MLflowで機械学習パイプラインの管理(1)



はじめに
「AIエンジニアのための機械学習システムデザインパターン」という本読んでいて,パイプライン自体の管理もMLflowでやっていたのがいいなと思ったのでそれについて備忘録という意味でも書いていきます.
MLflow
MLfLowは機械学習用の実験管理ツールで,主に実験のトラッキングやモデルファイルの保存(実際のストレージはS3やGCSなど)に使用することが多いと思います.
MLflowの中には大きく分けて以下の4つの機能があります.
- MLflow Tracking(実験の記録)
- MLflow Project(実験コードのパッケージング)
- MLflow Models(機械学習モデルのデプロイ)
- MLflow Registry(機械学習モデルの管理)
この中だと,やはりMLflow Trackingがメインに使われているのかなと(勝手に)思っています.
というのも,MLflow Trackingは既存の実験コードをほぼ変えることなく(Tracking用のコードを追加するのみ)リッチなUIで実験管理ができるという点が非常に有用です.逆に言うと,それ以外の機能は基本的にプロジェクトの構造を少し変える必要があるので少し手が出しづらい印象があります.
ただ,今回は「AIエンジニアのための機械学習システムデザインパターン」でMLflow Projectをパイプラインの管理のために使っていたので,ちょっと試してみようと思います.
ディレクトリ構成
.
├── dataset
│ ├── MLproject
│ ├── poetry.lock
│ ├── pyproject.toml
│ └── src
│ └── dataset.py
├── preprocess
│ ├── MLproject
│ ├── poetry.lock
│ ├── pyproject.toml
│ └── src
│ └── preprocess.py
├── train
│ ├── MLproject
│ ├── poetry.lock
│ ├── pyproject.toml
│ └── src
│ └── train.py
├── evaluate
│ ├── MLproject
│ ├── poetry.lock
│ ├── pyproject.toml
│ └── src
│ └── evaluate.py
├── main.py
├── poetry.lock
└── pyproject.toml
今の所大本のmain.pyとデータセットダウンロード部分download/*しか作っていませんが,最終的にはこんな感じの実験コードになりそうです.
main.py
main.pyには各パイプラインの設定(エントリーポイントやパラメータなど)を記述する感じになります.実際の処理の中身はそれぞれのパイプライン用ディレクトリの中に定義します.
import mlflow
import typer
app = typer.Typer()
@app.command()
def main():
# データセットダウンロードのパイプライン(パイプラインの単位がRunになっている)
dataset_run = mlflow.run(
uri="./dataset",
entry_point="dataset",
backend="local",
env_manager="local",
)
dataset_run = (
mlflow
.tracking
.MlflowClient()
.get_run(dataset_run.run_id)
)
# 前処理
preprocess_run = mlflow.run(
uri="./preprocess",
entry_point="preprocess",
backend="local",
env_manager="local",
)
preprocess_run = (
mlflow
.tracking
.MlflowClient()
.get_run(preprocess_run.run_id)
)
# 以下も同じ感じ
# ...
if __name__ == "__main__":
app()
dataset/*
データセットダウンロード用の処理.
MLproject
ここでエントリーポイントの定義をしています.
main.pyに書いてあるentry_point引数と紐付いている(はず)です.
name: dataset
entry_points:
download:
command: "poetry run python src/dataset.py"
src/dataset.py
ここで以下の処理を書いていきます.
- データセット取得
- データセット出力(ローカルファイル)
- アーティファクト登録
まだまともに処理を書いていないので雰囲気だけ伝える目的ですw
~~~
def main():
# 学習用
torchvision.datasets.CIFAR10(
root=downstream_directory,
train=True,
download=True
)
# 評価用
torchvision.datasets.CIFAR10(
root=downstream_directory,
train=False,
download=True
)
~~~
mlflow.log_artifacts(
downstream_directory,
)
if __name__ == "__main__":
main()
実際にMLflowのUIを見てみるとデータセットのダウンロード単体でRunが作成されていて,アーティファクトなども保存されていることが確認できます.
