Stable Diffusion Web UI で LoRA したい (上手くいかなかった方法)
注意
機械学習やStable Diffusionにあまり詳しくない人が書いています。
間違っていることがある可能性が非常に高いので気をつけてください。
LoRA
要はいい感じの速度と低VRAMでいい感じに追加学習できるらしい。
機械学習わからんし論文も読んでないのでわからん。
注意
Microsoft も LoRA というものを公開していますが、全然別物なので混同しないように気をつてください。
以下を使う
Stable Diffusion WebUI
Dreambooth Extension
Extensionは Web UI の GUI でインストールできる。
私の環境
- GPU: NVIDIA GeForce RTX 3070 Ti (VRAM 8GB)
- Windows 11
- Python 3.9.15 (だが、これは使わない)
- conda: 22.11.1
❯ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_Mar__8_18:36:24_Pacific_Standard_Time_2022
Cuda compilation tools, release 11.6, V11.6.124
Build cuda_11.6.r11.6/compiler.31057947_0
だが、最初は CUDA Toolkit 11.3 を利用していたがためにいろいろとエラーに苦しまされた。
CUDA Toolkit は 11.6 にするべきである。それより低いと PyTorch の対応などがずれて動かなくなる。
11.6 のダウンロードリンク↓
Conda で env を作って汚染防止
SDWebUI の仕様や Conda をよくわかってないのですが、汚染が怖いので Conda で新しく環境を作り、そっちで動かすようにします
仮想環境の作成はどこのディレクトリでもよいです。
conda create -n sdwebui python=3.10.6
sdwebui という名前で仮想環境を作り、 Python 3.10.6 をインストールします。Python のバージョンは重要で、他のバージョンだと動く保証が無いので、3.10.6 に揃えることを推奨します。
上のコマンドを実行すると [y]/n とか聞かれるのでエンターしていろいろインストールします。
完了したら以下のコマンドで仮想環境に入ります。
conda activate sdwebui
仮想環境から抜けるには以下のコマンドを使います
conda deactivate
一応 PyTorch を手動で入れる
不要の可能性もあるのですが、心配なので一応入れておきます。
PyTorch のサイトにアクセスして、下にスクロールするとインストールコマンドがあります。
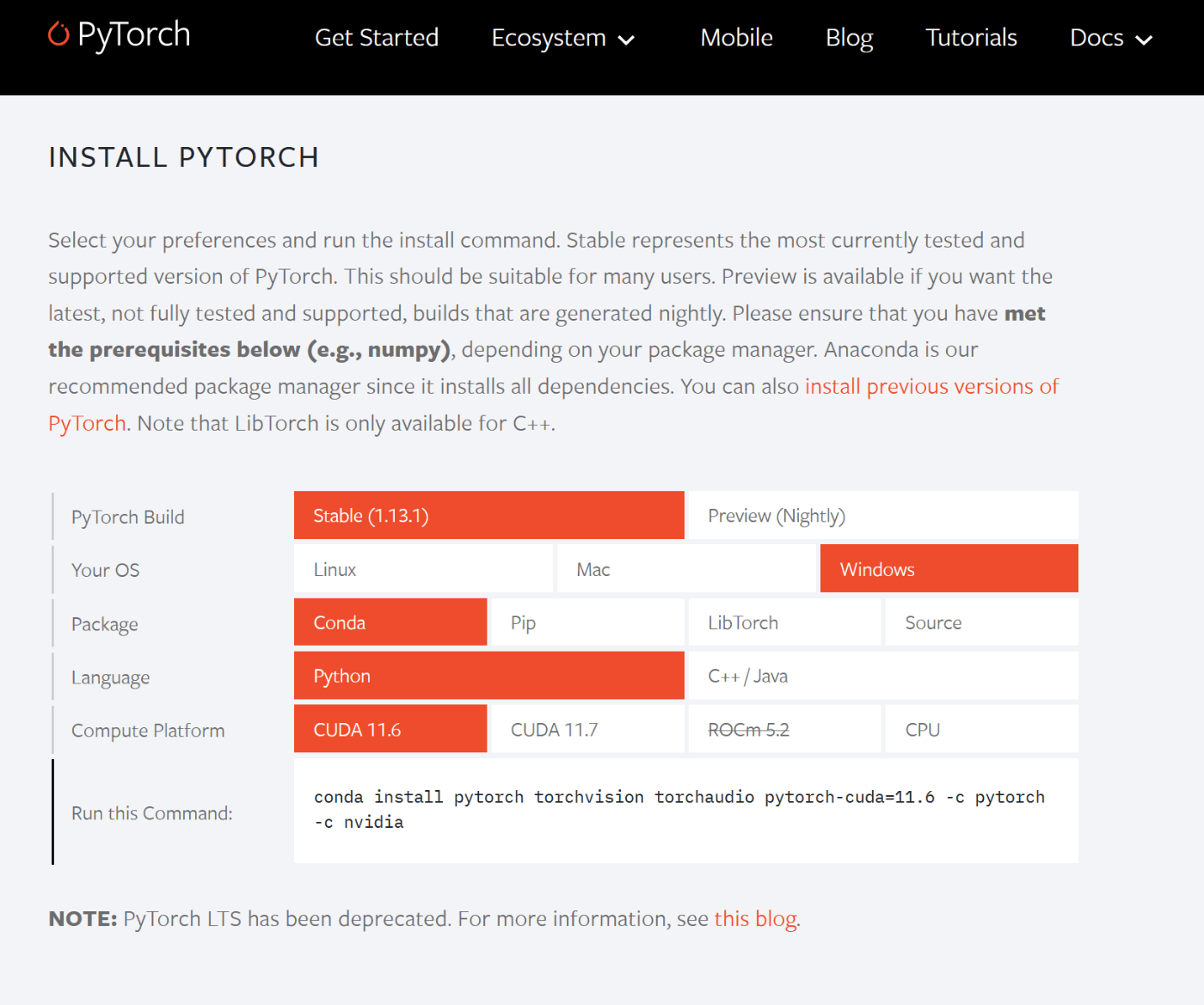
