Zipf則に従う情報論的単語数
Wikipedia によれば、Zipf分布のエントロピーは:
である。総和の部分を:
さらに、調和数を:
ただし、
これらを用いて:
考え方
総単語数Nの言語を使って、M語からなる文章を作ることを考える。文法構造ないし非文かどうかを全く考慮せず、単純な組合せ論的な場合の数は、情報エントロピーを
仮に等確率の場合は、
一般のエントロピーでは、場合の数は
総単語数Nのとき、これらの単語の使用率が厳密にZipf分布に従うとする(Ziphil-Zipfの仮定)と、上記の議論から、情報論的単語数
となる。あるいは、補正付き単語数
としてもよい。
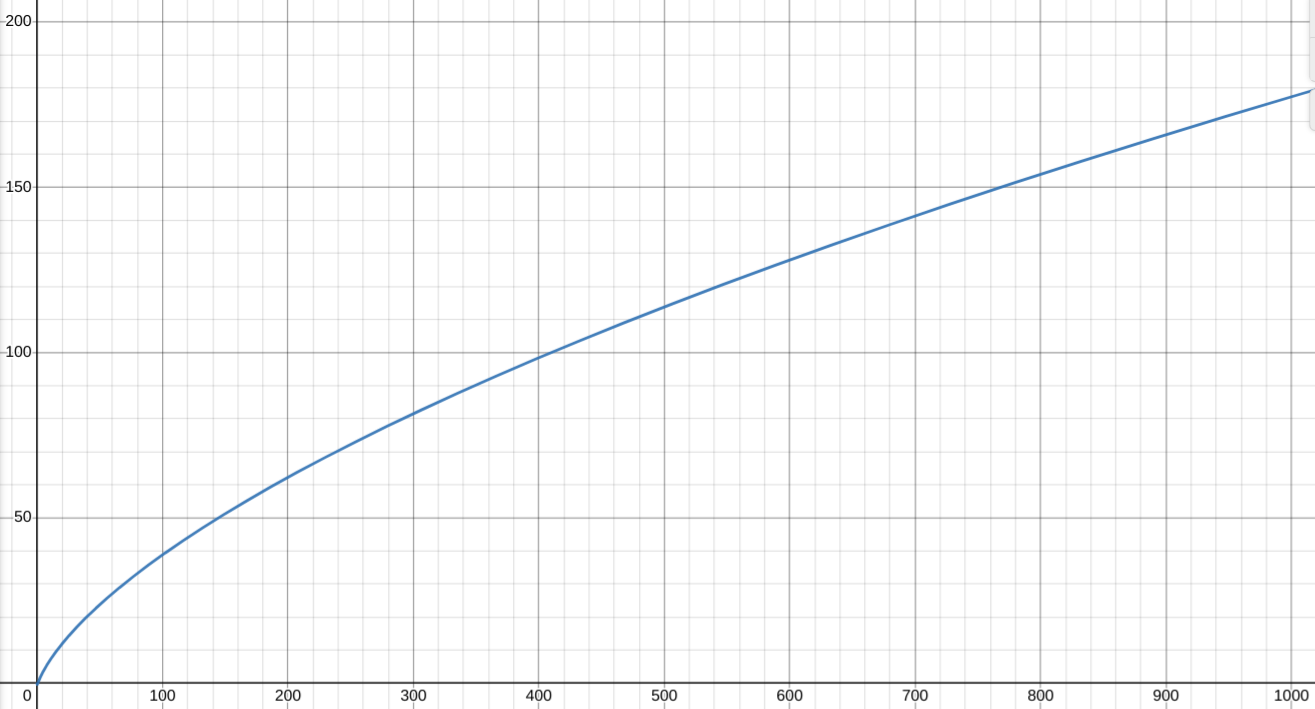
両対数グラフ(常用対数)

Discussion
1TP = 120 words は、
TPごとに情報論的単語数を考えると:

なんらかの単位があるほうが導入しやすいと思うので、Zipfied words point ということで、ZPを提案する。
新しい単語数のLvとして、情報論的単語数レベル LvZを提案する。
これは1TP(120words)での情報論的単語数 44.0 を基準に、その倍数の情報論的単語数を得られるのに必要な単語数の閾値を定める。
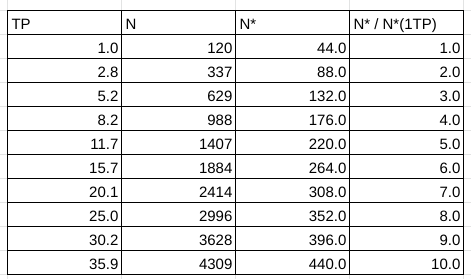

