Teach Llamas to Talk: Recent Progress in Instruction Tuningメモ
以下の記事に関して要点や気になった点をメモ
著者はSimCSE提案者のGaoさん
前置き
主にLLMのチューニング方法は主に以下の2段階
- Supervised fine-tuning (SFT) : 対話正解データによるfine-tuning(Causal LM)
- Aligning: 人間の嗜好にモデルをアラインする。主な手法はRLHF。通常は応答ペアに対してどちらが良いかのラベルがついたpreference dataが必要。
この記事は4部構成(SFT data、preference data、algorithms、evaluation)
Supervised fine-tuning (SFT) data
supervised fine-tuningするためのデータは以下の二種類
- 一般的な言語理解能力を獲得するためのデータ。従来のNLPタスク。
- 会話能力を獲得するためのデータ(instruction-tuning data)
ただし、1の形式は短くシンプルなため近年のいわゆるinstruction tuningではあまり一般的に利用されない。(2と組み合わせて利用されることはある。)
以降では 2 をSFT dataと呼ぶ。
SFT dataはLLMsの知識(従来のNLPタスクで点を出せるか)を改善するのではなく、単に会話形式や人を惹きつける言い方、礼儀正しい言い方に補正するだけというのが一般的な考え方:
SFT dataの収集法
- 指示を収集し人手で応答を作成
- ChatGPTなどの公開されたLLMsから応答を生成(蒸留)
- self-instruct: text-davinci-003で生成。Alpacaの学習につ
応答形式を模倣するだけで、実質的な問題解決力能力が向上しているわけではないという話も・・・
- 指示・応答共にアノテーション、クラウドソーシング等を活用
- Dolly: Wikipediaベースのfactoid QA形式
- LIMA: Q&Aサイト(Stack ExchangeとwikiHow)からqaペアを選別
Preference data
SFT dataだけだと例えばLLMsに「わかりません」と正直に振る舞うように学習するのは難しい
-> preference dataによるAligningが必要
しかし、多くのOSSモデルは下記理由でAligningを実施していない
- RL実施のコストの重さ
- PPOのハイパラ調整の難しさ
- 高品質preference dataが少ない ため
よく使われてきたのはOpenAIのTL;DR preference data、HH-RLHF dataset
2023以降新しいpreference dataも続々と登場
- SHP: Redditでupvote数を利用してヒューリスティックに作成
- AlpacaFarm、UltraFeedback: GPT-4をアノテータとして作成
- 人の関与なしにLLMsによるフィードバックを使用
- constitutional AI
- reinforcement learning from AI feedback (RLAIF): LLMsが応答ペアに対する好みラベルをつける
preference dataの質が十分か、平等な比較を実施するとどうなるか等は明らかになっていない
Algorithms
RLHFではPPOを利用するのが主流に。
基本的にはアイデアは(1) preference dataで報酬モデルを学習、(2)報酬モデルからの報酬を利用した強化学習でLLMをチューニング。詳細はhuggingfaceの資料を一読するのが良い
RLHFは効果的だが、実装が複雑・最適化が不安定・ハイパラに敏感。
Preference dataで学習する方法は他にも登場しており、RLHFより性能が出ているものもあり:
- Best-of-n: SFT後のモデルに対して報酬モデルを利用して良い応答をサンプリング
- Expert iteration: Best-of-nでサンプリングした応答を利用してSFTモデルを再学習を繰り返す
- Conditional tokens: 良い例には"good"、悪い例には"bad"をそれぞれプロンプトに連結しておく。推論時は"good"をプロンプトにつけ、良い応答が生成されることを期待する。
- Contrastive-based methods: preference dataを用いて良い例を出し悪い例を抑制するように対照学習。
- SLiC、RRHF
-
DPO: RLHFの目的関数を以下のように変形することで報酬モデルを解さず直接最適化できるように
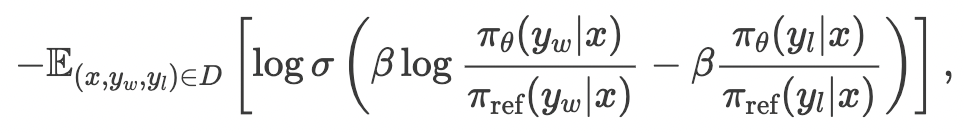
- RSO: 既存のpreference dataは学習対象のSFTモデルとは異なるモデルからの応答データなので分布の不一致が起こる。RSOでは報酬モデルでサンプリングを選別する手法でこれを解消しSLiCやDPOの性能改善。
Alignmentアルゴリズムが本当に役立つのかやその性質は完全には明らかにはなってない。
例えば報酬モデルの好みはテキスト長と相関があるという研究あり。
Evaluation
人手による評価はあまり信頼できない、コストがかかる、平等な比較でができないなどいくつか課題あり。
-> 強力なLLMsで弱いLLMsの評価が盛んに。LLM evaluatorsと呼ばれている。
人間の評価と相関があり良さそうという研究報告がいくつかあり。
一方でLLM evaluatorsは以下のようなバイアス問題あり
- 二つの応答が入れ替わると好みの傾向が変わる
- 長めの応答を好む
- evaluator自身と似たモデルの応答を好む
上記をバイアス問題を解決するため、LLM evaluators自体を評価する“meta-evaluation”ベンチマーク登場(FairEval, MT-Bench、LLMEval)
とはいってもベンチマーク自体も主観的だしノイズあり。人間のagreement rateも低い。
-> “meta-evaluation”ベンチマークやLLM evaluatorsを信頼できるかは明らかではない。
著者らの研究(LLMBar)については割愛