SDXL調整してみたい
XLのアクセス権を得た(というか実質解放)ので調整してみたい
失敗した記録も成功した記録も、一応何やったのか書いていく
sd-scripts の sdxl ブランチの差分を覗いてSDXL向けの主要な変更点とかを見てみる
-
sdxl_train.pyが追加された。fine_tune.pyの SDXL 版みたいなものだが、 DreamBooth 型のデータセットもサポートされる (要は、JSONとか用意しなくても良いっぽい) -
sdxl_train_network.pyが追加された。train_network.pyの SDXL版で、LoRAとかのトレーニングができる -
--cache_text_encoder_outputsオプションが追加。テキストエンコーダーの出力をキャッシュできるのでその分の VRAM 消費を抑えられるが、代わりにキャプションのシャッフルなどはできなくなる。(SDXL はテキストエンコーダーが2コついてるためちょっと負荷高い) -
requirements.txtが SDXL 用に更新された
SDXL 学習のヒントが載っていたのでまとめる
- SDXL の基本的な解像度(バケット) は 1024x1024 (デカイ)
- ファインチューン (
sdxl_train.py) ではバッチサイズ1でも 24GB の VRAM が必要で、以下のオプションが推奨- U-Net のみの学習
- gradient checkpointing を有効にする
-
--cache_text_encoder_outputsでテキストエンコーダーの出力と、--cache_latentsなどで latents をキャッシュする - Adafactor オプティマイザが良いらしい。RMSprop 8bit と Adagrad 8bit も動くかもらしいが、AdamW 8bit はうまくいかないらしい。
- こちら の情報によれば、 Prodigy は結構いい感じらしい。
- LoRA の学習 (
sdxl_train_network.py) は 12GB の VRAM が必要 (追記: RAM も相当数ないとかなり厳しい。VRAM は 16GB あれば十分。RAM は 16GB よりも多く欲しい感覚がある。)-
--network_train_unet_onlyが強く推奨される。(前述したように SDXL はテキストエンコーダーが2つついててめんどうなので) - PyTorch v2 をつかうと v1 よりも VRAM 消費が少ないらしい
-
Adafactor でのハイパーパラメーター例
optimizer_type = "adafactor"
optimizer_args = [ "scale_parameter=False", "relative_step=False", "warmup_init=False" ]
lr_scheduler = "constant_with_warmup"
lr_warmup_steps = 100
learning_rate = 4e-7 # SDXL original learning rate
何回か試していって、出力や設定などを載せていく(予定)
画像なくてさみしいので、これは学習前 SDXL 0.8 base の喫煙ミクさん

prompts
positive: high quality production photography of a nendoroid of hatsune miku wearing sunglasses smoking
negative: worst quality, blurry, low poly, horror, cartoon, nostrils, bad anatomy, watercolor, marker, retro, ukiyo-e, disney, pixar, 1990s, 2000s
普通に Google Colab (無料T4) で進めていたところ、以下のエラーに遭遇した
!python ./sdxl_train_network.py --config_file "/content/config.toml"
を実行すると

略
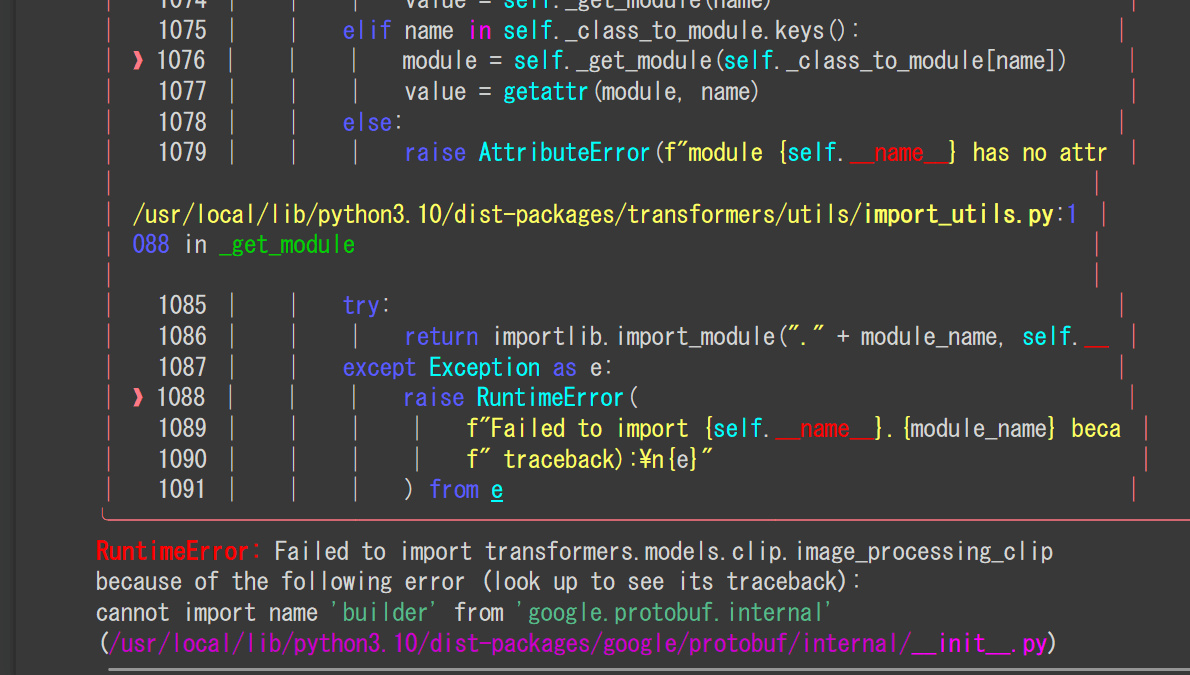
cannot import name 'builder' from 'google.protobuf.internal'
らしい。
Google Colab使っているとたまに見かけるバグな気がするが、たしか Tensorflow をぶったたくと治った記憶がある。
%pip uninstall tensorflow protobuf -y
%pip install tensorflow
を実行したところ治った。
diffusers 形式で sdxl のレポを指定したら、現状は diffusers 形式に対応していないようだ

