Raspberry PiとChatGPTでつくるボイス・アシスタント・ロボット #3

ChatGPT実験ロボット "Voice Assistant Robot_GPT" ウェイクワードを認識した瞬間
音声認識
実験ロボットのサンプルプログラム bot_listener.py ファイルで実行します。内容の説明にあたり、モーターやLED操作の部分を省略したもので解説します。
音声認識ツールキット Vosk
Voskはオープンソースのオフライン音声認識ツールキットであり、日本語モデルにも対応しています。小規模なモデル(50Mb)も用意されており、Raspberry Piでの使用に適しています。
仕組み
ユーザーの音声発話を、PythonのオーディオライブラリPyAudioを使ってストリーミングし、Voskを使用しテキストに変換します。不要な音声に対して返信しないように、「ウェイクワード」を聞くまでは待機状態にします。また、ロボットの対話を終了する際は「終了ワード」を話すことで待機状態に戻ります。チャート図で表すと以下のようになります。
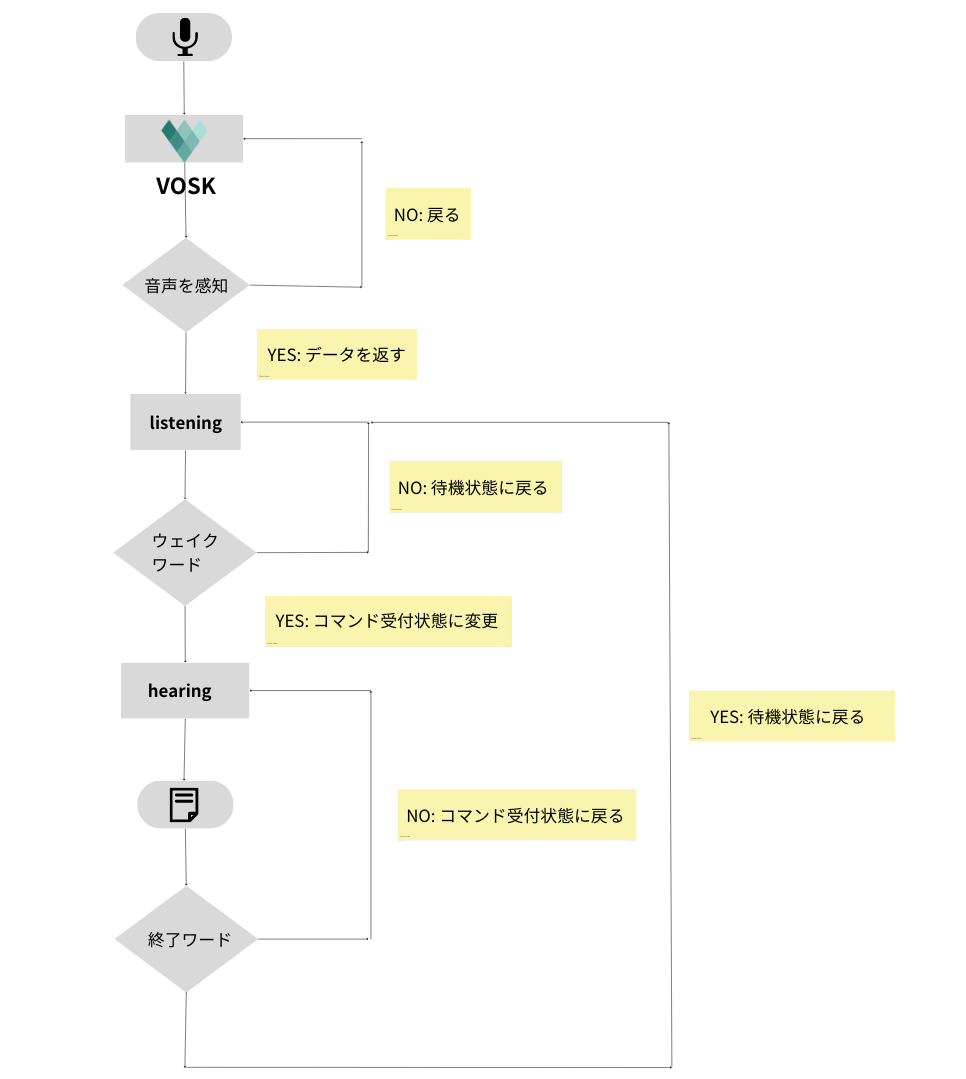
ウェイクワードによる待機状態、コマンド受付状態の切り替え実装は、Brandon JacobsonさんのYouTubeチャンネル[1]を参考にしました。
サンプルプログラム
各ファイルのディレクトリは以下のようになります。Voskモデルは実行ファイルと同じディレクトリに配置してください。
.
