Matryoshka Diffusion Models を見てみる
Apple から公開された拡散モデルの論文
従来の拡散モデルでは、ピクセル空間でのカスケード方式 (Imagen や DeepFloyd IF など)であったり、Auto Encoder を通した潜在空間を利用する方式 (LDM や Stable Diffusion など) が多い。今回の手法 Matryoshka Diffusion (MDM) では、複数の解像度の入力を共同でノイズ除去する拡散プロセスを行い、小規模な入力の特徴とパラメータが大規模な入力の特徴とパラメータ内にネストされる NestedUNet アーキテクチャを使用することで、エンドツーエンドで高解像度での画像生成と動画の生成もできる。

論文から引用。左上のストームトルーパーのマトリョーシカは、MDMで生成されたそれぞれ64x64、128x128、256x256、512x512、1024x1024 の画像。コーヒーの画像は、MDMで生成された64x64の16フレーム動画。ほかは1024x1024の画像。
(個人的な感想)
DALL-E2 やら Stable Diffusion やらが出てから 1 年ちょいで、ようやく Apple が動いたかという感じで個人的に衝撃がある。CoreML 対応だったり mobilevit くらいしかやってなかったので正直画像生成には手を出さないのかなと思っていた。そこで、めっちゃいい感じのアーキテクチャの提案ときて激アツ。しかも、Google の Imagen の構成とも比較して良い成績を出しててちゃんとすごい。DeepFloyd IF のあの 3 段階は本当に使いづらくて厄介だったので、よりシンプルに扱えて良い性能を出してくる Apple、さすがという感じ。マジで、あの 3 段階どうやってファインチューンするんだよ。Apple の主なプラットフォームが iPhone とか iPad が多いからなのか、mobilevit とか軽量だったり効率的なものをやっていたことの延長という感じだろうか。Apple らしさが伺える。
ほぼ動きがなかった Apple が動いたと思ったら、12M とかいう超少ないデータセットでもいい感じの画像生成できて効率的なアーキテクチャの提案という展開、アツい。
従来の拡散モデル
画像、音声、動画、テキストにおいて、非常に人気になっている
- 高解像度にスケーリングすることは課題
高解像度に焦点をおいたアーキテクチャもあるが...
- カスケードするモデルや潜在空間を利用するモデルに勝てない
複数の段階を挟む系のアーキテクチャ
- DALL-E2、Imagen、eDiffi などは、低解像度で生成する部分と超解像する部分に分け、それぞれ個別に学習することで計算量を減らしたりしている
- LDM では低解像度で学習するが、個別にトレーニングされた高解像度オートエンコーダーに依存している
- どちらも複数の段階が発生して学習も推論も複雑になったり、ハイパーパラメーターの調整が大変
そこで、エンドツーエンドの高解像度生成 (カスケード予定の低解像度だったり、Latent で生成されないで、画像の状態で生成される) ができる MDM を提案する。
(個人的な感想)
DeepFloyd IF は Imagen のアーキテクチャらしいけど、たしかにステージごとにいちいちモデルアンロードしないといけなくてめんどかったり、ファインチューンするとなると、どこをどう学習すりゃいいのかわからんし、複数に分かれると確かに面倒だなと思った。実際 SDXL は美的要素の改善のために refiner が用意されてるけど、あれをファインチューンして使っている人はいるのだろうか...
というのを考えると、一発で高解像度の画像が出てくるというのはかなりシンプルになってよいなと思う。計算量がどうなるか気になるところ...