なので、直接モデルをダウンロードして使うことにした。
無料の Colab では VRAM よりも RAM が足りなくて、モデルの読み込みでクラッシュしてしまった

これを回避するためにつぎの2つのことをやってみた
-
--lowramオプションの有効化。RAM の代わりに VRAM にモデルを読み込む-
--lowramを使うために.safetensorsモデルを.ckptに変換...
-
safetensors の都合で、なぜか直接 cuda にモデルを載せられないため、 ckpt 形式にする必要があるのだ
import torch
from safetensors.torch import load_file
state_dict = load_file(f"{MODEL_DIR}/sd_xl_base_0.9.safetensors")
torch.save(state_dict, f"{MODEL_DIR}/sd_xl_base_0.9.ckpt")
のようにして変換した。
が...

今度は VRAM が吹っ切れてクラッシュ...
よって、現状は無料版 Colab では学習できないという結論に...
悲しいので Runpod で最低限の性能もった GPU を借りることにした。
| 項目 | 内容 |
|---|---|
| GPU | RTX 3090Ti (Community Cloud) |
| VRAM | 24 GB |
| RAM | 30GB |
| Container Disk | 15GB |
| Volume Disk | 50GB |
| Cost | -$0.369/hr |
| テンプレ | cuda118載ったオリジナルのやつ |
tailscale いれてリモートから繋いで、miniconda 入れて Python 環境を整えた (これはテンプレートがやった)。
Python は 3.10 (conda create -n kohya python=3.10)、PyTorch はコピペで pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 した。
pip show torch したら 2.0.1+cu118 だった。
その後は、いろいろ入れた。
sdxl ブランチで sd-scripts を clone。
git clone -b sdxl https://github.com/kohya-ss/sd-scripts.git
pip
pip install xformers
pip install dadaptation prodigyopt
pip install wandb
pip install -r ./requirements.txt # sd-scripts
諸々にログイン
huggingface-cli login
wandb login
データセットのダウンロードは各自で。
モデルをダウンロード (地味につらい)
huggingface の自動ダウンロードは、勝手に Container Disk の方にキャッシュを作りやがるので、今回のようにケチってると全部ダウンロードしきれない。
なので以下のスクリプトでダウンロードした。
from huggingface_hub import hf_hub_download
hf_hub_download(
repo_id="stabilityai/stable-diffusion-xl-base-0.9",
repo_type="model",
filename="sd_xl_base_0.9.safetensors",
revision="main",
local_dir="./models/sdxl_base_09.safetensors",
cache_dir="/workspace/cache",
local_dir_use_symlinks=False,
)
/workspace でキャッシュするように指定する (/workspace が Volume 領域) と、ちゃんとダウンロードできる。また、トークンとかは事前に huggingface-cli login してればおk。
一応 accelerate config を行った。(基本的にエンターキー連打で fp16 選んだ。)
Colab とかでやるなら、代わりに以下を実行するといいと思う。(多分)
from accelerate.utils import write_basic_config
write_basic_config()
あとは学習を始めるだけ
accelerate launch --num_cpu_threads_per_process 1 ./sdxl_train_network.py --config_file "/workspace/config.toml"
か、
python ./sdxl_train_network.py --config_file "/workspace/config.toml"
で開始する。
今回の学習設定は以下。
注意点として、mixed_precision を fp16 で行ったところ、 latent のキャッシュで NaN が発生してなーんとなってしまったので、bf16 を使っている。
config_file
今回は この先行研究 に従って Prodigy を使用しているが、果たしてうまくいくのかはわからない。多分結果がわかった時点で追記されていると思うのでそちらを参照。
pretrained_model_name_or_path = "/workspace/models/sd_xl_base_0.9.safetensors"
output_dir = "/workspace/output"
# hyperparameters
lr_scheduler = "cosine"
# lr_scheduler_num_cycles = 5
lr_warmup_steps = 100
max_token_length = 150
max_train_epochs = 50
optimizer_args = ["weight_decay=0.01", "decouple=True", "use_bias_correction=True"]
optimizer_type = "prodigy"
seed = 3407
cache_latents = true
cache_latents_to_disk = true
gradient_checkpointing = true
# min_snr_gamma = 5
lowram = false
mixed_precision = "bf16"
xformers = true
# save_every_n_epochs = 1
save_every_n_steps = 1000
# save_last_n_epochs = 5
save_last_n_steps = 5
# lora
learning_rate = 1
# unet_lr = 5e-6
network_train_unet_only = true
network_alpha = 1
