2023年AIの進歩を振り返ろう!



はじめに
State of AI は、AI の現状に関するレポートです。英国の AI に特化したベンチャーキャピタル「Air Street Capital」が 2018 年から毎年発行しており、AI の方向性や最新動向を探るのに役立ちます。
今回は 2023 年版のうち、面白かった部分だけ取り出して読んでいきます。
概要
研究
-
GPT-4が登場し、プロプライエタリなモデルとオープンソースとの間に能力の大きな隔たりを示す一方で、人間のフィードバックからの強化学習の効果を確認。
-
LLaMa-1, 2を用いて、より小さなモデル、より良いデータセット、より長いコンテキストで既存モデルのパフォーマンスを超える試みが増加。
-
人間が生成するデータがAIモデルの拡大傾向をどれだけ持続できるか(2025年にはデータが枯渇するかも)や、生成データを学習に追加する効果は不明。次に来るのは動画や企業内に保管されているデータである可能性が高い。
-
LLMsと拡散モデルは、分子生物学や薬物発見に新たな突破口を提供し続け、ライフサイエンスコミュニティに恩恵をもたらす。
産業
-
NVIDIAは、国家、スタートアップ、大手テクノロジー企業、研究者などからのGPUへの旺盛な需要により、時価総額1兆ドルに突入。
-
輸出規制により中国への先進的なチップの販売は制限されているが、主要チップベンダーは輸出規制を免れる代替品を開発。
-
ChatGPTを先頭に、GenAIアプリは画像、ビデオ、コーディング、音声、またはCoPilotsなどで飛躍的な成長を遂げ、VCと企業の投資を180億ドルまで押し上げた。
政治
-
世界は明確な規制陣営に分かれているが、グローバルガバナンスの進展は遅い。最大手のAI研究所は、その空白を埋めるために参入している。
-
チップ戦争は続いており、米国は同盟国を動員しているが、中国の対応はまだ不十分。
-
AIは選挙や雇用などの敏感な領域に影響を及ぼすと予想されているが、まだ大きな影響は見られない。
安全性
-
実存性リスクについての議論が初めて一般に広まり、大幅に激化。
-
多くの高性能モデルは「脱獄」しやすい。RLHFの課題を解決するために、研究者は自己整合性や人間の嗜好による事前学習などの代替策を探求。
-
能力が進化するにつれて、SOTAモデルを一貫して評価することがますます難しくなっている。Vibesだけでは十分ではない。
LLM 界隈の動き
GPT-4すごいよね
-
GPT-4は、テキストだけでなく画像も学習したマルチモーダルモデルで、画像に基づいてテキストを生成するなどの機能を持つ。
-
GPT-4の評価を従来のNLPベンチマークだけでなく、人間を評価するために設計された試験でも行った結果、GPT-4は全てのモデル中で最も優れており、GPT-3.5が解決できなかった一部のタスクを解決している。
-
GPT-4はまだ幻覚(hallucinations)の問題があるが、以前の最高モデルであるChatGPTよりも40%高い事実正確性を示している。
-
リーク情報によるとGPT-4は220Bのパラメータを持ち、8つの重みセットを持つ16-wayの混合モデルである。モデルの全体的なサイズやMixture of Expertsモデルの使用は新たなものではない。
LLM の可能性
- コーディング
Unnatural CodeLLaMa, WizardCoder, replit-code-v1-3b, StarCoder 3B, AlphaDevなど
コーディング能力のトップはやっぱりGPT-4
- 生涯学習エージェント
Minecraftでの推論、探索、スキル習得が可能なGPT-4ベースのエージェントVoyagerは、GPT-4に反復的にプロンプトを与えることで、タスクを完了するための実行可能なコードを生成する。自身の状態に基づいてタスクのカリキュラムを生成し、徐々に難易度の高いタスクを解決するよう促す。
GPT-4をベースにしたテキストのみのエージェントであるSPRINGはゲームのオリジナルの学術論文を読み、論文のlatexソースを処理し、QAフレームワークを通じて推論し、環境アクションを取ることができる。
- 視覚言語モデル
視覚指示ベンチマーク(VisIT-Bench)において、LLM を用いたモデルが多くの視覚言語モデルの性能を上回った。
- 自動運転
ビジョン-言語-アクションモデルであるLINGO-1は、運転行動や運転シーンに関する情報などの運転解説を提供し、会話形式で質問に答えることができる。
- ロボティクス
PaLM-Eは、視覚、言語、ロボットデータを学習した5620億パラメータの汎用的な一般モデルで、リアルタイムでマニピュレータを制御できる。PaLM-Eはテキストのみの言語モデルよりも純粋な言語タスク(特に地理空間推論を伴うもの)に優れています。
RT-2は、アクションをトークンとして表現し、ビジョン-言語-アクションモデルを訓練する。ロボットデータのみに対する単純な微調整ではなく、ロボットアクション(6-DoF位置および回転変位)に対してPaLI-XとPaLM-Eを共同微調整する。
科学分野への応用
-
