Code Interpreterで植物の国別ヒートマップを作成してみた


はじめに
ChatGPTのCode Interpreterに植物のデータを投げ、国別のヒートマップを作成できるか試してみようと思います。
植物データ
今回使用するデータは地球上のあらゆる種類の生物に関するデータをオープンアクセスで提供しているGBIFから持ってきます。
以下のサイトで植物名を検索します。
今回はアロエベラという植物について調べてみます。

右上の緑色の「OCCURRENCES」のボタンをクリック、csvをダウンロード
Code Interpreter
植物データが用意できたので、
Code Interpreterを使用して国別のヒートマップ作成に取り掛かります。
植物データはダウンロードした生データをそのまま投げてみます。
まずは国別にデータを集計してもらいます。

デリミタを指定しなくても調べてくれるようです。ちゃんと集計できているようなので、集計したデータを元にヒートマップを作成してもらいましょう。

なんと二回のプロンプトでヒートマップが完成してしまいました...!!
Code Interpreterで生成されたコード
Code Interpreterによって生成された、ヒートマップを作成するコードをまとめてみます。
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
# タブ区切りでデータを読み込む
data = pd.read_csv('/mnt/data/0290459-220831081235567.csv', sep='\t')
# 国ごとの観測回数を計算する
country_counts = data['countryCode'].value_counts()
# 世界の地図データを読み込む
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
# iso_a2 (2文字の国コード) と iso_a3 (3文字の国コード) のマッピングを作成
country_code_mapping = {
'MX': 'MEX', 'ES': 'ESP', 'US': 'USA', 'BR': 'BRA', 'IN': 'IND',
'ZA': 'ZAF', 'ID': 'IDN', 'TH': 'THA', 'CL': 'CHL', 'PE': 'PER',
'VE': 'VEN', 'AU': 'AUS', 'MY': 'MYS', 'PH': 'PHL', 'MA': 'MAR',
'AR': 'ARG', 'PK': 'PAK', 'DZ': 'DZA', 'NP': 'NPL', 'TZ': 'TZA',
'KE': 'KEN', 'NG': 'NGA', 'UY': 'URY', 'VN': 'VNM', 'CR': 'CRI',
'CO': 'COL', 'JP': 'JPN', 'EC': 'ECU', 'LK': 'LKA', 'TT': 'TTO',
'UG': 'UGA', 'JM': 'JAM', 'BD': 'BGD', 'GH': 'GHA', 'PR': 'PRI',
'PT': 'PRT', 'KR': 'KOR', 'SA': 'SAU', 'AE': 'ARE', 'TR': 'TUR',
'TW': 'TWN', 'BW': 'BWA', 'ZW': 'ZWE', 'LB': 'LBN', 'ET': 'ETH',
'IQ': 'IRQ', 'OM': 'OMN', 'IL': 'ISR', 'PY': 'PRY', 'SG': 'SGP',
'IR': 'IRN', 'DO': 'DOM', 'BO': 'BOL', 'EG': 'EGY', 'CN': 'CHN',
'AG': 'ATG', 'HN': 'HND', 'MT': 'MLT', 'RU': 'RUS', 'ZM': 'ZMB',
'NI': 'NIC', 'YE': 'YEM', 'GU': 'GUM', 'JO': 'JOR', 'AW': 'ABW',
'KW': 'KWT', 'SY': 'SYR', 'BH': 'BHR', 'QA': 'QAT', 'GD': 'GRD',
'HT': 'HTI', 'CY': 'CYP', 'VI': 'VIR', 'VC': 'VCT', 'GY': 'GUY',
'SV': 'SLV', 'CW': 'CUW', 'BB': 'BRB', 'BM': 'BMU', 'KY': 'CYM',
'BZ': 'BLZ', 'KN': 'KNA', 'LC': 'LCA', 'TT': 'TTO', 'VG': 'VGB'
}
# 2文字の国コードを3文字の国コードに変換
data['iso_a3'] = data['countryCode'].map(country_code_mapping)
# 3文字の国コードを基に地図データと結合
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
world = world.set_index('iso_a3').join(data['iso_a3'].value_counts())
# ヒートマップを表示
fig, ax = plt.subplots(1, 1, figsize=(15, 10))
world.boundary.plot(ax=ax, linewidth=1)
world.plot(column='iso_a3', ax=ax, legend=True,
legend_kwds={'label': "Number of Observations"},
cmap='OrRd', missing_kwds={'color': 'lightgrey'})
plt.title('Number of Aloe Vera Observations by Country')
plt.show()
「GeoPandas」というライブラリを使用して世界地図を描いているようです。
今回使用した植物データは 'iso_a2' という2文字の国コードを使用していますが、「GeoPandas」によって国別のヒートマップを作成するには、'iso_a3' という3文字の国コードが必要なので、無理やり国コードを変換していますね。
しかも、それは指示したものではなく、Code Interpreterが自分で試行錯誤して解決策にたどり着いています。
まとめと感想
ChatGPTのCode Interpreterに植物のデータを投げ、国別のヒートマップを作成することが出来ました。
実はCode Interpreterが登場する前に、今回作成したヒートマップを自分で作ったことがあったのですが、その時は何時間もかけてようやく作ることができたものでした。
それがCode Interpreterを使えば、まったくコーディングせず、ものの数分で簡単に作成することができました。恐ろしいです、、、
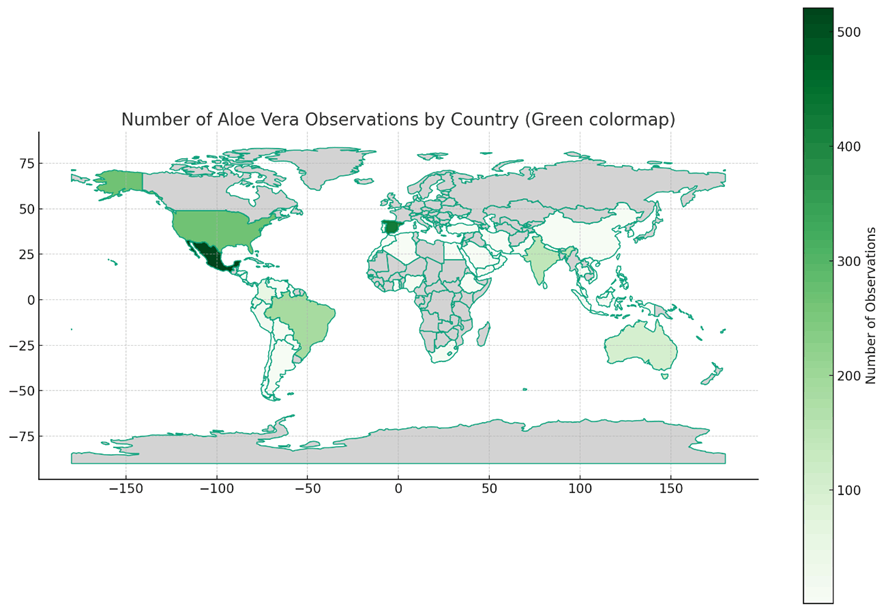
植物のマップなので緑色の方がいいですね
Discussion