# network_args = ["conv_dim=8", "conv_alpha=1"]
network_dim = 8
network_module = "networks.lora"
# network_weights = ""
persistent_data_loader_workers = true
prior_loss_weight = 1.0
# XL
# cache_text_encoder_outputs = true
# logging
log_prefix = "sdxl_09_pvc_1-"
log_tracker_name = "sdxl_09_pvc_1"
log_with = "wandb"
logging_dir = "/workspace/logs"
# sample
sample_every_n_steps = 1000
# sample_every_n_epochs = 1
sample_prompts = "/workspace/sample.toml"
sample_sampler = "euler_a"
# dataset
dataset_config = "/workspace/dataset.toml"
debug_dataset = false
(ほんとうは huggingface に自動でアップするオプションつけると楽だと思うのですが、ちょっとめんどくさくてやってないです)
データセットの構造。
max_bucket_reso はデフォルトだと 1024 なので、多分余裕あるっしょ~ということで 1728 まで盛った。今回は batch_size 4 で行ったが、わりと余裕あるので解像度減らしたらもっと batch_size 増やしたり gradient_checkpointing をオフにしてもよいかもしれない。
dataset.toml
[general]
caption_extension = '.txt'
enable_bucket = true
shuffle_caption = true
# caption_dropout_rate = 0.01
# caption_tag_dropout_rate = 0.6
# color_aug = true
flip_aug = true
# これは DreamBooth 方式のデータセット
[[datasets]]
batch_size = 4
max_bucket_reso = 1728 # same as sdxl
resolution = 1024
[[datasets.subsets]] # 640
image_dir = '/workspace/train/figma'
num_repeats = 3
[[datasets.subsets]] # 800
image_dir = '/workspace/train/nendoroid'
num_repeats = 2
[[datasets.subsets]] # 190
image_dir = '/workspace/train/spiritale'
num_repeats = 3
[[datasets.subsets]] # 750
image_dir = '/workspace/train/tokyofigure'
num_repeats = 2
sample.toml
[prompt]
sample_steps = 20
scale = 7
height = 768
negative_prompt = "low quality, blurry, ugly, horror, retro, 1990s, 2000s, ukiyo-e, pixar, disney"
width = 512
[[prompt.subset]]
prompt = "1girl, aqua eyes, baseball cap, blonde hair, closed mouth, earrings, green background, hat, hoop earrings, jewelry, looking at viewer, shirt, short hair, simple background, solo, upper body, yellow shirt"
seed = 12345
[[prompt.subset]]
prompt = "1girl, blue hair, cat ears, parted bangs, white dress shirt, looking at viewer, wariza, sitting"
seed = 55555
[[prompt.subset]]
prompt = "high quality production photography of a nendoroid of hatsune miku wearing sunglasses smoking"
seed = 999
学習中の GPU の状態
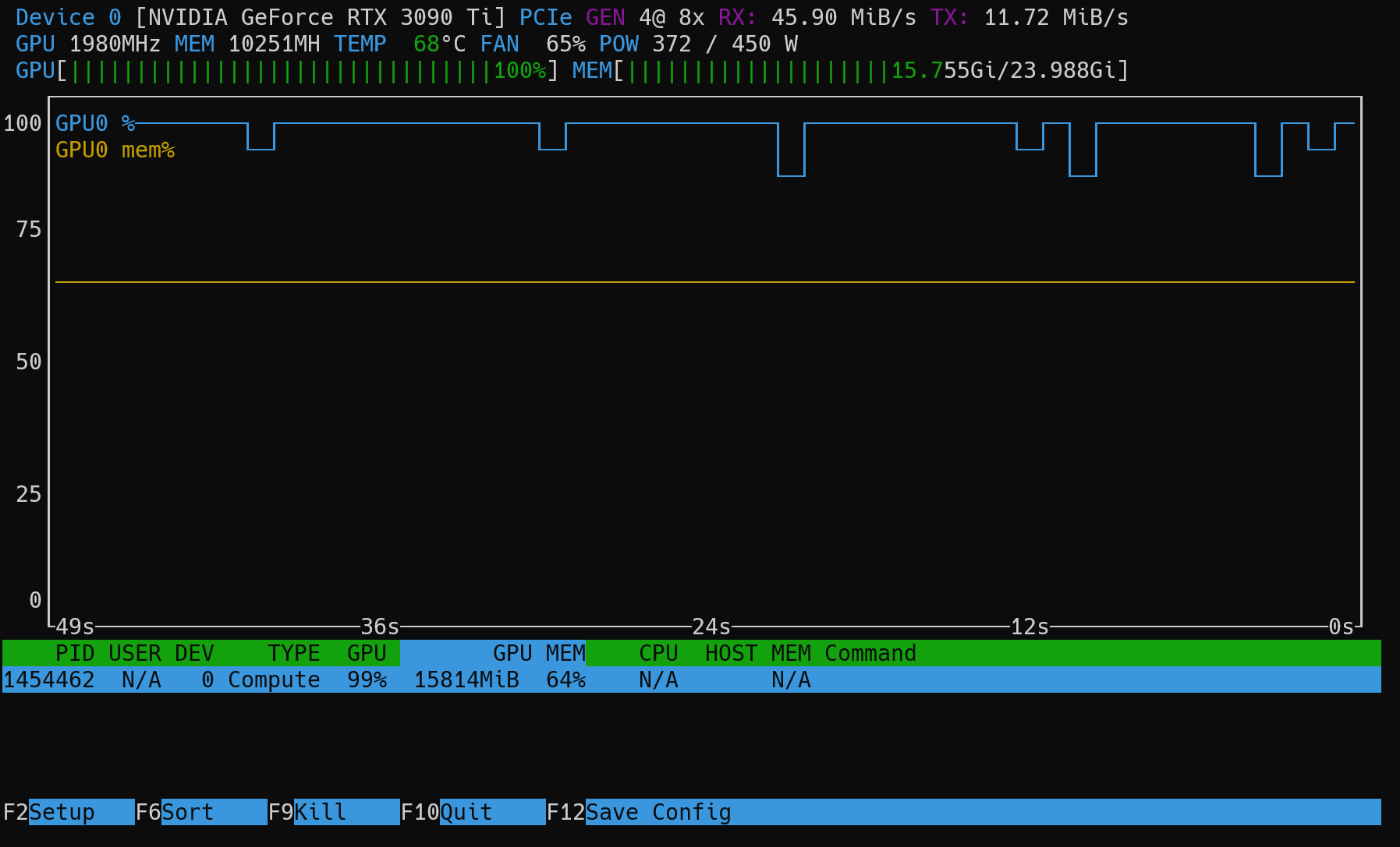
黄色の線がVRAM消費割合です。処理中のバケットによっては上下すると思いますが、割りと余裕あります。
(余談ですが、nvtop を使うとこういうかっこいい感じのモニタリングができるのでおすすめです)
一度作成した .npz ファイルを一括削除するスクリプト。
バケットに NaN があったり、途中でとめちゃったり解像度変えたいときには一度削除してキャッシュし直すといい。
ChatGPT に聞いて3秒くらいで返ってきたコードです。
import os
import glob
# 削除したいファイルが存在するディレクトリのパスを指定します。
dir_path = './train'
# 指定したディレクトリ内のすべての .npz ファイルのパスを取得します。
npz_files = glob.glob(os.path.join(dir_path, '*.npz'))
# 各 .npz ファイルを削除します。
for file in npz_files:
os.remove(file)
print("All .npz files have been deleted from the directory.")
学習中のサンプルが出てなくて暇なので余談
余談
今回は Runpod上のファイルを編集したりするのに code-server を利用しました。
ブラウザ経由でmほぼ VSCode の感覚でファイル編集やターミナル操作を行うことができてとてもとても便利。Jupyter Notebook だけ少し挙動が不安定なので使ってないのだが、 設定ファイルをちょっと調整したりするときにマジで便利なのでおすすめです。
Tailscale と組み合わせればパスワード認証もつけなくて大丈夫なので、超便利。どこかリモートのサーバーにアクセスするときは Tailscale 使えるようにしておくとめっちゃ楽です。
デフォルトのターミナルの見た目がちょっとかわいくないときは、starship がおすすめです。これは Windows とかにも対応しているので、お使いの PC にインストールしてもいいかも。
最初の1000ステップ時のサンプル出力