MDM と NestedUNet
今回提案されている MDM と、そこで使われている NestedUNet というものについて。
これらは、GAN のマルチスケール学習からインスピレーションを得ており、高解像度生成の一部として低解像度の拡散プロセスを含めることで、
- 高解像度入力ノイズ除去の収束速度を大幅に向上させる多重解像度損失
- 低解像度のトレーニングから開始する効率的な漸進的トレーニングスケジュール
が可能になるらしい。
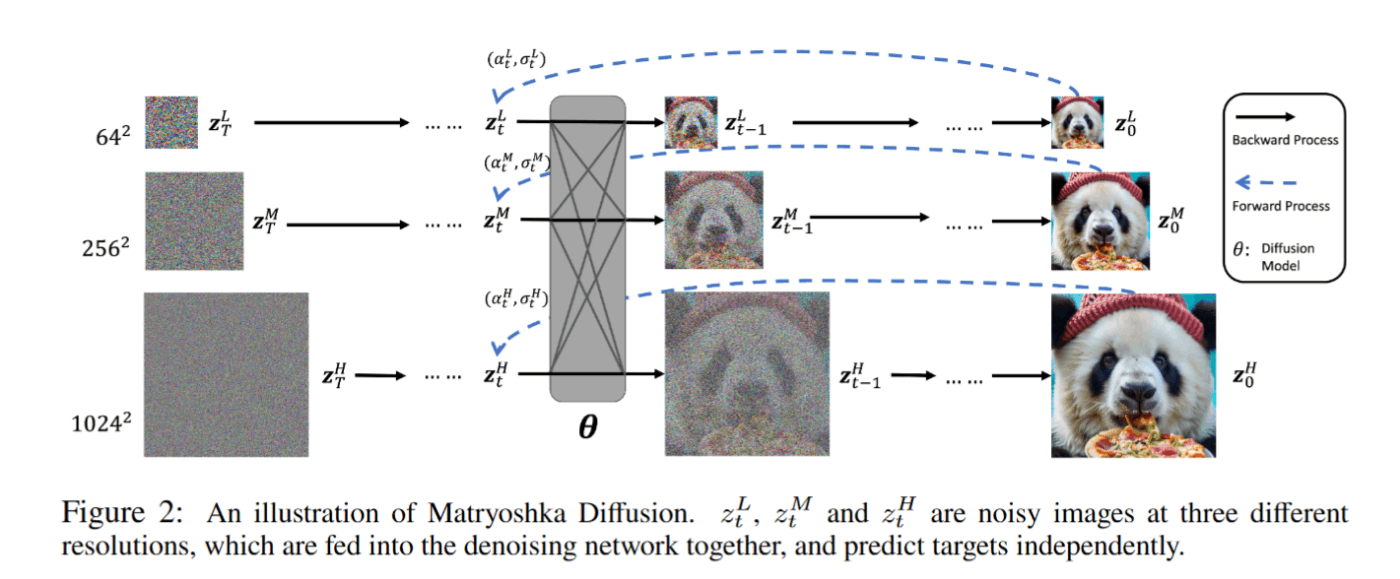
論文より、MDM の図。ノイズがついた3種類の解像度の画像は、同時にノイズ除去ネットワークに入力されて、それぞれ個別にターゲットを予測する。

論文より、MDMで使われている NestedUNet アーキテクチャの図。SDXL のアーキテクチャを元に、低解像度での計算量が多くなるように設計しているらしい。
実験
データセット
この論文では、再現を容易にするために、一般に公開されているデータセット を利用している。
画像データセットには、
動画データセットには、
- WebVid-10M (256x256x16フレーム)
を利用した。
CC12M を選んだことは、従来の Imagen や DALL-E2 のような非常に大規模かつ非公開のデータセットを利用した研究とは大きく異なっている。
また、CC12M は、短期間で高クオリティな text-to-image モデルを学習するのに十分の量であることがわかった。(A100 GPU 8 台を 4 ノード利用すると、 2~5 日あればモデルを構築して、モデルを評価するのに十分らしい)
実装の詳細
NestedUNet の最下層では 64x64 の解像度になっている。SDXL を参考に、大部分の Self Attention レイヤーはより低レイヤー (16x16) の機能に移しており、最終的な内部 UNet のパラメータ数は 450M。モデルの高解像度部分は、パラメータ数の増加を最小限に抑えて、NestedUNet の前のレイヤーの上に簡単に接続できる。テキストエンコーダーには学習済みの FLAN-T5 XL (ちなみに Imagen は T5-XXL) を利用しており、このパラメーターは更新しない。さらに、テキスト表現の上に 2 つの学習可能な Self Attention レイヤーを適用して、テキストと画像のアライメントを強化している。