上から、Stable、Windows、Conda、Python、CUDA 11.6 が選ばれていることを確認します。
すると、インストールコマンドは以下のようになっているはずなので、
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
全部コピーして、sdwebui の環境で実行します。
ここでResolving...とか表示されて永遠に終わらない場合
おそらくCUDA Toolkit のバージョンが間違っています。
nvcc --version を実行して
❯ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_Mar__8_18:36:24_Pacific_Standard_Time_2022
Cuda compilation tools, release 11.6, V11.6.124
Build cuda_11.6.r11.6/compiler.31057947_0
のように最後に cuda_11.6.r11.6 となっていることを確認してください。
もし、ちゃんと 11.6 になっているのに永遠に終わらない場合は一度仮想環境を抜けて入り直すと治ることがあります。PC の再起動も試して、それでっも永遠に終わらない場合は Conda のバージョンが古い可能性があります。
Conda の base 環境で以下のコマンドを実行します
conda update -n base -c defaults conda
これで conda のバージョンが上がります。
同様にインストールするか聞かれるのでエンターし、しばらく待ちます。
xformers を有効にして起動する
./webui-user.bat を以下のように変更します。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers
set STABLE_DIFFUSION_COMMIT_HASH="c12d960d1ee4f9134c2516862ef991ec52d3f59e"
set ATTN_PRECISION=fp16
call webui.bat
COMMANDLINE_ARGS に --xformers を指定します。 --api や --host を使っている場合は一応一時的に抜くとよいです。拡張機能のインストールでコケることになります。
xformers をまだインストールしていませんが、心配する必要はありません。
なんと xformers がインストールされていない場合、 webui 側で自動でインストールしてくれるので、これを利用します。
STABLE_DIFFUSION_COMMIT_HASH は Dreambooth 拡張機能が最新版の WebUI に追いついていないため、少し古いバージョンで指定する必要があります。
この c12d960d1ee4f9134c2516862ef991ec52d3f59e は Stable Diffusion Web UI で、SDv2.0 系を動かすときに設定されるものですが、Dreambooth 拡張機能がちょうど動いたのでこれを使います。