├── data
│ └── command_data.json
├── ex_bot_listener.py
└── vosk-model-small-ja-0.22
また、音声コマンドを設定するJSONファイルcommand_dada_jsonはdataフォルダに格納してください。
{
"wake": ["テスト", "始めてください"],
"exit": ["終わり", "終わりにしてください"]
}
import json
from pathlib import Path
from vosk import Model, KaldiRecognizer # ---(※1)
import pyaudio
# Jsonファイルからウェイクワードとコマンドの配列を読み込む ---(※2)
with open(Path("data/command_data.json"), "rb") as f:
data = json.load(f)
WAKE = data["wake"]
EXIT = data["exit"]
# Voskモデルの読み込み ---(※3)
model = Model(str(Path("vosk-model-small-ja-0.22").resolve()))
# マイクの初期化
recognizer = KaldiRecognizer(model, 16000)
mic = pyaudio.PyAudio()
# voskの設定 ---(※4)
def engine():
stream = mic.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=8192)
# ストリーミングデータを読み取り続けるループ---(※5)
while True:
stream.start_stream()
try:
data = stream.read(4096)
if recognizer.AcceptWaveform(data):
result = recognizer.Result()
# jsonに変換---(※6)
response_json = json.loads(result)
print("🖥️ SYSTEM: ", response_json)
response = response_json["text"].replace(" ","")
return response
else:
pass
except OSError:
pass
# ウェイクワード待機をlistening コマンド待機をhearingと設定 ---(※7)
listening = True
hearing = False
# listeningをループして音声認識 ウェイクワード認識でhearingループする
def bot_listen_hear():
# グローバル変数 ---(※8)
global listening, hearing
if hearing == True: print("🖥️ SYSTEM: ","-"*22, "GPTに話しかけてください","-"*22)
else: print("🖥️ SYSTEM: ","-"*22, "ウェイクワード待機中","-"*22)
# listeningループ ---(※9)
while listening:
response = engine()
if response in WAKE:
listening = False
hearing = True
print("🖥️ SYSTEM: ","-"*22, "GPTに話しかけてください","-"*22)
# 空白の場合はループを途中で抜ける ---(※10)
elif response.strip() == "":
continue
else:
pass
# hearingループ ---(※11)
while hearing:
response = engine()
if response in EXIT:
listening = True
hearing = False
# 空白の場合はループを途中で抜ける ---(※12)
elif response.strip() == "":
continue
else:
pass
return response
if __name__ == "__main__":
try:
while True:
# bot_listen_hear関数を実施してレスポンスを得る ---(※13)
user_input = bot_listen_hear()
print("😀 USER: ",user_input)
# ロボットの返信を設定 ---(※14)
robot_reply = "回答テストです"
print("🤖 GPT: ", robot_reply)
except KeyboardInterrupt:
# ctrl+c でループ終了 ---(※15)
print("🖥️ SYSTEM: プログラムを終了します")
(※1)でVoskモジュールをインポートします。
(※2)でJSONファイルを読み込みます。キー"wake"の値が「ウェイクワード」に、キー"exit"の値が「終了ワード」になります。
(※3)でVoskモデルを読み込み、(※4)でマイクから入力された音声ストリームを使用してテキストに変換します。ストリーミングデータを継続的に返すため、(※5)でループを設定をします。
注意すべき点として、変換されたテキストはJSON形式で出力され、語彙ごとにスペースで区切られています。(※6)のように、一度json.loads()で変換した後、"text"要素を取り出し、replace()を使って空白を削除します。
空白を削除したテキストをもとに、待機状態もしくはコマンド受付状態のループ処理を行います。待機状態の変数をlistening、コマンド受付状態の変数をhearingと設定します(※7)(※8)。そしてlisteningがTrueならlisteningループ(※9)hearingがTrueならhearingループ(※11)を実行します。テキストが「ウェイクワード」もしくは「終了ワード」であるかどうかは、JSONデータを元に判別します。
なお、ロボットは音声を受け付けるとサウンドを鳴らし、LEDを点灯させます。音声認識で無音が続くと誤って反応してしまう可能性があるため、無音の場合はループを途中で抜ける処理を(※10)と(※12)に記述します。
最終的には、(※13)で示されるように、メインループを通じて音声入力を取得し、(※14)で応答をを返信します。プログラムを終了するにはctrl+cを使用します(※15)。
ファイルを実行し、マイクで「テスト」「右を向いてください」「終わり」と音声入力しました。結果をターミナルで確認すると、以下のようになります。