1girl, aqua eyes, baseball cap, blonde hair, closed mouth, earrings, green background, hat, hoop earrings, jewelry, looking at viewer, shirt, short hair, simple background, solo, upper body, yellow shirt
微塵も黄色くなくて泣いちゃった

1girl, blue hair, cat ears, parted bangs, white dress shirt, looking at viewer, wariza, sitting
こっちは案外近い感じになっているが...

high quality production photography of a nendoroid of hatsune miku wearing sunglasses smoking
かなり上の方で挙げた画像と比べるとかなりクオリティの低いものになっているし、全然ミクじゃないし、ねんどろいどでもない。
ただ、特に何も指定してなくてもフィギュアの質感にはなってくれたので、学習不足なのか妙に過学習してしまったのか、どちらなのかはわからない...
ロスはこんな感じ

これ以降改善しているのか、まったく変化していないのか、それとも悪くなっているのかなにもわからない...
AdaFactorが気になったので、こっちにして一晩放置してみた。
# hyperparameters
learning_rate = 1e-5
lr_scheduler = "constant_with_warmup"
# lr_scheduler_num_cycles = 5
lr_warmup_steps = 100
max_token_length = 150
max_train_epochs = 50
# optimizer_args = ["weight_decay=0.01", "decouple=True", "use_bias_correction=True"]
# optimizer_type = "prodigy"
optimizer_args = ["scale_parameter=False", "relative_step=False", "warmup_init=False"]
max_grad_norm = 1.0
optimizer_type = "AdaFactor"
seed = 3407
1万ステップくらいでこのようなサンプル
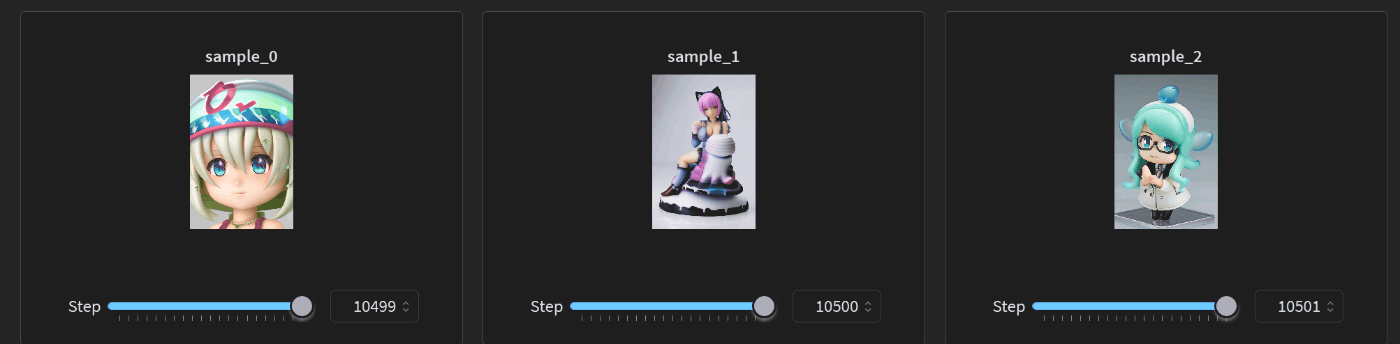
ロスはわりと暴れている