参考↓
ATTN_PRECISION に fp16 を設定しています。これは、Dreambooth するときの省メモリ用の設定です。VRAM が 8GB の場合は設定する必要があります。
起動する前に
今までに一度でも起動したことがある場合は、venv をリセットする前に venv ディレクトリを削除してください。stable-diffusion-web-ui 直下にあります。
これは xformers を有効にするためなので、二回目以降は必要ありません。また、既に xformers が有効ならする必要はないと思いますが、心配なら削除するといいと思います。
起動
./webui-user.bat を実行します。venv ディレクトリを削除した後はインストール工程が入るため、しばらく時間がかかります。
運が良ければエラーなく完了し、http://localhost:7860 にアクセスするといつもどおりに使えるようになります。
謎のエラーが発生する場合は、おそらくは CUDA のバージョンがあっていないです。xformers が非常に厄介で CUDA や Python のバージョンがあっていないと死にます。バージョンを見直してみるか、エラー文でググったり issue を漁るとよいです。
学習素材の事前処理
学習に使う画像は既に集めている前提とします。既にやっていたら飛ばしていいです。
ここでは、512x512にクロップする必要はありません。
Train タブを開き、Preprocess images を選択します。
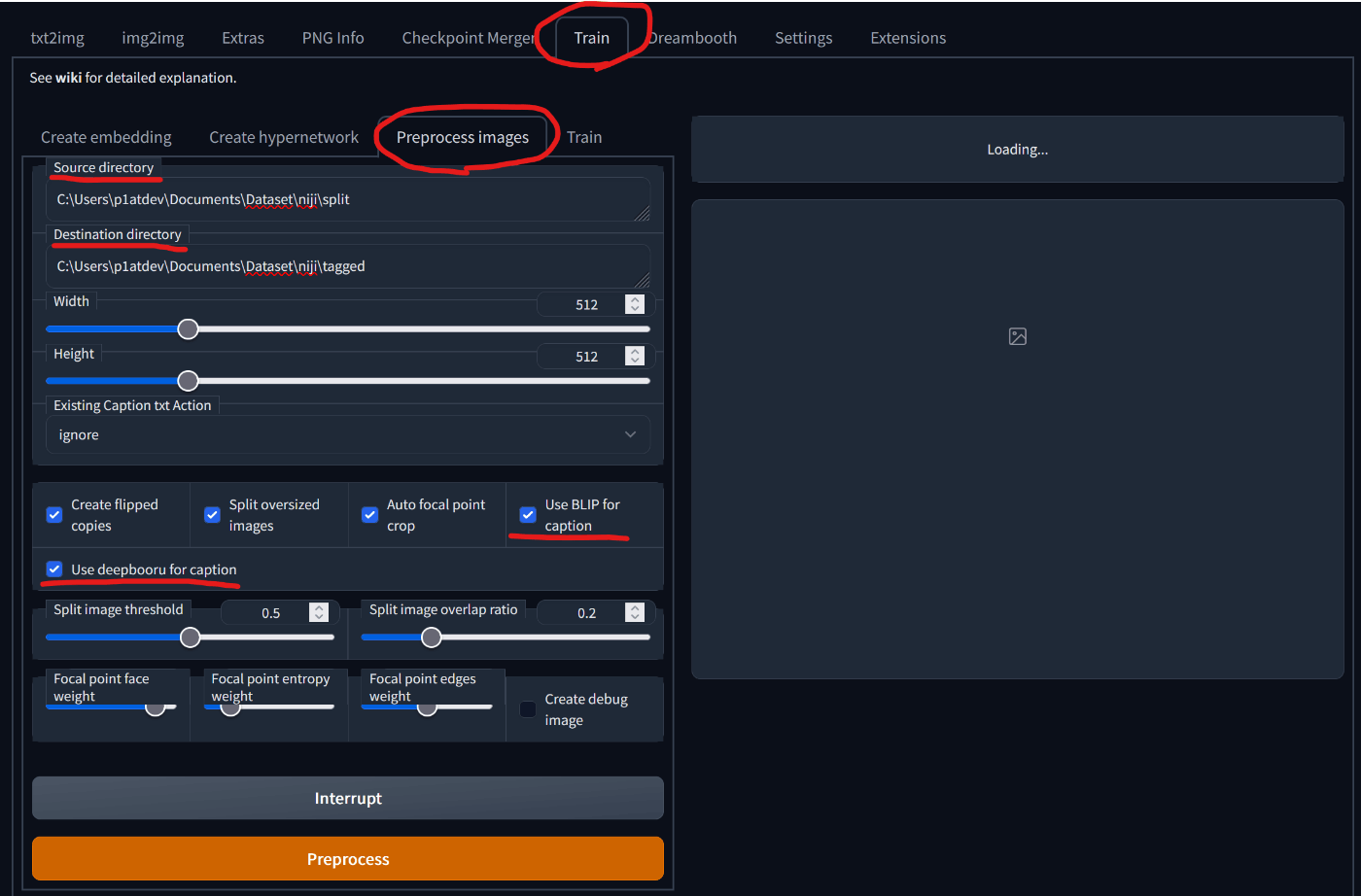
赤線で示しているところを中心に説明します。
- Source Directory: 処理前の画像が入ったディレクトリのパスを入れます
- Destination Directory: タグ付け、クロップが完了した画像が入るディレクトリのパスを入れます
- Width/Height: クロップするサイズですが、512x512でそのままいじらないほうがいいと思います
- Existing Caption txt Action: 既にキャプションを用意している場合にどのように使うかです。用意していない場合は ignore にします。用意している場合は copy (そのまま使う)、prepend (先頭につける)、 append (後ろにつける) を選びます。
- Create flipped copies: 左右反転させた画像を生成します。左右が特に重要ではない画像を学習させる場合は有効にすることで学習画像を水増しできます。ぼっちちゃんのように左右が重要なキャラクターを覚えさせる場合は、有効にしないようにすることをおすすめします。
- Split oversized copies: わからないです。サイズを超えた場合に二分割するらしい?
