ControlNetをトレーニングしたい
ControlNet
GitHub
arXiv
Stable Diffusion で指示画像を与えてそれにそって画像を生成するやつ
かなり軽量にいい感じのコントロール用モデルをトレーニングできる
学習のチュートリアル解説がついているのでまずはそれに従ってやる
黒背景に白い円が描かれた画像とそれに色がついた画像のペアを使って ControlNet をトレーニングする。
完全に解説そのままやるだけ。
git でレポを clone する
git clone https://github.com/lllyasviel/ControlNet
conda で環境作る
conda env create -f environment.yaml
(Python 3.8.5 に Torch 1.12 と少し古いが、おそらくこれは大事なのでそのまま従う)
データセット落とす
training フォルダを作成する
mkdir training
Hugging Face から円のデータセット fill50k.zip を落としてくる
wget https://huggingface.co/lllyasviel/ControlNet/blob/main/training/fill50k.zip
解凍
unzip fill50k
データセットの確認
python tutorial_dataset_test.py
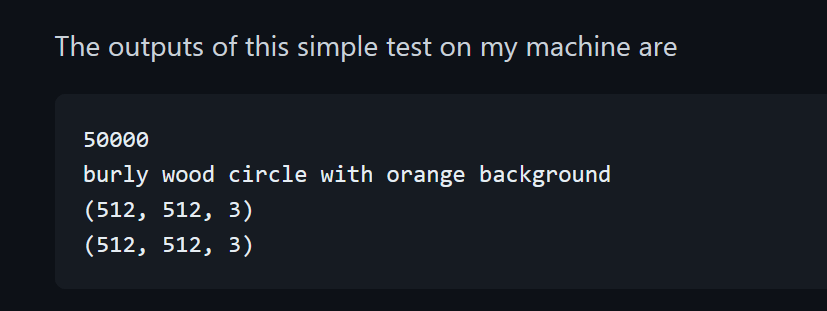
おそらくこうなる。
モデルの用意
適当にモデルを用意する。
私の中では v1 モデルは存在しないことになっているので v2系をつかう。(今更v1トレーニングする意味も薄いしね)
今回は WD 1.5 を使ったけど、ここはマジでぶっ壊れてるモデルじゃなければなんでもいいと思う。気分で WD1.5 にした。あと、ここはなぜか ckpt しか対応してないので safetensors だったらどうにかして ckpt に変換しよう。
もう既に Hugging Face から落としてきたとする
モデルをセットアップするので以下のように実行する
python tool_add_control_sd21.py models/wd-15-2.6-186k.ckpt models/control-wd15-2.6-186k-ini.ckpt
ちょっと待てば終わる。
学習する
あとはほんとに学習のコードを実行するだけなのだが、学習コードがめちゃくちゃシンプルで私でも理解できる程度だったので、軽く見ていこう
データセットを管理するコード
import json
import cv2
import numpy as np
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self):
self.data = []
with open('./training/fill50k/prompt.json', 'rt') as f:
for line in f:
self.data.append(json.loads(line))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
source_filename = item['source']
target_filename = item['target']
prompt = item['prompt']
source = cv2.imread('./training/fill50k/' + source_filename)
target = cv2.imread('./training/fill50k/' + target_filename)
# Do not forget that OpenCV read images in BGR order.
source = cv2.cvtColor(source, cv2.COLOR_BGR2RGB)
target = cv2.cvtColor(target, cv2.COLOR_BGR2RGB)
# Normalize source images to [0, 1].
source = source.astype(np.float32) / 255.0
# Normalize target images to [-1, 1].
target = (target.astype(np.float32) / 127.5) - 1.0
return dict(jpg=target, txt=prompt, hint=source)
初期化時に prompt.json (ヒント画像、正解画像の相対パスと正解画像のキャプションが入っている) を読み込んで、 [123] のようにインデックス指定されたときに、その番号に対応する画像とキャプションを返している。
ノーマライズはおそらく学習する際に入力に合うように変換しているだけだと思う。(多分)
非常にシンプルだし、これくらいなら簡単に改造できそうに思える。素晴らしい。
おそらくここでランダムにキャプションを削ったりするのだと思われる。(3.3 Training)
次は実行する学習コード
from share import *
import pytorch_lightning as pl
from torch.utils.data import DataLoader
from tutorial_dataset import MyDataset
from cldm.logger import ImageLogger
from cldm.model import create_model, load_state_dict
# Configs
resume_path = './models/control_sd21_ini.ckpt'
batch_size = 4
logger_freq = 300
learning_rate = 1e-5
sd_locked = True
only_mid_control = False
# First use cpu to load models. Pytorch Lightning will automatically move it to GPUs.
model = create_model('./models/cldm_v21.yaml').cpu()
model.load_state_dict(load_state_dict(resume_path, location='cpu'))
model.learning_rate = learning_rate
model.sd_locked = sd_locked
model.only_mid_control = only_mid_control
# Misc
dataset = MyDataset()
dataloader = DataLoader(dataset, num_workers=0, batch_size=batch_size, shuffle=True)
logger = ImageLogger(batch_frequency=logger_freq)
trainer = pl.Trainer(gpus=1, precision=32, callbacks=[logger])
# Train!
trainer.fit(model, dataloader)
モデルやハイパーパラメーターを指定し、読み込んで、 fit で学習を開始している。
私は機械学習をまったくやってないので学習コードがこんなにシンプルに収まるなんて想像できなかった。めちゃくちゃ複雑そうなコードを書いているイメージがあったのだが、さまざまなライブラリや先人のコードのおかげでここまでシンプルになるのだなと少し感動した。
モデルを指定したり、バッチサイズを変更したらあとは実行するだけ
python tutorial_train_sd21 .py
あとは待つ!
途中経過 (30時間くらい?)
A40、バッチサイズ 12 で回している
キャプション