ロスが一番低い 6000 あたりのサンプルはというと

なんかミクが箱になってる....
ちゃんと学習できるオプティマイザ設定と学習できないらしい設定
基本的にLoRAはなんでも動くらしいです。
LoRA で動作したっぽいオプティマイザ設定例
- AdaFactor 1e-5
optimizer_type = "AdaFactor"
learning_rate = 1e-5
lr_scheduler = "constant_with_warmup"
lr_warmup_steps = 100
max_grad_norm = 1.0
optimizer_args = [ "scale_parameter=False", "relative_step=False", "warmup_init=False",]
ソース: https://huggingface.co/Linaqruf/sdxl_lora/blob/main/hitokomoru_xl_lora_config/config_file.toml
--max_grad_norm について:
デフォルトで1.0 らしいので設定しなくてもよさそう。
- Prodigy 1
optimizer_type = "prodigy"
learning_rate = 1
lr_scheduler = "cosine"
lr_warmup_steps = 100
optimizer_args = ["weight_decay=0.01", "decouple=True", "use_bias_correction=True"]
ソース: https://civitai.com/articles/1022
なんか d_coef=$d_coef とか if($lr_warmup_steps){ とか設定されているのだがよくわからない...
- AdamW 1e-4 (by ddPn08)
- Lion 3e-5 (by ddPn08)
- Lion 8bit 3e-5 (by ddPn08)
ファインチューニングで動作するらしいオプティマイザ設定例
- AdaFactor 4e-7
optimizer_type = "AdaFactor"