- Auto focal point crop: 縦長や横中の画像のときに、人物の顔が綺麗に映るようにクロップ位置を自動で調整します。有効にすると時間がかかりますが、有効にしたほうがいい気がします。
- Use BLIP for caption: キャプション付けに BLIP を使用します。BLIP をつかうと、
a girl with a ponytail in a black and white drawing styleのように、文章でキャプションがつきます。 - Use deepdanbooru for caption: キャプション付けに Deepdanbooru を使います。
1girl, bangs, braid, eyebrows_visible_through_hairのような Danbooru タグでのキャプションが付きます。
BLIP と deepdanbooru は同時に使用可能ですが、BLIP のキャプションが先につくため、a girl with a ponytail in a black and white drawing style, 1girl, bangs, braid, eyebrows_visible_through_hair のようになります。
キャプションをちょっと修正する
danbooruタグに _ が含まれるのが邪魔なのでスペースに変換します。
雑に Python コードを書いたので、各自の環境に合わせて使ってください
from pathlib import Path
# ファイル名を変更するフォルダーのパスを指定する
folder_path = Path("./tagged").resolve()
# txt ファイルを取得する
txt_files = list(folder_path.glob("*.txt"))
# 対象外
exclude = ["^_^", "@_@", "+_+"]
# ファイルの中身を書き換える
for txt_file in txt_files:
print(txt_file.name)
txt_content = ""
with open(txt_file, "r") as f:
txt_content = f.read()
# _ を スペースに入れ替える
# ただし、exclude に含まれるものは除く
for i in range(0, len(exclude)):
txt_content = txt_content.replace(exclude[i], f"$skip-{i}")
# 入れ替え
txt_content = txt_content.replace("_", " ")
# 戻す
for i in range(0, len(exclude)):
txt_content = txt_content.replace(f"$skip-{i}", exclude[i])
# 保存
with open(txt_file, "w") as f:
f.write(txt_content)
print("Done.")