ヒント画像

生成されたもの

正解

途中経過 (40時間)
キャプション

ヒント

生成結果

正解

途中経過 (48時間くらい)
キャプション

ヒント

生成結果

正解

学習を停止した (51時間ちょい)
キャプション

ヒント

生成画像

正解

これで十分だと思われる。
50k 枚の円の画像ペア、バッチサイズ12で A40 で 約50GPU時間かかって良い感じにトレーニングされた。
公式のモデル
時間があるので論文に載ってたモデルについて見てみる
ベースモデルはSD1.5じゃないのを太字にした
| 名前 | 意味 | データセット | ベースモデル | GPU | 学習時間 | 備考 |
|---|---|---|---|---|---|---|
| Canny Edge | 輪郭 | インターネットから3M | SD1.5 | A100 | 600時間 | 3Mはパない |
| Canny Edge (Alter) | 輪郭 | 上と同じもので、1k,10k,50k,500kで実験 | SD1.5 | A100 | 150時間 | |
| Hough Line | 直線 | Places2 (10M) | Canny Edge | A100 | 150時間 | Cannyからの継続。Houghに |
| HED | 輪郭 | インターネットから3M | SD1.5 | A100 | 300時間 | Cannyよりも曖昧な感じの輪郭? |
| User Sketching | 人間っぽいスケッチ | HEDのやつを調整したものとインターネットから500kペア | Canny Edge | A100 | 150時間 | |
| Openpifpaf | ポーズ | インターネットから80k | SD2.1 | RTX 3090TI | 400時間 | これだけ SD2.1ベース。だけどなぜか公開されてない。画像の制約として、人体が一定割合含まれている条件があった。 |
| OpenPose | ポーズ | インターネットから200k | SD1.5 | A100 | 300時間 | こちらも人体が一定割合含まれている条件がある。この条件で200kあつめるのたいへんそう... |
| Semantic Segmentaion (COCO) | 塗り分け | COCOから164k (BLIPでキャプション) | SD1.5 | RTX 3090TI | 400時間 | BLIPでキャプションが付け直されている |
| Semantic Segmentation (ADKE20K) | 塗り分け | ADE20Kから164k (BLIPでキャプション) | SD1.5 | A100 | 200時間 | こちらも |
| Depth (Midas) | 深度 | インターネットから3M | SD1.5 | A100 | 500時間 | |
| Depth (小規模) | 深度 | 上のやつから絞って200k | 他の条件書いてないけど多分おなじ? | |||
| Normal Maps | ノーマルマップ | DIODEから25,452ペア (BLIPでキャプション) | SD1.5 | A100 | 100時間 | なぜかこれだけ数が具体的に書いてある |
| Normal Maps (拡張) | ノーマルマップ | Midasで深度とってからノーマルマップを作成した | Normal Maps | A100 | 200時間 | 上のモデルからの継続 |
| Cartoon Line Drawing | 線画 | インターネットから取得して線画を抽出し、人気度が高いものから順に1Mペア | Waifu Diffusion (多分1.4?) | A100 | 300時間 | WDベース!!これはおそらくDanbooruから線画を抽出した?1Mペアは大変だ... 線画の抽出に使われたのはこれ |