楽観的評価
Zipfの法則がどこまで通用するものなのかはあまり知らないけど、文章作成における諸々の制約(文法、文体、共起表現など)を通じた結果、Zipfの法則が成り立つようになってしまうとしたら、今回求めた情報論的単語数は案外バカにならない指標かもしれない
つまり、たとえば1TP = 120 words = 44ZP の言語では、100単語レベルの文章を書こうとすると、常用対数で
数が膨大でイメージしにくいかもしれないが…、もし素朴に総単語数 120語の無機質な組合せ論を考えると、100語文のレパートリーは
この比を考えると、
もう少し厳密に
上記の議論では、
として、近似精度をあげて計算してみる。結論としては、
となる。
過程を書くと、スターリングの近似のlog項由来で:
少し整理。
数値実験。
大体
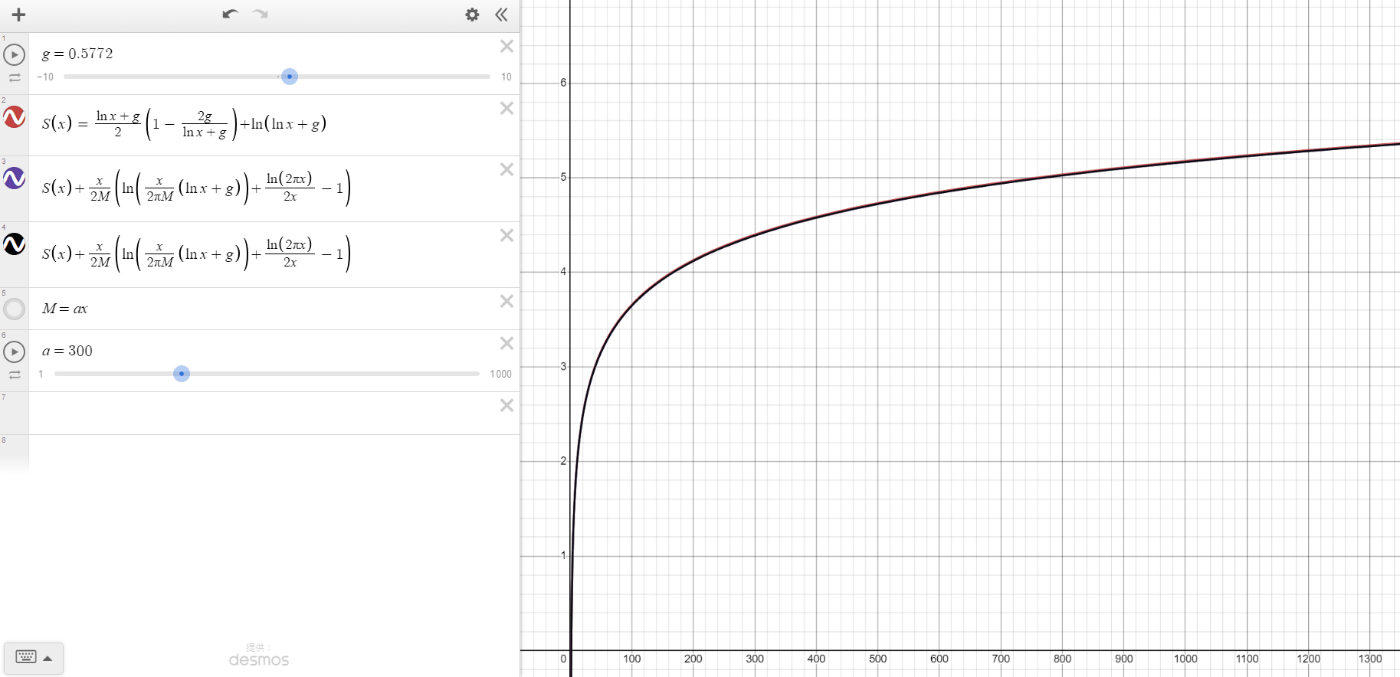
50Nだと結構目立つ

第二項目の近似。実験的に:
ここで、
*条件
-
N \ge 300 a \ge 0.5 -
N \ge 30 a \ge 5
よって、全体として:
よって、