ImageNet の学習には A100 GPU を 8 台、CC12M と Web-Vid-10M には A100 GPU を 32 台使用した。
評価
モデルの評価には FID スコアと CLIP スコアを利用している。
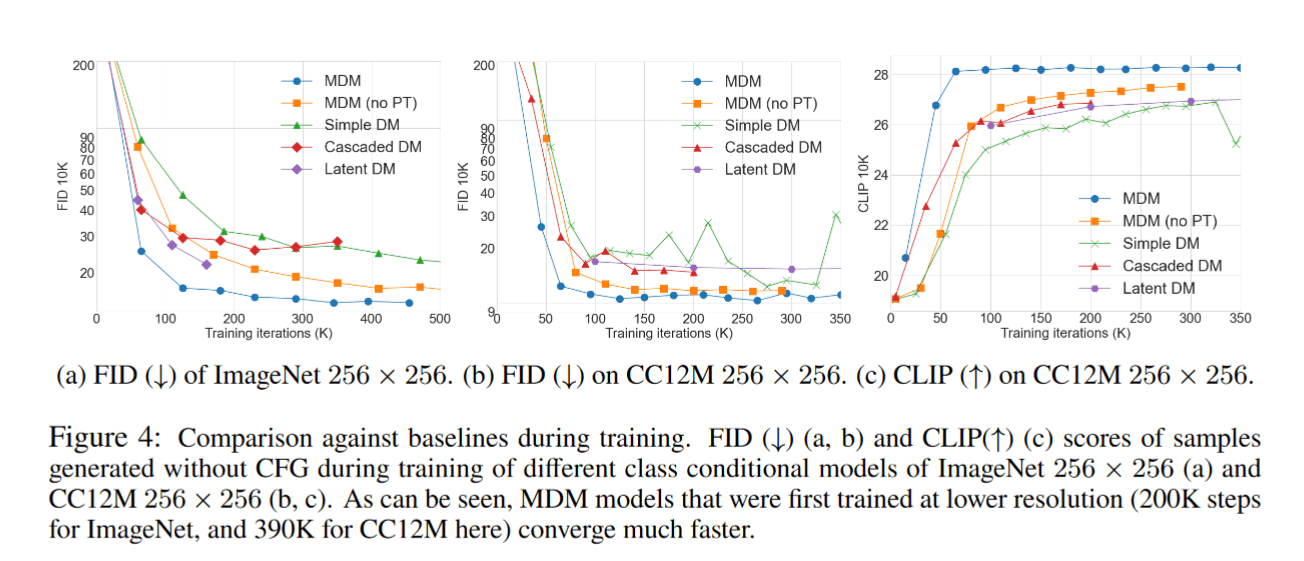
FID スコアは低いほうが画像が高品質。CLIP スコアは高いほうがテキストプロンプトにより従っている。
- MDM: 64x64 の低解像度で事前に学習してから高解像度で学習したもの
- MDM (no PreTraining): 事前の学習を行わずに、直接複数解像度で学習したもの
- Simple DM: 高解像度の入力を使う標準的な UNet アーキテクチャの拡散モデルを学習したもの。Simple Diffusion という研究に基づいているっぽい。
- Cascaded DM: Imagen と同じアーキテクチャで学習したもの。
- Latent DM: VAE は既存のものを利用して、LDM のアーキテクチャで学習したもの。
Simple DM と MDM を比較すると、MDM のほうが収束が速く、さらに最終的な性能も良いことがわかる。これから、複数解像度のロスを利用した複数解像度の拡散プロセスの複雑さは無視できる程度であり、効率的に収束する効果があると思われる。
また、Cascaded DM は MDM (事前学習ありなし両方とも) と比べて非常に性能が悪い。これについて、MDM では複数解像度の生成において多くのパラメーターを共有するので、Cascaded DM の方がパラメータ数が多い上に、Cascaded DM は推論ステップも 2 倍ほどになるので、非常に注目すべきことである。Cascaded DM の性能が劣っているのは、64x64 (ステージ1)が積極的にトレーニングされていないことが主な原因であると仮説を立てることができる。これにより、条件付け入力に関する学習と推論の間に大きな乖離が生じている。
LDM と MDM を比較しても、MDM は良い性能を示している。LDM は入力が小さく効率的であるが、MDM の方がよりシンプルな学習と推論のパイプラインを備えている。
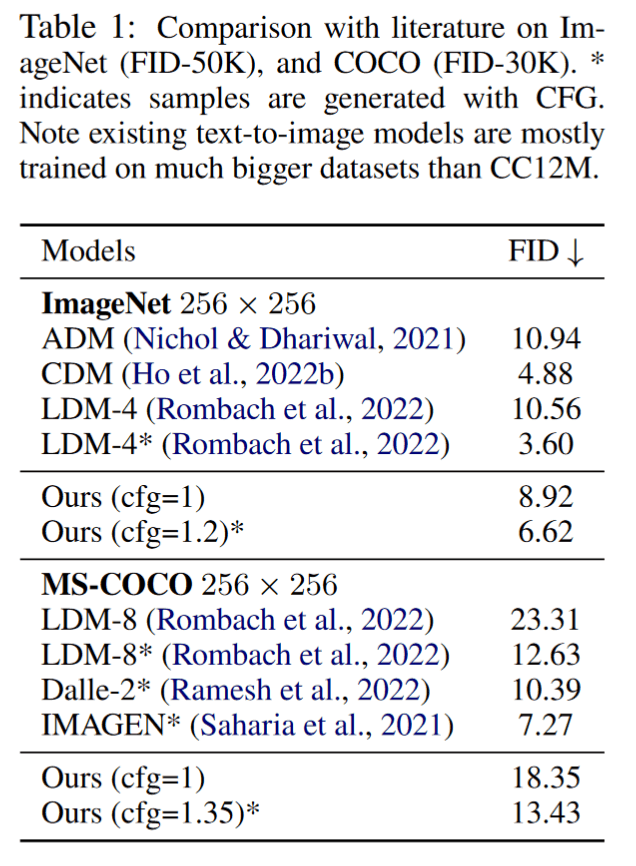
文献で引用してるようなモデルとの比較。ここでは LDM や DALL-E2、 Imagen に負けているが、注意すべきはこれらのモデルは CC12M よりも格段に大規模なデータセットを使って学習されているということである。
参考