🖥️ SYSTEM: ------------------- ウェイクワード待機中 -------------------
🖥️ SYSTEM: {'text': 'テスト'}
🖥️ SYSTEM: ------------------- GPTに話しかけてください -------------------
🖥️ SYSTEM: {'text': '右 を 向い て ください'}
😀 USER: 右を向いてください
🤖 GPT: 回答テストです
🖥️ SYSTEM: ------------------- GPTに話しかけてください -------------------
🖥️ SYSTEM: {'text': '終わり'}
😀 USER: 終わり
🤖 GPT: 回答テストです
🖥️ SYSTEM: ------------------- ウェイクワード待機中 -------------------
^C🖥️ SYSTEM: プログラムを終了します
「ウェイクワード」の音声入力によりコマンド受付状態になり、「終了ワード」の音声入力で待機状態に戻っているのが確認できます。
ターミナルで出力を確認する際、絵文字を使用するとより分かりやすくなります。 alhafoudhさんのインストールスクリプト[2]を参考にして絵文字フォントをインストールすることをおすすめします。
合成音声発話
音声合成モジュール AquesTalk Pi
AquesTalk Piは、Raspberry Pi上で簡単に音声合成ができる実行モジュールで、少ない処理量で高速に音声を合成することが出来ます。f1(ゆっくり霊夢)とf2(ゆっくり魔理沙)という2つの人気の声種が使えます。2022年2月のバージョンアップでRaspberry Pi OS 64bit用バイナリを追加しています。
仕組み
noraworld/aquestalk-installer には、64Bit用バイナリのインストールスクリプトと使用方法が記載されています。テキストをAquesTalk Piモジュールで実行し、Linuxコマンドaplayで再生します。
$ echo ゆっくりしていってね? | aquestalkpi/AquesTalkPi -b -f - | aplay
AquesTalk Piは組み込みされており、非常に高速に処理されます。Pythonで使用する場合はsubprocessモジュールを使用してlinuxコマンドを実行します。
サンプルプログラム
実験用ロボットの実行ファイルbot_voice_synthesizer.py からLED制御を除いたもので解説します。まずは各ファイルのディレクトリを確認します。
.
├── aquestalkpi
│ ├── AquesTalkPi
│ ├── aq_dic
│ ├── aq_user.dic
│ ├── aqdic.bin
│ └── credits
├── data
│ └── notificationx4.wav
└── ex_bot_voice_synthesizer.py
ファイルの配置はこのようになります。ダウンロードしたaquestalkpiフォルダに実行ファイルと辞書が格納されていることを確認してください。音声入力時の通知サウンドはdataフォルダに格納します。
import subprocess # ---(※1)
from pathlib import Path
# 音声合成して再生(再生が完了するまで待機)---(※2)
def speak(text, num):
AquesTalkPi = str(Path("aquestalkpi/AquesTalkPi").resolve())
speak_cmd = "echo " + text + " | " + AquesTalkPi + " -b -v f" + str(num) + " -f - | aplay"
subprocess.run(speak_cmd,shell=True)
# 音声合成して再生(非同期再生)---(※3)
def speak_popen(text, num):
AquesTalkPi = str(Path("aquestalkpi/AquesTalkPi").resolve())
speak_p_cmd = "echo " + text + " | " + AquesTalkPi + " -b -v f" + str(num) + " -f - | aplay"
subprocess.Popen(speak_p_cmd,shell=True)
# 通知音を再生 ---(※4)
def notification():
notification_wav = str(Path("data/notificationx4.wav").resolve())
print(notification_wav)
aplay_cmd = "aplay " + notification_wav
subprocess.run(aplay_cmd,shell=True)
if __name__ == "__main__":
notification()
speak("テストです", 1)
speak("テストです", 2)
speak_popen("テストです", 1)
speak("テストです", 2)
プログラムはシンプルです。まず、(※1)でsubprocessモジュールを読み込み、AquesTalkPiの実行モジュールの絶対パス、テキストおよびボイス番号を用意し、subprocess.run()を使用して実行します。(※2)
ちょっとお遊びで、f1(ゆっくり霊夢)とf2(ゆっくり魔理沙)の挨拶を同時にできるように非同期再生の関数も作成しました。非同期再生はsubprocess.popen()を使用して行います(※3)。同期処理のf1ボイスと、非同期処理のf2ボイスを連続して発話させることで、おなじみの挨拶を再現できます。
さらに、音声入力時の通知サウンドもこのファイルで関数を作成しました(※4)。Linixコマンドaplay wavをsubprocessモジュールを用いて実行します。通知サウンドは、音源サイトmobcup.net[3]からダウンロードしました。
実行すると着信音、f1、f2の発話を確認出来ます。録音したものをサウンド共有サイトにアップロードしておきましたのでご参照ください。
-
Make Your Own Digital Assistant like Alexa or Siri with Python | #113 (Intermediate Python #1) / Brandon Jacobson ジェイコブス氏のプロフィールには「私は独学のコンピューター・プログラマーで、Pythonを使用してJarvisのようなデジタル・アシスタントを構築する予定です。」と書かれています。非常に親近感を覚えました。 ↩︎
Discussion