これを実行すると、キャプションから _ がなくなります。
Dreambooth モデルを作成する
Dreambooth のタブを開き、Create Model のところを見ます。
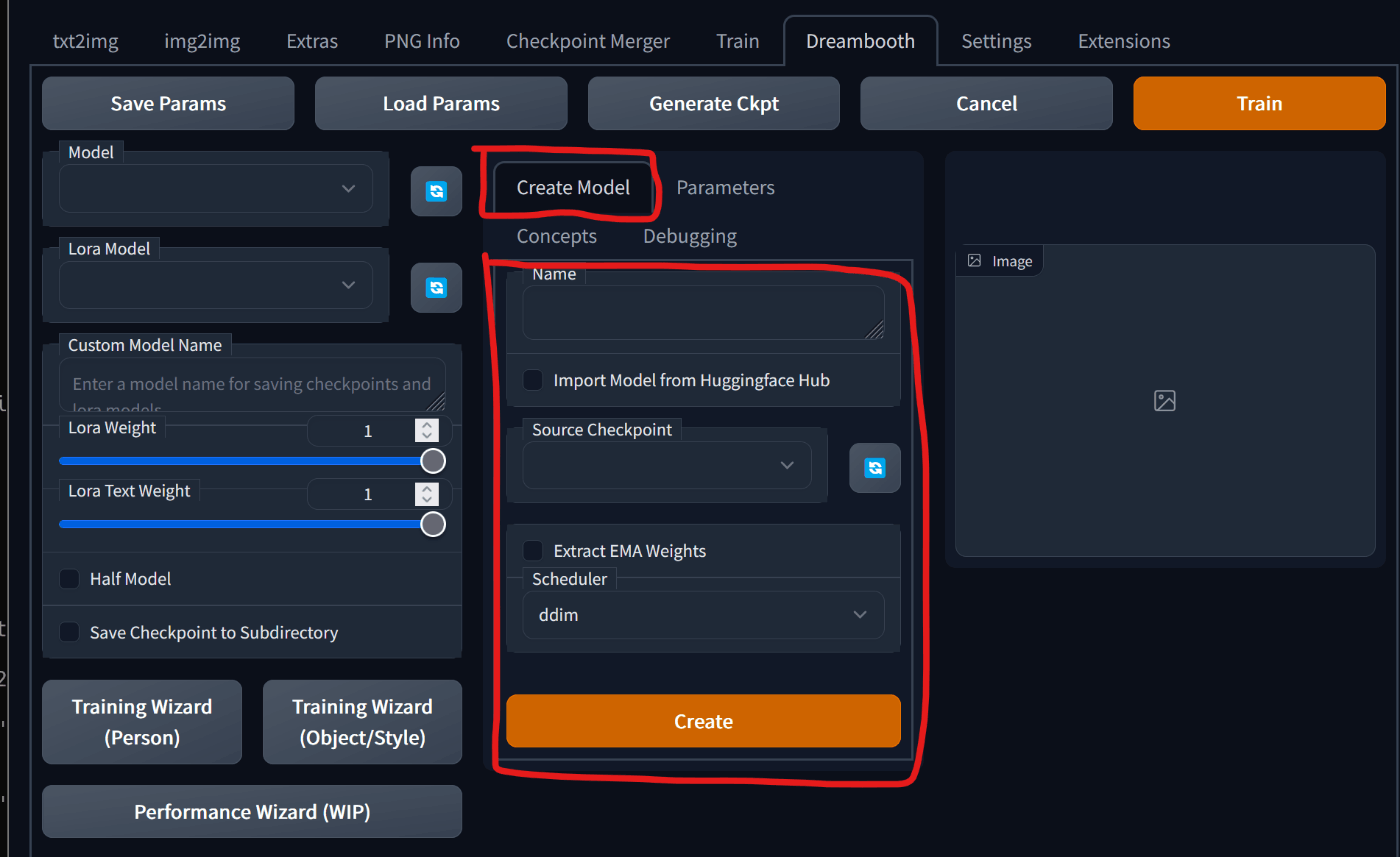
必要なパラメーターを入力します。
- Name: これから作るモデルの名前
- Import Model from Huggingface Hub: Huggingface からモデルをダウンロードする場合はチェックをいれます。この記事では使わないです。
- Source Checkpoint: ベースとなる ckpt ファイル。いつもの生成で使ってる ckpt ファイルの置き場所と同じところを参照している。
- Extract EMAWeights: 不明
- Schedular: 実写なら ddim、イラストなら euler-ancestral いいかもしれない?
入力して、Create をクリックすれば学習用のモデルが作成されます。