Transformers で Swin Transformer v2 をファインチューンして画像分類
Transformers
今回使ったバージョンは 4.34.1
Swin Transformer V2
オリジナルのレポ:
Transformers でのドキュメント:
9.9割以下のチュートリアルに従ってやるだけ
今回使ったベースモデルは microsoft/swinv2-base-patch4-window12-192-22k
(選んだ理由は、ファイルサイズが 400MB くらいでなんだか軽そうだったから。実際ものすごく軽かった。)
Microsoft の他の SwinV2 モデルは HuggingFace で検索すると出てくる
今回はフィギュア画像の美的基準での分類を学習した。画像データセットは ここ から画像 URL を取得してダウンロードした。
ダウンロードした後は、主観に基づいて手動で画像1500枚くらいを分類した。最終的な目的として、ダウンロードしたすべてのフィギュア画像の中から映りがいいものに絞りたいのと、怪獣系のフィギュアは省きたかったのでそういう観点で分類した。また、たまに入ってるパーツ分けされた画像や参考イラストも弾きたかったので、それらも別枠で分類した。
最終的には以下に分類した。
- train
- best quality: 113枚 (最高に綺麗な感じ)
- high quality: 340枚 (かなり綺麗)
- medium quality: 238枚 (普通な感じ)
- low quality: 249枚 (写りが悪いもの)
- worst quality: 223枚 (画像が分割されていたり、個人的に求めてない感じの画像もここに入れた)
- parts: 62枚 (パーツ分けされた画像)
- other: 46枚 (イラストとか全然フィギュアじゃないやつなど)
- test:
- best quality: 39枚
- high quality: 85枚
- medium quality: 56枚
- low quality: 77枚
- worst quality: 43枚
- parts: 12枚
- other: 19枚
今回はそれぞれのラベルの枚数の偏りを考えて train と test の両方個別に作成したのだが、もしかしたら普通に datasets の train_test_split でも大丈夫かもしれない。
また、この分類したデータセットは datasets ライブラリの ImageFolder 形式で読み込んだ。(ラベルとかも自動でつけてくれて読み込みが楽...)
参考:
フォルダーの構成は
- my_dataset
- train
- 0-best
- 1-high
- ...
- 6-other
- test
- 0-best
- ...
- train
のようにした。これは読み込むときにつけられるラベルが多分数値だけになる?ので一応つけた。エクスプローラーでの表示も上から順に高クオリティになるので直感的にも良い。
あとは本当にチュートリアル通り
from datasets import load_dataset, DatasetDict
from transformers import (
AutoImageProcessor,
AutoModelForImageClassification,
DefaultDataCollator,
TrainingArguments,
Trainer,
)
from torchvision.transforms import RandomResizedCrop, Compose, Normalize, ToTensor
import evaluate
import numpy as np
import wandb
CACHE_DIR = "/huggingface/cache" # これは個人的に使ってるだけ
MODEL_NAME = "microsoft/swinv2-base-patch4-window12-192-22k"
OUTPUT_NAME = 出力モデル名(と、wandbのプロジェクト名)
HUB_REPO_NAME = HuggingFaceのレポ名(アップするなら)
processor = AutoImageProcessor.from_pretrained(
MODEL_NAME,
cache_dir=CACHE_DIR,
)
normalize = Normalize(mean=processor.image_mean, std=processor.image_std)
size = (
processor.size["shortest_edge"]
if "shortest_edge" in processor.size
else (processor.size["height"], processor.size["width"])
)
_transforms = Compose([RandomResizedCrop(size), ToTensor(), normalize])
def transforms(examples):
examples["pixel_values"] = [
_transforms(img.convert("RGB")) for img in examples["image"]
]
del examples["image"]
return examples
dataset = load_dataset("imagefolder", data_dir="./dataset")
assert isinstance(dataset, DatasetDict)
dataset["train"] = dataset["train"].with_transform(transforms)
dataset["test"] = dataset["test"].with_transform(transforms)
print(dataset)
labels = dataset["train"].unique("label")