AIは物理学、社会科学、生命科学、健康科学などのトップ20の科学分野で進歩を加速させるために応用されている。
-
公開論文数の最も大きな増加は医学分野で見られる。
Skilful Precipitation Nowcasting Using NowcastNet
Ajitabh Kumar, NeurIPS 2023
降水の正確な短期予報システムのため、物理条件付き深層生成ネットワークであるNowcastNetを開発した。
NowcastNetは、低解像度の衛星画像を使用して高解像度の降水量を予測する深層学習の主要なタスクであり、進化ネットワークと生成ネットワークの2つの主要なモジュールがある。進化ネットワークはニューラルオペレータを使用して物理学を学び、生成ネットワークは進化ネットワークからのコンテキストを使用して最終的な予測を行う。
De novo design of protein structure and function with RFdiffusion
Joseph L. Watson et al., Nature Vol.620 2023
de novoバインダー設計や高次対称構造の設計など、幅広い問題で使えるタンパク質設計のための一般的な深層学習フレームワーク。高精度なタンパク質構造予測能力を持つバックボーンの生成モデル(RFdiffusion)が得られた。
RFdiffusionで望ましい特性を持つタンパク質のバックボーンを生成し、その後ProteinMPNNを用いてこれらの生成構造をエンコードする配列を設計することができる。このモデルは、タンパク質モノマー、タンパク質結合体、対称オリゴマー、酵素活性部位の足場などのバックボーン設計を生成することが可能である。
RFdiffusionは、現在のタンパク質設計方法を大幅に改善し、600残基までの多様な設計を正確に生成することが可能で、これまでの方法よりも複雑さと精度を大幅に上回る。
**[Evolutionary-scale prediction of atomic level protein structure
with a language model](https://www.science.org/doi/10.1126/science.ade2574)**
ZEMING LIN et al., SCIENCE 379 2023
LLMを用いて、一次配列から完全な原子レベルのタンパク質構造を直接推論する。AlphaFold-2(AF2)と比較して高分解能構造予測が桁違いに高速化され、メタゲノムタンパク質の大規模構造解析が可能になった。
AF2 では MSA(Multiple sequence alignment) の作成にコストがかかっている。これに依存せず、アミノ酸配列から直接タンパク質の原子レベルの構造を予測した。生物学的構造がシーケンスパターンにリンクされているため、言語モデルに生物学的構造を具現化させるために、数百万の進化的に多様なタンパク質配列に対してマスクされた言語モデリング目標が使用される。
Predicting the outcome of perturbing multiple genes without a cell-based experiment
Yusuf Roohani et al., Nature Biotechnology 2023
遺伝子の刺激や抑制の組み合わせによる遺伝子発現の変化を理解することは、健康や疾患に関連する生物学的経路を解明するために重要である。しかし、組み合わせ爆発の問題から、これらの実験を実験室の生細胞で行うことはできない。
GEARS(Graph-Enhanced Gene Activation and Repression Simulator)は深層学習と遺伝子間関係の知識グラフを統合したもので、多遺伝子摂動の表現型的に異なる効果を予測することができる。
Accurate proteome-wide missense variant effect prediction with AlphaMissense
Jun Cheng et al., Science 381, 2023
読むのに飽きちゃったので、gigazine の記事から。
鎌状赤血球症のように、DNAの塩基配列が変化あるいは置換することで、アミノ酸配列が変化して異常なタンパク質が作られてしまう突然変異を「ミスセンス変異」と呼びます。人間のゲノムにおいて発生し得るミスセンス変異は約7100万種類に及びます。その大部分は健康に影響を与えませんが、ごく一部は鎌状赤血球症のような遺伝性疾患の要因となります。
Google DeepMindのAlphaMissenseは、ミスセンス変異を分析して病気の原因になる可能性を予測するAIツールです。AlphaMissenseはタンパク質構造計算AIであるAlphaFoldに基づいて設計されており、単語の代わりに何百万ものタンパク質配列でトレーニングされた「タンパク質言語モデル」と呼ばれるニューラルネットワークが組み込まれているそうです。
Towards Expert-Level Medical Question Answering with Large Language Models
Karan Singhal et al.
