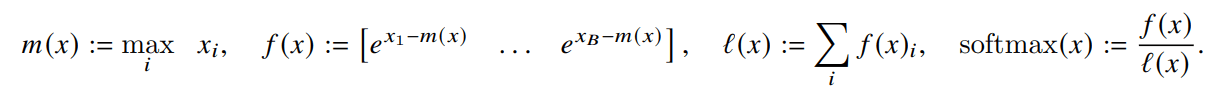FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
HBMからのAttention matrixの読み込みと書き込みを防止することが目的
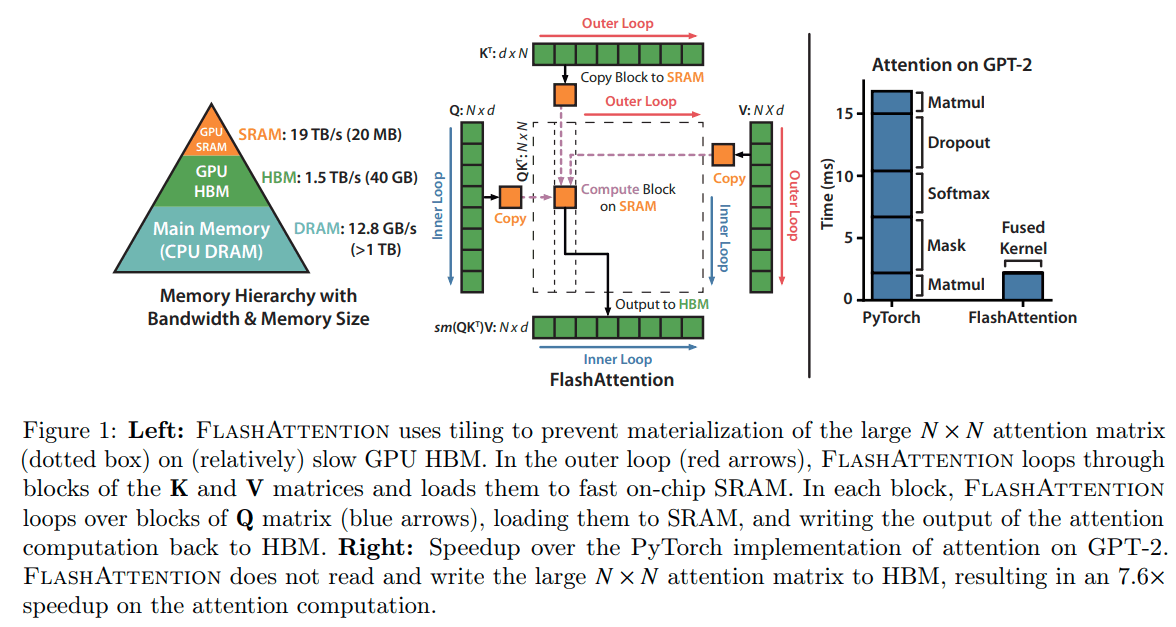
SRAM>HBM>DRAMの順に読み込みや書き込みの速度が速い、ただし、サイズも小さい。
HBMやDRAMにアクセスを少なくして計算することが学習や推論速度向上につながる。
目的の達成には、2つが必要
- HBMにアクセスするためには入力全体にアクセスせずにAttention部分のsoftmaxを計算する
- backward pasの計算のためにattention matrixの巨大な中間出力を保存しないようにする
これらを解決するために、
- 入力をブロックに分割し、そのブロックに対して数回のパスを作ることでAttentionのsoftmaxの計算を段階的に行う。
- backwardでのAttentionを迅速に計算するために、forwardでのsoftmax normalization factorを保存する。
FLASHATTENTIONはHBMへの
一方、standardのAttentionはHBMへ
最大9倍HBMへのアクセスが減る
入力は、
出力は、
Attentionの計算は、
となる。
一般的なAttentionの実装では、

FlashAttentionでは、
計算したAttentionの出力はブロックごとにNormalizationしてから足し合わせる。