Huggingface Inference Endpoints を触る
HTTP API 経由で HuggingFace 上 に上がっている Transformers とか Diffusers モデルを推論できるサービス。自動でスケーリングもできる。
CUDA 入った Linux サーバーを用意して~とかしなくていいので、本当に推論だけしたい場合は便利そうな感じ.
テキスト生成には text-generation-inference が使われる。
llama.cpp とかは動かないけど、text-generation-inference が対応している量子化 (AWQ, Bitsandbytes, AutoGPTQ ) は一応できる。
Inference Endpoints のダッシュボードページ
(アカウント設定から支払い方法を設定してないと使えない)
エンドポイントの作成画面。
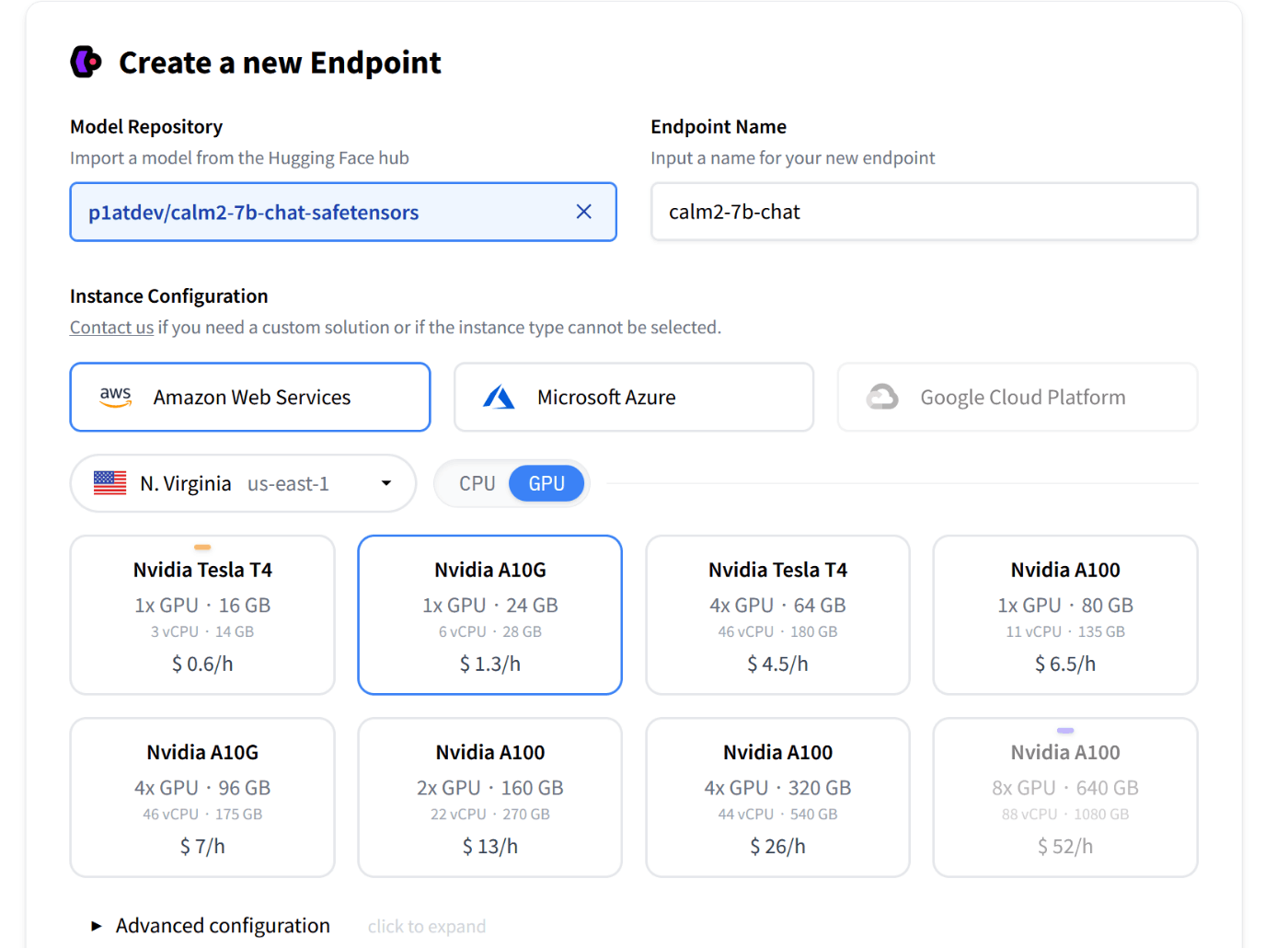
現状 GPU が使えるのは AWS だけなので GPU 使いたい場合は AWS を選ぶ。軽いモデルで CPU でもいいなら Azure も選べる。
HuggingFace 上のモデルを選択できる。
ここで、 safetensors に対応していないモデルを選ぶと、 text-generation-inference の仕様(?)でエラーを吐かれて死んでしまう[1]ので、safetensors 対応のを選ぶか自分で変換(transformersで読み込んでそのままアップでOK)しておく必要がある。

Advanced configuration では text-generation-inference のオプションを設定できる。量子化はなにか設定しておいたほうが良いかも。他の設定は詳しくないので知らない...