GoogleのMed-PaLMが、アメリカ医師免許試験で合格点を超えた。Med-PaLM 2は、前モデルから基本的なLLMの改善、医療領域の微調整、プロンプト戦略により、より多くのデータセットで新たなSOTAを達成した。
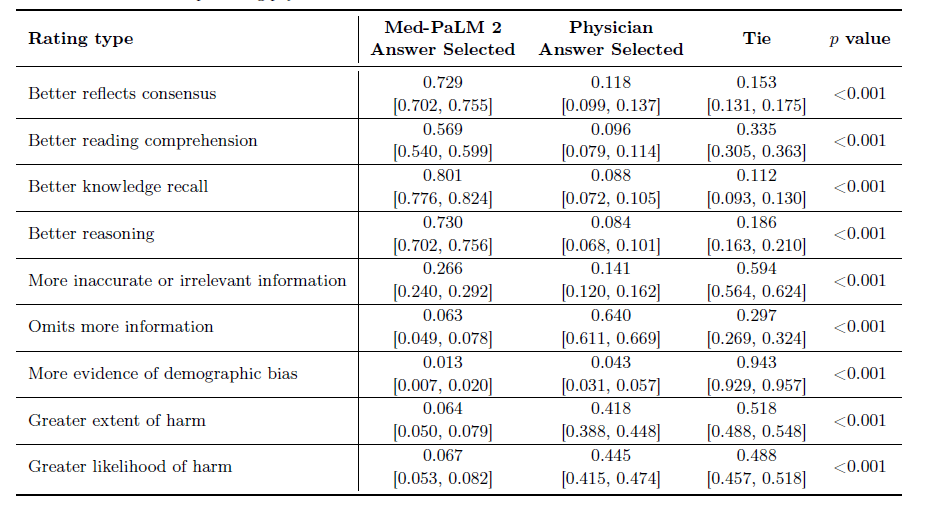
1,066件の一般的な医療に関する長文質問について人間による評価を行ったところ、評価フレームワークの9つの軸のうち8つで医師が作成した回答よりもMed-PaLM 2の回答が好まれた。
Towards Generalist Biomedical AI
Tao Tu et al.
テキスト、画像、ゲノムなどにまたがるマルチモーダルな生物医学ベンチマークであるMultiMedBenchを作成した。MultiMedBenchは、医学的な質問応答、マンモグラフィと皮膚科の画像解釈など、14の多様なタスクを含んでいる。これをもとにした生成モデルMed-PaLM Mは、すべてのMultiMedBenchタスクにおいて十分な性能を発揮した。また、新しい医療概念やタスクに対するゼロショット汎化、タスク間の正の転移学習が観察された。
Shawn Xu et al.
より軽量なアプローチとして、ELIXR(Embeddings for Language/Image-aligned X-Rays)が提案された。ELIXRは、固定LLM(PaLM 2)に、言語整合画像エンコーダを組み合わせたり、接ぎ木したりすることで、幅広い胸部X線タスクを実行する。ELIXRは、ゼロショット胸部X線(CXR)分類、データ効率的なCXR分類、意味検索で効果があった。教師付き学習と比較して、ELIXRは同程度の性能を達成するために必要なデータ量が2桁少なかった。ています。
A visual–language foundation model for pathology image analysis using medical Twitter
Huang, Z. et al., Nat Med 29 2023
医療画像の注釈付きデータが少ない一方、多くの匿名化された画像が医療用 Twitter などで臨床医によって共有されています。このような自然言語の説明と組み合わせた 208,414 枚の病理学画像の大規模なデータセットである OpenPath を作成した。さらに、OpenPath で学習した、画像とテキストのマルチモーダルAIである PLIP (pathology language–image pretraining) を開発した。
Krishnamurthy Dvijotham et al., Nat Med 29 2023
AIシステムは医療画像診断で専門家レベルの疾患同定ができるが誤判定もありうる。CoDoC(Complementarity-Driven Deferral to Clinical Workflow)は、AI予測モデルの出力を信頼するか、代わりに臨床ワークフローに戻るかを学習する。
このシステムで乳がんまたは結核の検診を行ったとき、臨床医のみまたはAIのみの場合と比較して5-15%の擬陽性が減るなど精度が向上した。
Discussion