learning_rate = 4e-7
lr_scheduler = "constant_with_warmup"
lr_warmup_steps = 100
max_grad_norm = 1.0
optimizer_args = [ "scale_parameter=False", "relative_step=False", "warmup_init=False",]
ソース: https://huggingface.co/Linaqruf/sdxl_finetune/blob/main/sdxl_finetune_config/config_file.toml
4e-7 という学習率自体は SDXL と同じものらしい。
ファインチューニングで動作しないらしいオプティマイザ設定例
VRAM24GBでも足りなくなるらしい
- RMSprop 8bit
- AdamW 8bit
- AdamW
network_dim = 8、alpha 1 で約 80MB、network_dim = 32、alpha 1 で約 320 MB の LoRA となった。
ComfyUI の設定で、追加の LoRA ディレクトリを指定しても読み込んでくれなかったので以下対処法。
{ComfyUIのインストールディレクトリ}/models/lora というディレクトリがあると思うので、そこに使いたい LoRA をいれると読んでくれる。
多分バグで外部の LoRA を読み込めてない。
関連して、ComfyUI のメモ
SDXL を HDD とかに置いていると、初回読み込みは数分ぐらいかかるので少しだけ注意。ログも全然出なくて不安になると思うけど、気長に待つとちゃんと読み込んでくれるので待とう。また、halfしたモデルだとだいぶ読み込みが速い気がするのでそっちつかってもいいかも。
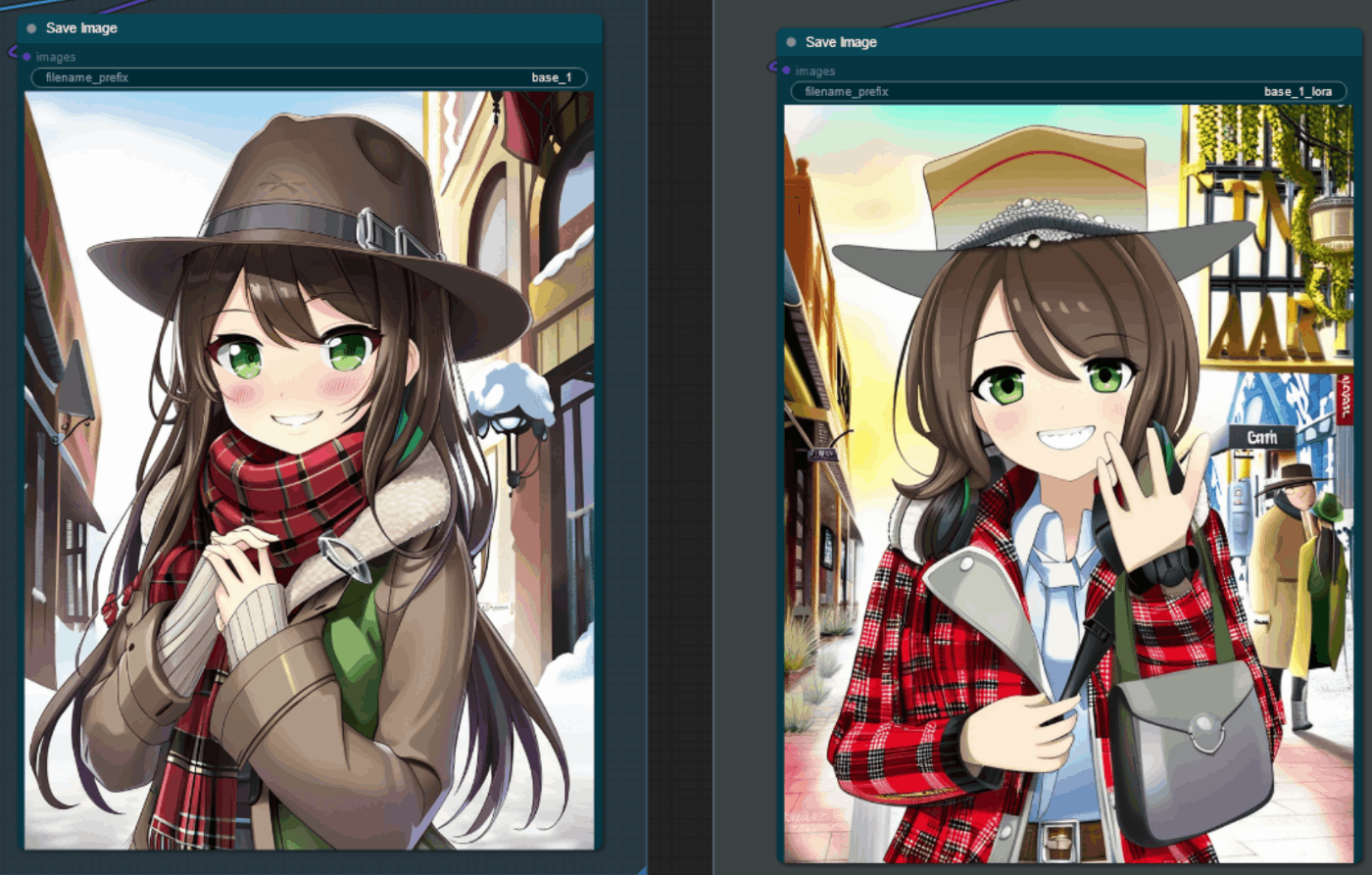
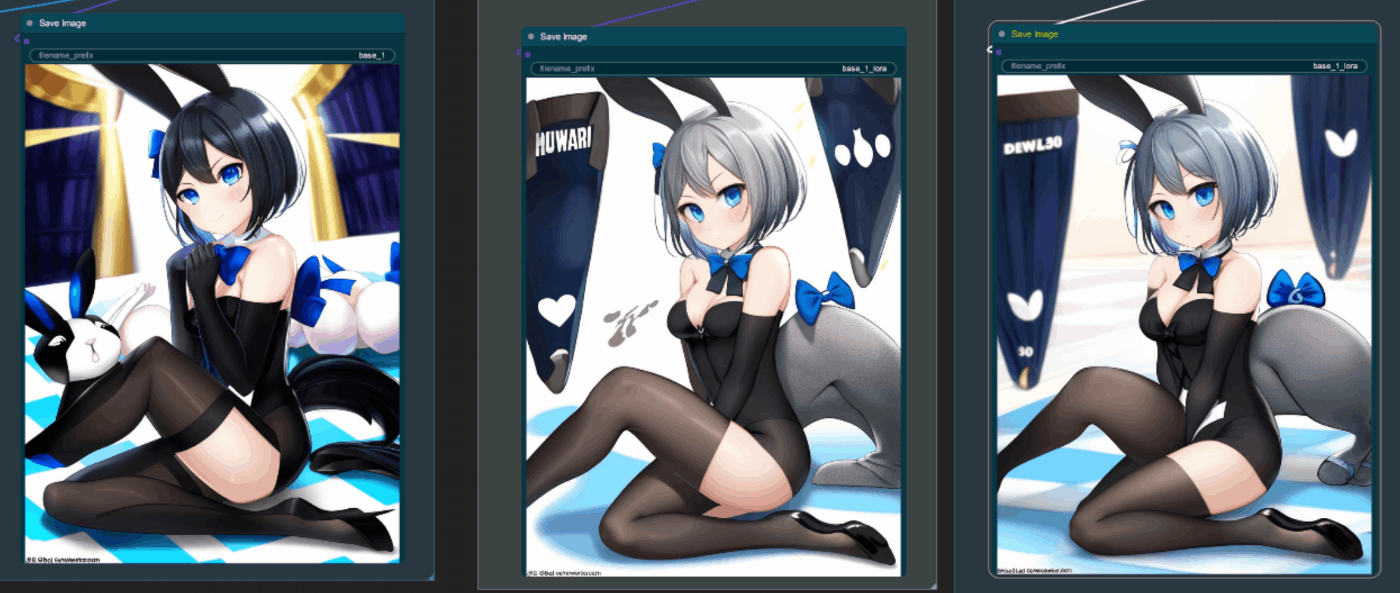
AdaFactor 1e-5 で 12k ステップ回した LoRA の出力など
左が LoRA なし、右が LoRA あり