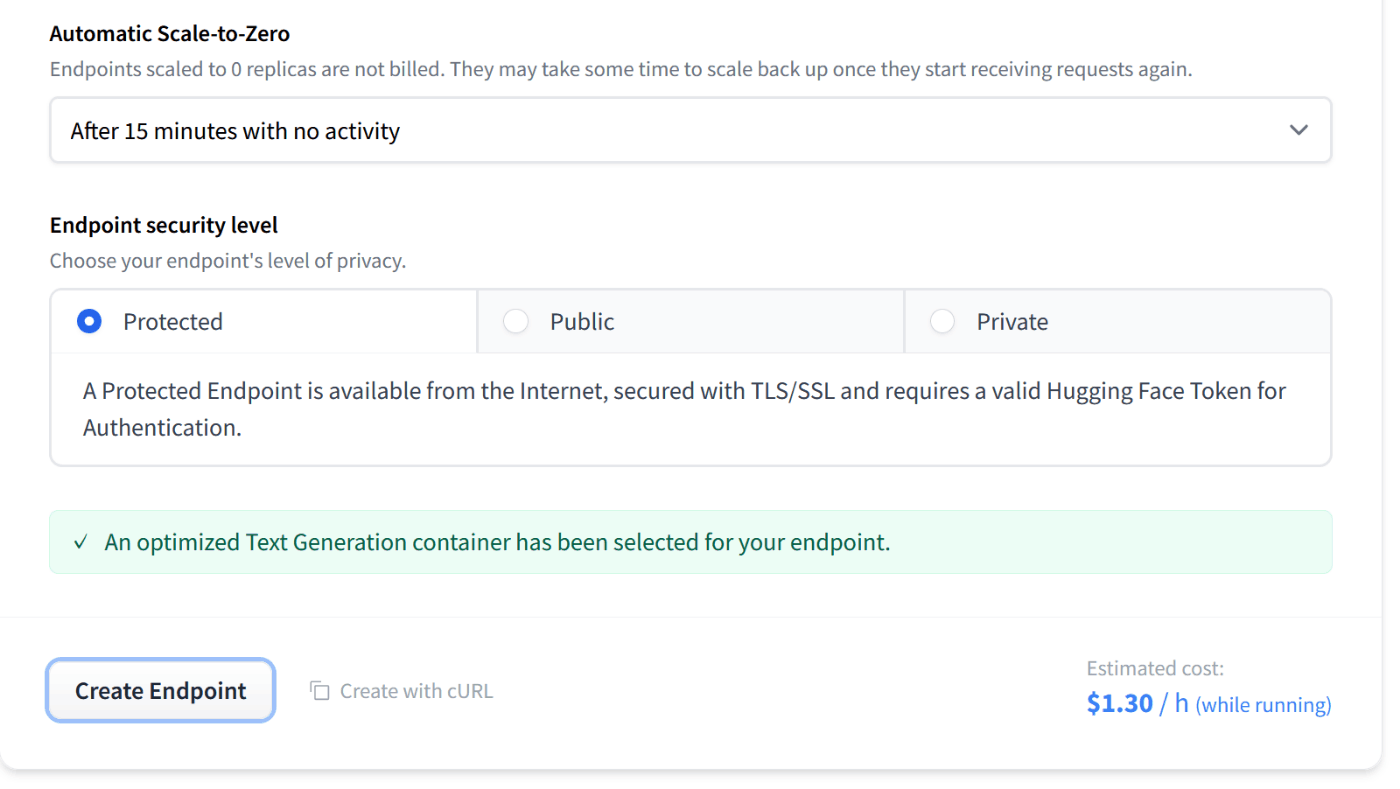
0インスタンスにスケールするオプションは、現在は
- 0 個にスケールしない
- 15分間アクセスなしでスケール
だけが選択できた。5 分とかの選択肢もあったが coming soon! だった。
これは普通にスケールする設定を選んでおいたほうがいいと思う。
Endpoint security level は
- Protected: 自分の HuggingFace トークンでアクセス可能
- Public: 誰でもアクセス可能
- Private: AWS の権限設定によってアクセス制限?
