Safetensors のヘッダーを読む
Safetensors とは
Safetensors は HuggingFace が開発している、主にテンソルを安全・高速に読み書きできるファイルフォーマットと、それを扱うためのライブラリです。
提供されている Python ライブラリでは、PyTorch や Tensorflow などとの互換性があるほか、pickle 形式のような任意のコードを実行する機能がなく比較的安全なため、最近の深層学習系のモデルはこの形式で配布されることが多くなりました。
構造
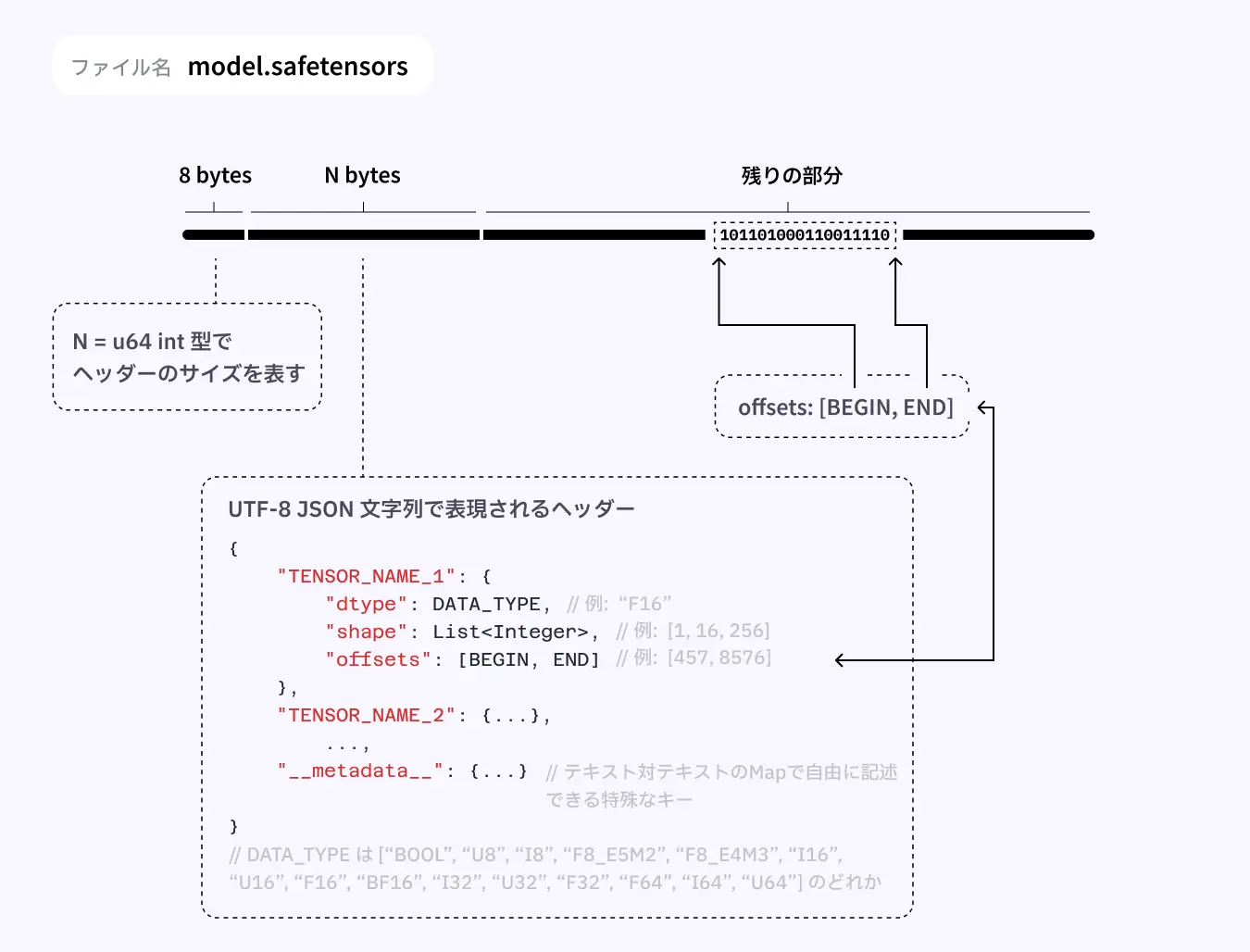
Safetensorsのファイル構造の説明 [1]
Safetensors はシンプルな構造をしています。大きく分けて ヘッダーサイズ領域 (8 bytes)、ヘッダー領域 (N bytes)、バッファ領域 (残りの部分) に分かれています (それぞれの領域の公式名称が不明なので、この記事では勝手に呼びやすい名前で呼んでいます)。ヘッダーとバッファ領域が別れているため、ヘッダー情報を利用して、全体を読み込まずに特定の部分だけを読み込むこともできるようになっています。
今回は Safetensors のヘッダー領域について読む方法を紹介します。
ヘッダーサイズ領域
最初の 8バイト (uint64) は、ヘッダーのサイズを表します。
ヘッダー領域
ヘッダー領域は UTF-8 の JSON となっているため、多くのプログラミング言語で簡単に読み込むことができます。
{
"__metadata__": {
"format": "pt"
},
"model.embed_tokens.weight": {
"dtype": "F32",
"shape": [49152, 576],
"data_offsets": [0, 113246208]
},
"model.layers.0.input_layernorm.weight": {
"dtype": "F32",
"shape": [576],
"data_offsets": [113246208, 113248512]
},
"model.layers.0.mlp.down_proj.weight": {
"dtype": "F32",
"shape": [576, 1536],
"data_offsets": [113248512, 116787456]
},
...