positive: 1girl, solo, hatsune miku,
negative: worst quality, blurry, low poly, horror, cartoon, nostrils, bad anatomy, watercolor, marker, retro, ukiyo-e, disney, pixar, 1990s, 2000s
特にフィギュアを指定しなくてもちゃんとフィギュアになりました

喫煙ねんどろいどミク比較
もとのSDXLの方がポーズとかは自然だが、まあこれは学習してる画像の多くが直立してる商品画像なせいがあると思う
AdaFactorの12kステップでは、9時間45分の学習で、だいたい$4~5かかった
AdamW 1e-5 で 7000ステップほど学習してみた
config.toml
pretrained_model_name_or_path = "/workspace/models/sd_xl_base_0.9.safetensors"
output_dir = "/workspace/output_4"
# hyperparameters
learning_rate = 1e-5
lr_scheduler = "constant_with_warmup"
lr_scheduler_num_cycles = 5
lr_warmup_steps = 100
max_token_length = 150
max_train_epochs = 50
optimizer_type = "AdamW"
seed = 3407
cache_latents = true
cache_latents_to_disk = true
gradient_checkpointing = true
# min_snr_gamma = 5
lowram = false
mixed_precision = "bf16"
xformers = true
# save_every_n_epochs = 1
save_every_n_steps = 500
# save_last_n_epochs = 5
save_last_n_steps = 2500
network_train_unet_only = true
network_alpha = 16
# network_args = ["conv_dim=8", "conv_alpha=1"]
network_dim = 64
network_module = "networks.lora"
# network_weights = ""
persistent_data_loader_workers = true
prior_loss_weight = 1.0
# XL
# cache_text_encoder_outputs = true
# logging
log_prefix = "sdxl_09_pvc_1-"
log_tracker_name = "sdxl_09_pvc_1"
log_with = "wandb"
logging_dir = "/workspace/logs"
# sample
sample_every_n_steps = 500
# sample_every_n_epochs = 1
sample_prompts = "/workspace/sample.toml"
sample_sampler = "euler_a"
# dataset
dataset_config = "/workspace/dataset.toml"
debug_dataset = false
データセットとかはほぼ同じだが、一部キャプションを修正した。
ロス

エポックの繰り返し数50回とか指定してるけど、多分普通に5回とか、多くても10回である程度学習できちゃうと思う。多く指定しても途中で止めちゃうなら cosine の意味がなくなっちゃうw
学習ステップ数が違うので単純な比較ができないのだけど、左は AdamW 1e-5 7k ステップ、右は先程の AdaFactor 12k ステップのもの。

positive: 1girl, blue hair, cat ears, parted bangs, white dress shirt, looking at viewer, wariza, sitting
negative: low quality, ugly, horror, blurry, retro, ukiyo-e, bad anatomy
一番左が素のSDXL base 0.9

