負荷試験準備に役立つダミーデータ積み込みCLIの紹介
負荷試験の前準備としてTBLに大量のダミーデータを積み込むことはありませんでしょうか?
大抵は適当なSELECT INSERT文やその場専用のスクリプトを組むと思うのですが、より汎用的に使えるCLIを作成しました
使い方
以下のコマンドで簡単に大量のダミーデータを積み込めます
dummy_data_generator gen -c config.yaml
-cで指定しているyamlファイルでどのTBLのどのカラムにどんな値を積み込むかを設定しています
例えば以下のDDLで作成されるTBLに1,000,000行積み込む場合の設定ファイルを書いてみます
CREATE TABLE sample_tbl (
id VARCHAR(26) NOT NULL,
sex VARCHAR(6) NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id)
);
この場合、以下のような設定が可能です
tablename: sample_tbl
recordcount: 1000000
buffer: 1000
columns:
# idカラムはULID形式の文字列ですべてユニークになるように入れる
- name: id
type: varchar
rule:
type: unique
format: ULID
# sexカラムは"male", "female", "NA"という文字列を3:2:1の割合で入れる
- name: sex
type: varchar
rule:
type: pattern
patterns:
- value: male
times: 3
- value: female
times: 2
- value: NA
times: 1
# created_atカラムは"2024-01-01 00:00:00"という固定値を入れる
- name: created_at
type: timestamp
rule:
type: const
value: '2024-01-01 00:00:00'
特徴
複数のデータ生成パターン
各カラムで指定するcolumns[].rule.typeでpatternやuniqueを指定することで特定の値を繰り返したり、UUIDやULIDを生成することができます
これにより負荷試験の際に重要なデータのカーディナリティを考慮した積み込みを行うことができます
例えば上記例でのsexカラムでは["male", "male", "male", "female", "female", "NA"]が繰り返される形で挿入されます
またtype: numberのカラムに対してはcolumns[].rule.min, columns[].rule.maxを設定してその間を繰り返すような設定も可能です
bufferされたBulk Insert
bufferされたBulk Insertに対応していてbufferで指定されたレコード数のBulk Insertを繰り返す形になっています対象のデータベースのスペックや設定に応じてbufferを変えることで高速にデータを積み込むことができます
その他
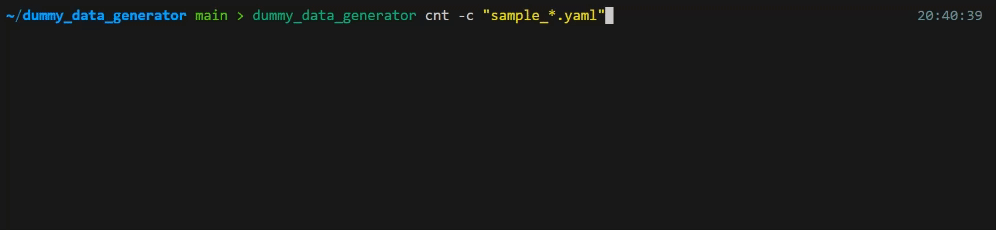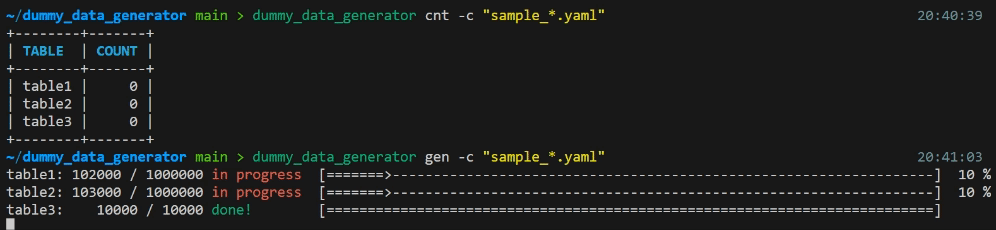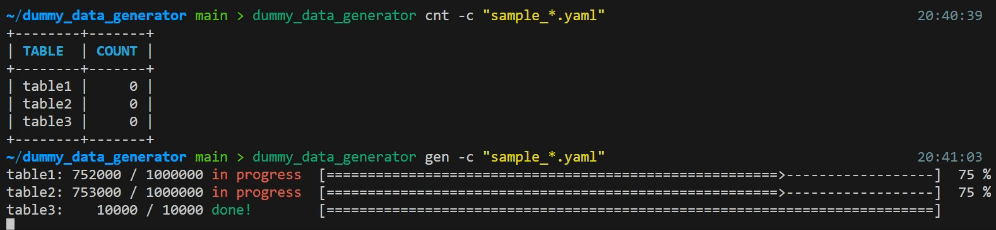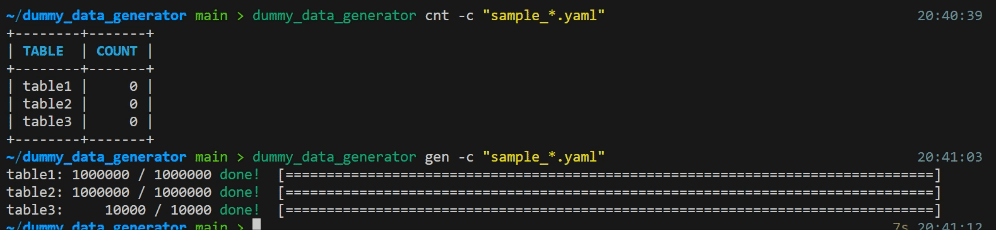
- 積み込み対象テーブルの現在の件数を確認できる
cntサブコマンドがあります - データ積み込み処理中はプログレスバーで進行状況を確認できます
- DBエンジンはPostgreSQLとMySQLに対応しています
- 複数のTBLに対する積み込みを行う場合はTBLごとに設定ファイルを分け、
-c "config_*.yaml"のようにして一気に読み込むことができます
インストール
$ go install github.com/ponyo877/dummy_data_generator
インストールが完了するとdummy_data_generator genのようにして使えるようになります
$ dummy_data_generator --help
Usage:
[command]
Available Commands:
cnt count target table data
completion Generate the autocompletion script for the specified shell
gen generate dummy data
help Help about any command
version show command version
Flags:
-c, --config strings dummy data config file, multi case: -c "cfg_*.yaml" or -c cfg_1.yaml,cfg_2.yaml (default [config.yaml])
-d, --database string the database to use (default "mydb")
-u, --dbuser string database user name (default "root")
-e, --engine string database engine, support postgres and mysql (default "postgres")
--help help for this command
-h, --host string database server host or socket directory (default "127.0.0.1")
-p, --password string database password to use when connecting to serve (default "password")
-P, --port string database server port (default "5432")
開発
Go言語のcobraというCLI作成用packageを使って比較的簡単につくることができました
その他便利だったpackageです
- viper: CLIオプション/設定ファイル管理
- gorm: ORM
- tablewriter: 表形式出力
- mpb: プログレスバー
まとめ
負荷試験準備で役立つダミーデータ積み込みツールをGo言語で作りました
バグが沢山あると思うので利用の際はローカルで試した上で自己責任でお願いします
(バグ修正、機能拡張のPR大歓迎です!)
Discussion