ワッ...ワァ....
ControlNet v1.1
v1.0から継続でトレーニングされたものや、新しい種類のモデルが追加された。
また、v1.5まではモデルのアーキテクチャが変わらないことが保証された。(ほんとにv1.5シリーズまで出すの!?)
モデル名の命名のガイドラインが作られた。(今までどれがどれなのかわかりずらかったw)

v1.1のモデル
Depth
Midas、Leres、Zoeの3つのアノテーターと、256/384/512解像度の画像を使って学習された
Normal Maps
BAE のノーマルマップの手法を使ったもの (前回のMidasベースのやつはゴミなので破棄されたそう)
Canny・MLSD・Scribble (継続)
データセットは以前と同じで、前回のモデルから追加でA100で200時間学習された (贅沢な計算資源よ...)
Soft Edge
HEDのデータであんまりいい感じじゃないのがあったからやりなおした感じ?(よくわからん)
Segmentation
前回は別々だった COCO と ADE20K を一緒に学習したもの。ControlNetにとっては、色分けのルールなんか細かいことで、異なるルールの区分けを一緒に学習することで使いやすくなったらしい。
Openpose
前回は全身 (body) のみだったが、顔 (face)、全身 (body)、手 (hand) も一緒に学習して一緒に使えるようになったモデル。
Lineart
実写的なスケッチ。
Anime Lineart
ベースモデルに何使ってんだよ!?!?!?!????
イラスト線画。Anime2Sketch を使っている。
Shuffle
プロンプトで指示しながら reimagine 的な感じができたり?色の雰囲気を指定したり?する?スタイル転移的な?
InstructPix2Pix
本家のInstructPix2Pixよ... あいつはいいやつだったよ...
ControlNet でどのモデルでも、いい感じにPix2Pixできるようになった。
データセットは本家が公開しているものと、キャプションをちょっと加工して使ったらしい。
Inpaint
50%ランダムなマスクと50%の意図的なマスク?(ここ何言ってるのかわからなかった)で学習して、インペイントができるようにしたモデル。
ヒント画像作るのが楽そうなのでわりと気軽にトレーニングできそう。
Tile (未完成)
タイル(小さく区切って)で拡散して高解像度で出力するのに、プロンプトの影響をいい感じに伝わるように?作られたモデル
4k画像が200k枚つかわれている (どこから集められるんだろう...)
実はあの円のやつは思いっきり間違えたことをやっていた。
あの ./models/cldm_v21.yaml は、デフォルトで用意されている SDv2.1 向けの設定ファイルなのだが、これは base モデル向けであり、768解像度のモデル向けではない。少し修正する必要があるのだ。
具体的にはこのようにする
model:
target: cldm.cldm.ControlLDM
params:
+ parameterization: "v"
linear_start: 0.00085
linear_end: 0.0120
num_timesteps_cond: 1
log_every_t: 200
timesteps: 1000
first_stage_key: "jpg"
cond_stage_key: "txt"
control_key: "hint"
image_size: 64
channels: 4
cond_stage_trainable: false
conditioning_key: crossattn
monitor: val/loss_simple_ema
scale_factor: 0.18215
use_ema: False
only_mid_control: False
control_stage_config:
target: cldm.cldm.ControlNet
params:
use_checkpoint: True
image_size: 32 # unused
in_channels: 4
hint_channels: 3
model_channels: 320
attention_resolutions: [ 4, 2, 1 ]
num_res_blocks: 2
channel_mult: [ 1, 2, 4, 4 ]
num_head_channels: 64 # need to fix for flash-attn
use_spatial_transformer: True
use_linear_in_transformer: True
transformer_depth: 1
context_dim: 1024
legacy: False
unet_config:
target: cldm.cldm.ControlledUnetModel
params:
use_checkpoint: True
image_size: 32 # unused
in_channels: 4
out_channels: 4
model_channels: 320
attention_resolutions: [ 4, 2, 1 ]
num_res_blocks: 2
channel_mult: [ 1, 2, 4, 4 ]
num_head_channels: 64 # need to fix for flash-attn
use_spatial_transformer: True
use_linear_in_transformer: True
transformer_depth: 1
context_dim: 1024
legacy: False
first_stage_config:
target: ldm.models.autoencoder.AutoencoderKL
params:
embed_dim: 4
monitor: val/rec_loss
ddconfig:
#attn_type: "vanilla-xformers"
double_z: true
z_channels: 4
resolution: 256
in_channels: 3
out_ch: 3
ch: 128
ch_mult:
- 1
- 2
- 4
- 4
num_res_blocks: 2
attn_resolutions: []
dropout: 0.0
lossconfig:
target: torch.nn.Identity
cond_stage_config:
target: ldm.modules.encoders.modules.FrozenOpenCLIPEmbedder
params:
freeze: True
layer: "penultimate"
そう、v-prediction を有効にしなければならない。これをせずに学習すると、あらゆる画像を茶色にする ControlNet が完成する (一敗)。
ステップ 0 時点で出力される画像が、無駄に汚い茶色だったり、意味の分からない画像であった場合は yaml ファイルが間違っている。
なぜなら、ControlNet モデルで追加される zero convolution のレイヤーとは別に、もとからあるネットワーク構造は破壊されないため、かならずキャプションに沿った何かしら意味のある画像が生成されるはずだからだ。
意味不明な画像が出てきたら、その時点でそのモデルは壊れている。
今後 768 解像度で ControlNet を学習しようとしている人がいたら気を付けてほしい...