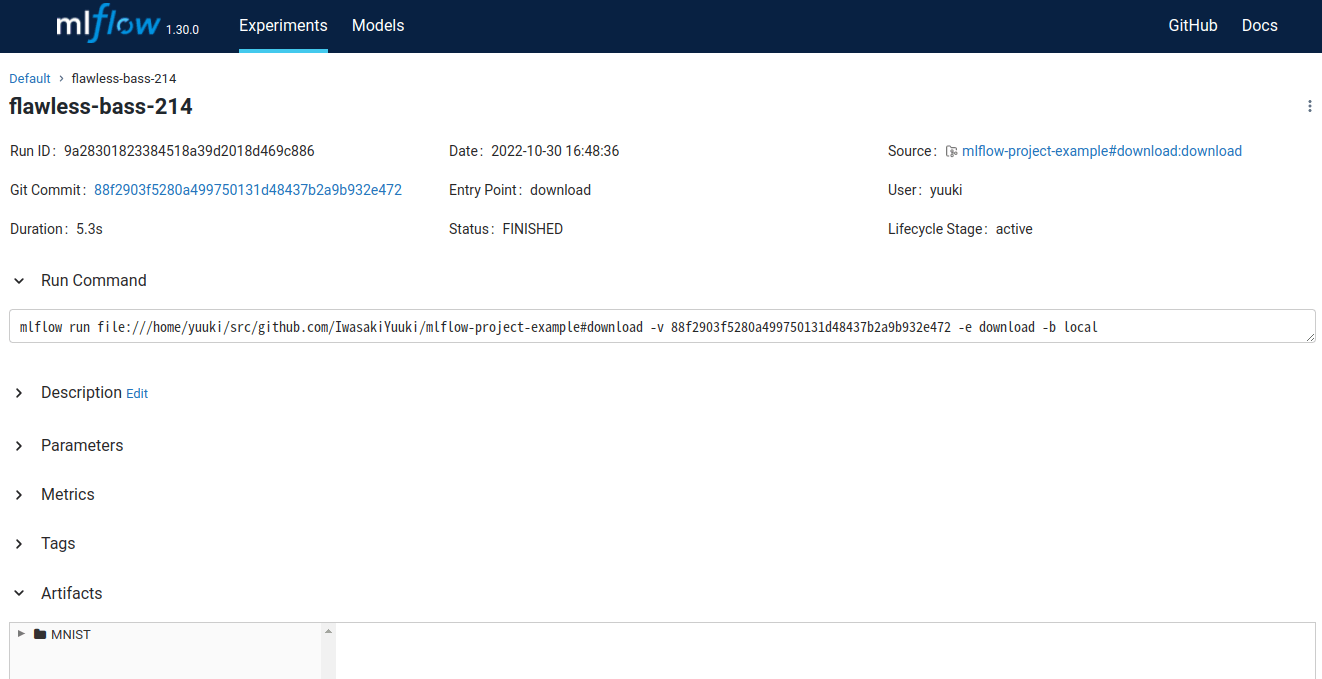
普段使っているときは,データセット作成からモデル評価まで一つのRunで完結していることが多いですが,正直こっちのほうが管理がしやすそうですね.
実験系のコードは適切な単位で分割することが難しいですが,この管理の仕方なら自然と役割ごとにコードが別れるはずなので再利用性も上がり,なおかつ,読みやすい実験コードになりそうです.
ただし,Runが複数に分かれるので,MLflowの便利な機能である「複数Runの比較」がちょっとしずらくなりそうですね.(パイプラインの処理単位で比較する必要がある)
次やること
- 他のパイプライン処理の実装
- MLprojectの設定調査(色々便利な機能がありそう)
- 実際にUI上で実験の比較をしてみて使用感を把握
Discussion