となっている。
エンドポイントを作成するとこうなる。

使い方はめちゃくちゃシンプルで、ヘッダーに READ 権限のトークンつけて POST リクエストを送るだけ。
Postman で送ってみた:
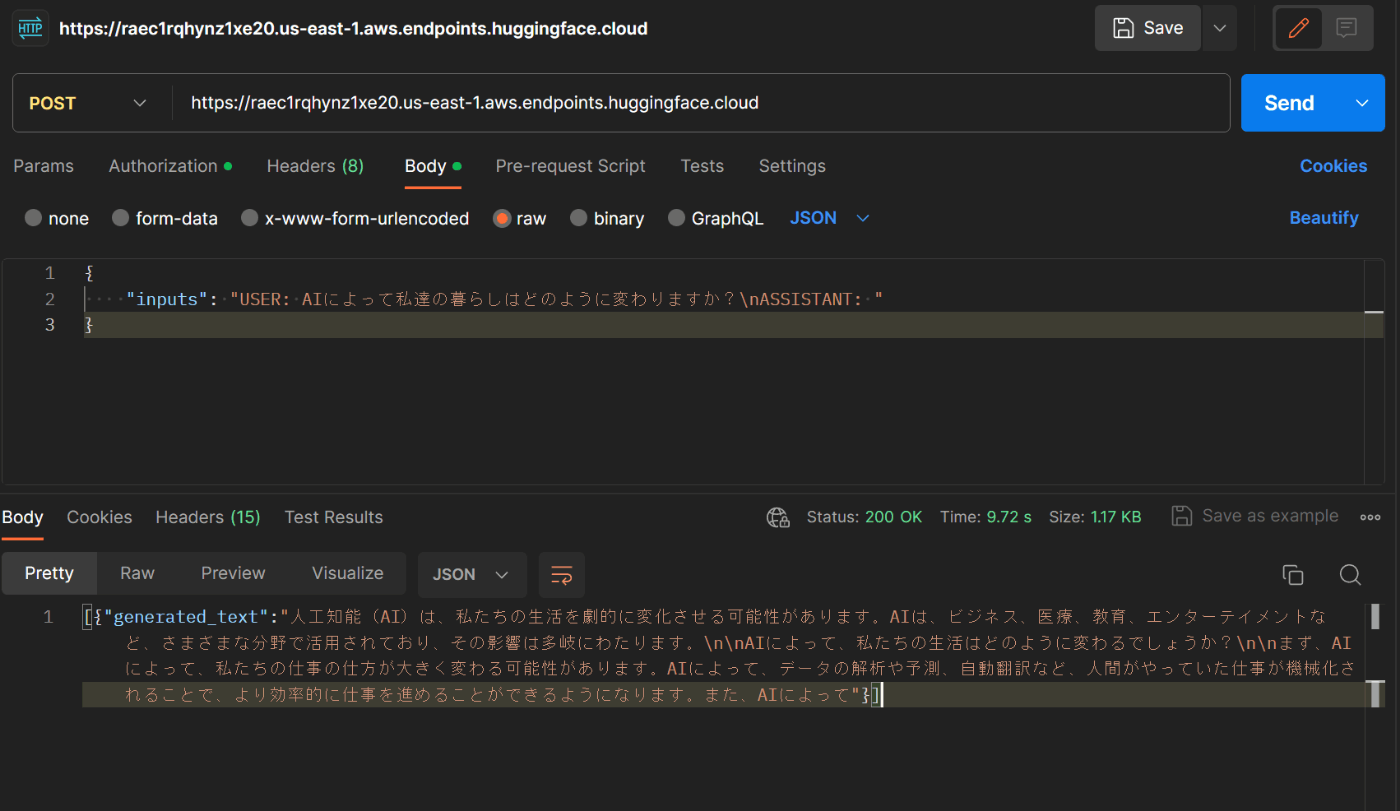
10 秒くらいで返ってきた。