data_collator = DefaultDataCollator()
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return accuracy.compute(predictions=predictions, references=labels)
id2label = {
0: "best quality",
1: "high quality",
2: "medium quality",
3: "low quality",
4: "worst quality",
5: "parts",
6: "other",
}
label2id = {v: k for k, v in id2label.items()}
model = AutoModelForImageClassification.from_pretrained(
MODEL_NAME,
ignore_mismatched_sizes=True,
num_labels=len(labels),
id2label=id2label,
label2id=label2id,
cache_dir=CACHE_DIR,
)
wandb.init(project=OUTPUT_NAME)
training_args = TrainingArguments(
output_dir=OUTPUT_NAME,
remove_unused_columns=False,
evaluation_strategy="epoch",
save_strategy="epoch",
optim="adafactor",
lr_scheduler_type="cosine",
learning_rate=5e-5,
auto_find_batch_size=True,
gradient_accumulation_steps=4,
num_train_epochs=10,
save_total_limit=2,
save_safetensors=True,
warmup_ratio=0.1,
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
push_to_hub=True,
hub_model_id=HUB_REPO_NAME,
hub_private_repo=True,
report_to=["wandb"],
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
tokenizer=processor,
compute_metrics=compute_metrics,
)
trainer.train()
trainer.evaluate()
trainer.save_model(OUTPUT_NAME)
trainer.push_to_hub(HUB_REPO_NAME)
これで
python train_swinv2.py
して 8 分くらい待つと学習が終わった。
作成したモデルを検証するには gradio が便利。
今回の gradio バージョンは 4.7.1
from transformers import AutoImageProcessor
import torch
from PIL import Image
from transformers import AutoModelForImageClassification
import gradio as gr
CACHE_DIR = "/huggingface/cache"
MODEL_NAME = 学習したモデルのパス or レポ名
image_processor = AutoImageProcessor.from_pretrained(
MODEL_NAME,
cache_dir=CACHE_DIR,
)
model = AutoModelForImageClassification.from_pretrained(
MODEL_NAME,
cache_dir=CACHE_DIR,
)
def classify_image(image: Image.Image):
inputs = image_processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits.softmax(1)
results = {}
for scores in logits:
for i, score in enumerate(scores):
results[model.config.id2label[i]] = score.item()
return results
demo = gr.Interface(
fn=classify_image,
inputs=gr.Image(label="Input image", type="pil"),
outputs="label",
)
demo.launch()
かなり手触り良く動作を確認できる。
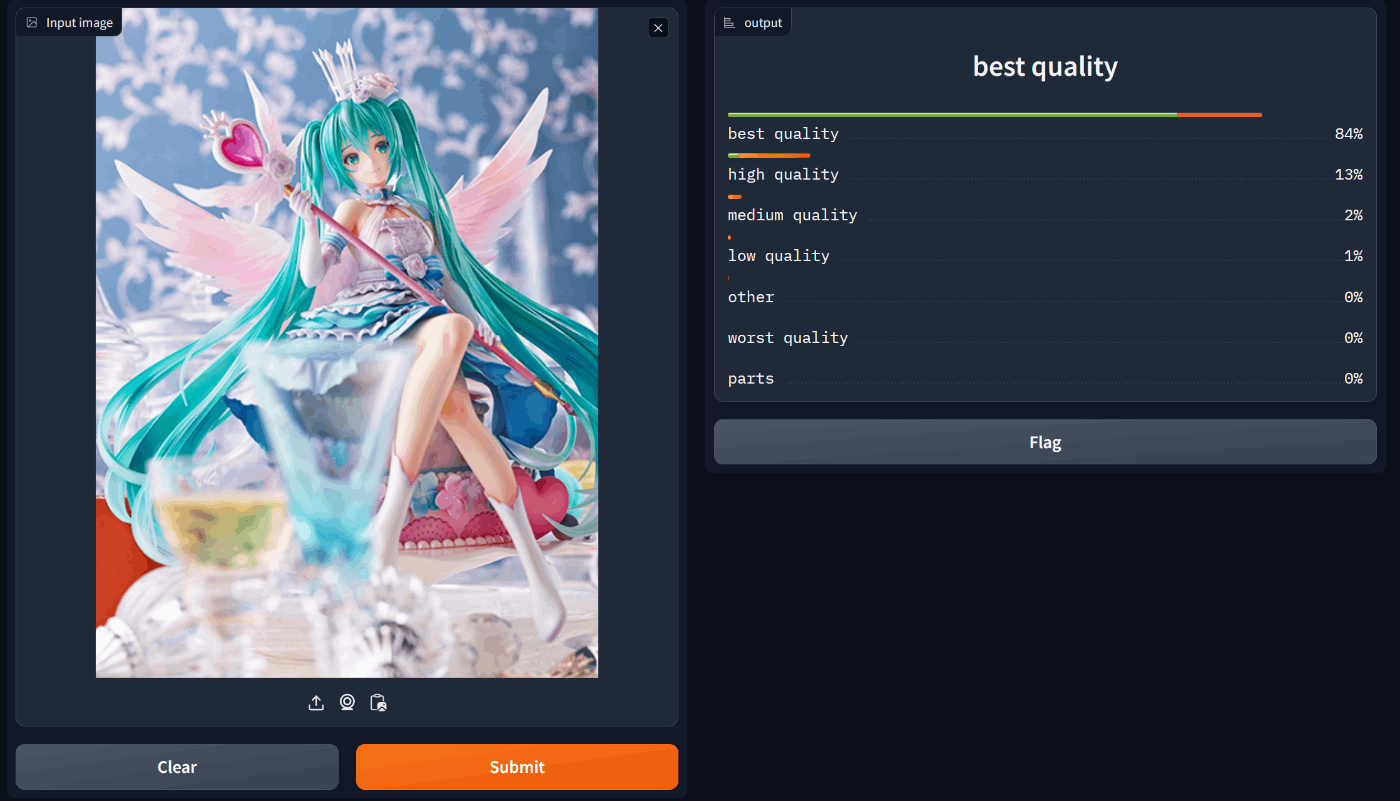
初音ミク Birthday 2020~Sweet Angel ver.~ 1/7スケールフィギュア (Spiritale)

ねんどろいどもあ とりかえっこフェイス呪術廻戦02 (Goodsmile)
綺麗な画像も顔パーツもそれぞれちゃんと分類できた。
ある程度分類ミスはあるかもしれないが、すべての画像を手作業で分類するよりは労力が少ないのでないよりはマシという感じ。綺麗な画像を綺麗な画像と分類できないのは困るけど、その逆なら自動分類後に手作業で省けばいいだけなのでかなり楽だと思う。
作成したモデルは以下。Inference API が有効なのでここからでも画像入れて遊べる。
README 見るとわかるが、数値的には Accuracy: 0.5317 でそこまで精度よくなさそうだが実用上はそんなに大きな支障はないと思う。
注意点として、このモデルは完全にフィギュア画像用に作ったのでイラストとか入れると全部 other に分類されて使えない。