(top4%)で銀メダルとなりました。いきなりメダルを取れたことは嬉しかったですが、金メダルが取れそうだっただけに、とても悔しい結果となりました、、
この後、SOTA ChallengeのSIGNATE Student Cup 2021春:楽曲のジャンル推定チャレンジ!!でSOTA銅メダルを取り、SIGNATE Expertに昇格しました。
kaggleに参加
機械学習の勉強を始めてから一か月ほど経ち、SIGNATEを通してコンペにも慣れてきたので、ついにKaggleにチャレンジすることにしました。テーブルデータコンペが良かったのですが、いいコンペが見つからなかったのでNLPのコンペに参加しました。 Wikipediaの科学に関する文章を元にGPT-3.5が作った多肢選択問題を限られた計算リソースで解くというコンペです。
SIGNATEで仲良くなったメンバーとまた同じチームを組み、参加しました。3ヵ月間のコンペでしたが、自分たちが参加した時点ですでにコンペ終了まで3週間しか残ってませんでした。
情報収集(終了まで残り3週間)
まずはOverviewやDiscussion,Datasetをじっくりと読むことに専念しました。自分たちはNLPに取り組むのは初めてだったので、スコアの高い公開notebookを試しながら勉強していきました。
方針策定(終了まで残り2週間)
ここでこれまでの順位を大きく塗り替えるnotebookが現れます。 このnotebookはそのまま実行しただけで銅メダルボーダー近くまで行きました。
これらのnotebookを使っていろいろな実験を行いながらチームで話し合い、何がスコアが上がる要因なのか、その中で自分たちでもできることは何なのかを考えていきました。
そして残り一週間で行うことを以下の二つに絞りました。
①学習Datasetの作成、変更
公開Notebookで使用されているdatasetは科学とは関係ない問題が多く含まれていました(例:Which of the following statements accurately describes Ray Montgomerie's football career?)。なのでもっとtrain dataに近い科学の問題を使って学習させればスコアが上がるのではないかと考えました。train dataはgpt3.5によって作られていたので、自分たちもgpt3.5の
apiを叩いて問題を作ることにしました。
②アンサンブル手法の検討
Discussionでは、PlatypusなどのLLMのモデルとDeBERTaを使っているモデルで分かれていました。推論時間の差やDiscussionでの情報の多さなどから、DeBERTaを使用したNotebookを元に改善を行うことにしました。[86.2] with only 270K articles!のNotebookの実験より、アンサンブルすることがスコア向上にかなり効いているのではないかと考えたので、いくつかのDeBERTaを使用したnotebookから使えそうなモデルを見つけてアンサンブルを行うことにしました。
チームで分担を決め、自分は②アンサンブル手法の検討を行うことにしました。
作業開始(終了まで残り1週間)
[86.2] with only 270K articles!のnotebookをaveragingのアンサンブルに変更することでLB0.873、LongFormerをDeBERTaに変更することで0.895に! ここで銅メダル圏内に入ることができました!
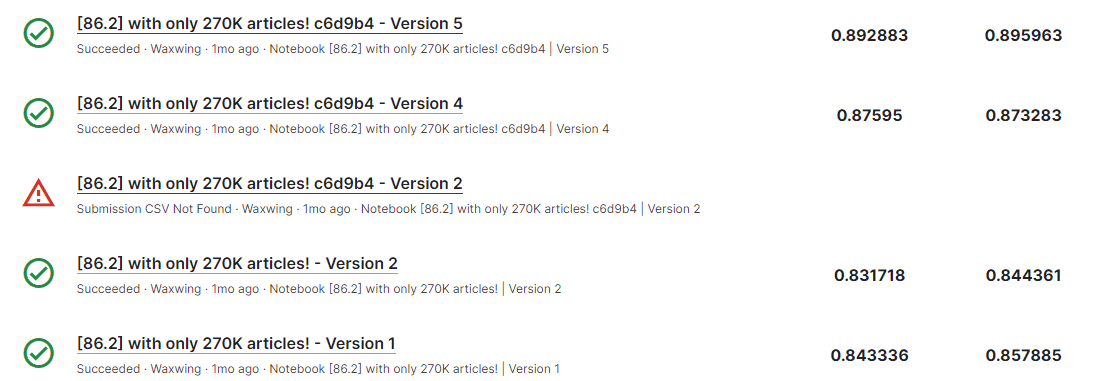
左がPrivate LB,右がPublic LB
しかし、さらなるアンサンブルを試そうとしますが、エラーが続いてしまいます。
解決方法を調べ、kaggle/workingのsubmission.csv以外を削除したり、modelを並列処理から直列処理に変更したりといろいろ試しますが、なかなか解決しません、、
ここでチームメンバーが行っていた学習Datasetの作成がようやく準備できました。作成した学習Datasetは8000問で、以下のような科学に関する問題だけを含んでいます。
Which of the following statements accurately describes the function of a pH meter in chemistry?
A) A pH meter is an electronic device used to measure the acidity or alkalinity of a solution.
B) A pH meter is a device used to measure the color of a solution.
C) A pH meter is a device used to measure the temperature of a solution.
D) A pH meter is a device used to measure the volume of a solution.
E) A pH meter is a device used to measure the viscosity of a solution.
以下のtrain.csvの例と比べると、似たような形式の問題が作れたのではないでしょうか。
What is the gravitomagnetic interaction?
A)The gravitomagnetic interaction is a force that is produced by the rotation of atoms in materials with linear properties that enhance time-varying gravitational fields.
B) The gravitomagnetic interaction is a force that acts against gravity, produced by materials that have nonlinear properties that enhance time-varying gravitational fields.
C) The gravitomagnetic interaction is a new force of nature generated by rotating matter, whose intensity is proportional to the rate of spin, according to the general theory of relativity.
D) The gravitomagnetic interaction is a force that occurs in neutron stars, producing a gravitational analogue of the Meissner effect.
E) The gravitomagnetic interaction is a force that is produced by the rotation of atoms in materials of different gravitational permeability.
DatasetをDeBERTaに学習させ、提出を行います!しかし結果は、、