positive: high quality photography of a pvc figure of a girl wearing leather jacket leaning against brick wall under bridge between buildings on the street, black bob cut, upper body focus, looking at viewer, depth of field
negative: low quality, ugly, horror, blurry, retro, ukiyo-e, bad anatomy
AdamW の方がステップ数少ないが、綺麗に見える。ただ、AdamWのときは微妙にデータセットのキャプションを変更した (pvc figure をキャプションに追加した) のでそのせいもありそうだ。
なお、 このプロンプトで pvc figure を抜くと普通の実写写真になってしまう
SDXLの学習中のサンプル画像が謎にクオリティ低い問題が修正されたらしい
イラスト600枚くらい(かなりスタイルがバラバラ)で調整
comfig.toml
pretrained_model_name_or_path = "/workspace/models/sd_xl_base_0.9.safetensors"
output_dir = "/workspace/output_1"
# hyperparameters
lr_scheduler = "cosine"
# lr_scheduler_num_cycles = 5
lr_warmup_steps = 100
max_token_length = 225
max_train_epochs = 10
# optimizer_args = ["weight_decay=0.01", "decouple=True", "use_bias_correction=True"]
optimizer_type = "AdamW"
seed = 3407
cache_latents = true
cache_latents_to_disk = true
gradient_checkpointing = true
# min_snr_gamma = 5
lowram = false
mixed_precision = "bf16"
xformers = true
save_every_n_epochs = 1
# save_every_n_steps = 1000
save_last_n_epochs = 5
# save_last_n_steps = 5000
# lora
learning_rate = 1e-5
# unet_lr = 5e-6
network_train_unet_only = true
network_alpha = 1
network_args = ["conv_dim=8", "conv_alpha=1"]
network_dim = 8
network_module = "networks.lora"
# network_weights = ""
persistent_data_loader_workers = true
prior_loss_weight = 1.0
# XL
# cache_text_encoder_outputs = true
# logging
log_prefix = "sdxl_09_anime_stylish_1-"
log_tracker_name = "sdxl_09_anime_stylish_1"
log_with = "wandb"
logging_dir = "/workspace/logs"
# sample
# sample_every_n_steps = 1000
sample_every_n_epochs = 1
sample_prompts = "/workspace/sample_stylish.toml"
sample_sampler = "euler_a"
# dataset
dataset_config = "/workspace/dataset_stylish.toml"
debug_dataset = false
Convレイヤーも学習する C3Lier を使ってみた。
学習率は AdamW で 1e-5 の cosine、100ステップの warmup。
なにがいけないのか、2エポック目 (260ステップくらい) で右の画像のようになってしまった...

追記: 上の画像はなぜか強度6.0で適用していたの崩壊していたが、普通に強度1.0で試したら変な崩壊はしてなかった... (それでもなぜか劣化してるけど...)
近い画風の画像1500枚くらいで10エポック回した
左からベース、7エポック、10エポック
設定
pretrained_model_name_or_path = "/workspace/models/sd_xl_base_0.9.safetensors"
output_dir = "/workspace/output_5"
# hyperparameters
lr_scheduler = "constant_with_warmup"
# lr_scheduler_num_cycles = 5
lr_warmup_steps = 100
max_token_length = 225
max_train_epochs = 10
# optimizer_args = ["weight_decay=0.01", "decouple=True", "use_bias_correction=True"]
optimizer_type = "AdamW"
max_grad_norm = 1.0
# optimizer_args = ["scale_parameter=False", "relative_step=False", "warmup_init=False"]
# optimizer_type = "AdaFactor"
seed = 3407
cache_latents = true
cache_latents_to_disk = true
gradient_checkpointing = true
# min_snr_gamma = 5
lowram = false
mixed_precision = "bf16"
xformers = true
save_every_n_epochs = 1
# save_every_n_steps = 1000
save_last_n_epochs = 5
# save_last_n_steps = 5000
# lora
learning_rate = 1e-5
# unet_lr = 5e-6
network_train_unet_only = true
network_alpha = 1
network_args = ["conv_dim=8", "conv_alpha=1"]
network_dim = 8
network_module = "networks.lora"
# network_weights = ""
persistent_data_loader_workers = true
prior_loss_weight = 1.0
# XL
# cache_text_encoder_outputs = true
# logging
log_prefix = "sdxl_09_anime_moderns_1-"
log_tracker_name = "sdxl_09_anime_moderns_1"
log_with = "wandb"
logging_dir = "/workspace/logs"
# sample
# sample_every_n_steps = 1000
sample_every_n_epochs = 1
sample_prompts = "/workspace/sample.toml"
sample_sampler = "euler_a"
# dataset
dataset_config = "/workspace/dataset.toml"
debug_dataset = false
[general]
caption_extension = '.txt'
enable_bucket = true
shuffle_caption = true
caption_dropout_rate = 0.1
# caption_tag_dropout_rate = 0.6
# color_aug = true
flip_aug = true
[[datasets]]
batch_size = 5
max_bucket_reso = 1728 # same as sdxl
resolution = 1024
[[datasets.subsets]] # 600
image_dir = '/workspace/moderns/modern_3'
num_repeats = 1
[[datasets.subsets]] # 650
image_dir = '/workspace/moderns/modern_4'
num_repeats = 1
[[datasets.subsets]] # 130
image_dir = '/workspace/moderns/modern_5'
num_repeats = 1
[prompt]
sample_steps = 20
scale = 7
height = 768
negative_prompt = "low quality, blurry, ugly, horror, retro, 1990s, 2000s, ukiyo-e, pixar, disney"
width = 640
[[prompt.subset]]
prompt = "1girl, aqua eyes, baseball cap, blonde hair, closed mouth, earrings, green background, hat, hoop earrings, jewelry, looking at viewer, shirt, short hair, simple background, solo, upper body, yellow shirt"
seed = 12345
[[prompt.subset]]
prompt = "1girl, looking at viewer"
seed = 55555
[[prompt.subset]]
prompt = "1girl, leaning forward, school uniform, looking at viewer, highres, absurdres"
seed = 999
ベース、強度1.0、強度1.25