DeBERTa単体モデルでのスコアが0.880だったので、それよりも下がってしまいました、、
この学習は絶対にスコアが上がると思っていたのでショックが大きかったです、、
アンサンブルの方もエラー続き、自作Datasetは使い物にならないということで何もうまくいかず、その間にも銅メダルボーダーは上がり続けており、いつメダル圏内から落とされるか分からない、かなりきつい時期でした、、
datasetはうまくいかなかったと諦め、公開Notebookの60k datasetを使用することにしました。ここからアンサンブルに集中して取り組みます。いろいろと試行錯誤していき、エラーの原因がOOMだということにようやく気付きます。contextを削減することで、ついに3modelが回り、スコアは0.898と、2modelの0.895を更新することができました!contextを削減するとOOMエラーを回避できるがスコアが少し落ちてしまうため、OOMエラーが起こらないギリギリのcontextを探しつつ、modelをさらに増やせないか検討しました。context調整で0.899,0.901と上げていき、最後に4modelアンサンブルで0.905と大きくスコアを上げました!

これにより、Public LB0.905,Private LB0.901で念願の銅メダルを獲得することができました!!

最終的な解法
以下の4modelのaveragingで提出しました。
| model | dataset for training | context | RAG | dataset for RAG |
|---|---|---|---|---|
| DeBERTa-v3 | 60k dataset | - | all-MiniLM-L6-v2 | Wikipedia |
| DeBERTa-v3 | 60k dataset | - | tf-idf | 270K Wiki STEM articles |
| DeBERTa-v3 | zero shot | 2200 | tf-idf | 270K Wiki STEM articles |
| LongFormer | zero shot | - | tf-idf | 270K Wiki STEM articles |
振り返り
限られた時間の中で、自分たちのできる範囲で、正しく仮説検証を行うことができたことは良かったと思います。今回のコンペではRAG(Retrieval Augmented Generation:外部知識から検索した情報を生成AIのプロンプトに追加する方法)の多様性が重要でしたが、自分たちは終盤にRAGの重要性に気づいたものの、コーディング力不足で実装することができませんでした。銀メダルのsolutionをいくつか読むと、自分たちと似たアプローチの解法がいくつかあり、そのすべてでlongformerの重みを下げる(0.1くらい)、もしくは使わないようにしていました。longformerよりDeBERTaの方が精度が高いことには気づき、重みづけの調整も行ったのにも関わらず、longformerの重みをそこまで小さくできなかったことはとても悔しかったです。
おわりに
データサイエンスの世界にまだ足を踏み入れたばかりですが、日々楽しく取り組むことができています。これからも様々なコンペにチャレンジしていこうと思います。
Discussion