}
解説画像にあったように、基本的に
"レイヤー名": {
"dtype": "データ型",
"shape": [次元1, 次元2, ...],
"data_offsets": [データの開始位置, データの終了位置]
}
が繰り返されています。
また、特殊なキーとしてオプショナルでメタデータを保存できる __metadata__ フィールドがあり、特に取り決めはないので自由に情報を入れることはできますが、 文字列: 文字列 のキーバリューペアにしなければならない という制約があります。ヘッダー自体は JSON 形式なのですが、__metadata__ では文字列型のみが使用可能となっている形なので、少し注意が必要です。
DoS攻撃を防ぐために、制約としてヘッダーの最大サイズは 100MB となっています [2]。最大サイズを超える場合、HeaderTooLarge エラーとなって読み込めなくなります。
dtype: データ型
データ型を表す文字列。2024/10/2時点で以下が利用可能です。[3]
-
BOOL: Boolean 型 -
U8: 符号なし 8 ビット整数 -
I8: 符号付き 8 ビット整数 -
F8_E5M2: 8 ビット浮動小数点数 (5ビットの指数部、2ビットの仮数部) -
F8_E4M3: 8 ビット浮動小数点数 (4ビットの指数部、3ビットの仮数部) -
I16: 符号付き 16 ビット整数 -
U16: 符号なし 16 ビット整数 -
F16: 16 ビット浮動小数点数 -
BF16: 16 ビット浮動小数点数 (Brain floating point) -
I32: 符号付き 32 ビット整数 -
U32: 符号なし 32 ビット整数 -
F32: 32 ビット浮動小数点数 -
F64: 64 ビット浮動小数点数 -
I64: 符号付き 64 ビット整数 -
U64: 符号なし 64 ビット整数
ただし、テンソルを扱うライブラリによっては一部のデータ型はサポートされていないことがあります。[4]
shape: テンソルの形状
テンソルの形状を表す整数の配列。
スカラー(0次元)の場合は空の配列 [] で指定します
data_offsets: データの開始位置と終了位置
[開始, 終了] でテンソルデータの開始位置と終了位置を表す整数の配列。
絶対位置ではなく、バッファ領域の先頭からの相対位置 で指定します。そのため多くの場合、最初のレイヤーのデータの開始位置は 0 になります。
メタデータに関する仕様
__metadata__ フィールドに書き込む内容は自由なのですが、これを使ってモデルの情報を記録するための取り決めが StabilityAI によって提案されています。
モデルのアーキテクチャやモデル名、Base64形式のサムネイル画像を指定できたりします。一応テキスト生成モデル向けの項目もありますが、主に画像生成モデルを対象とした規格になっています。ここではあまり深掘りしません。
Python でローカルのヘッダーを読む
Python で Safetensors ファイルのヘッダーを取得してみます。例に使う Safetensors ファイルとして、HuggingFaceTB/SmolLM-135M のモデルファイルを使っています。
import json
path = "./model.safetensors" # safetensors ファイルがあるパス
with open(path, "rb") as f:
# 8バイト読み込む
buffer = f.read(8)
# リトルエンディアンでバイト列を整数に変換
header_size = int.from_bytes(buffer, byteorder="little")
print(f"header_size: {header_size}")
with open(path, "rb") as f:
# ヘッダー部分を読み込む
f.seek(8)
buffer = f.read(header_size)
# ヘッダー部分を JSON としてデコード
header = json.loads(buffer.decode("utf-8"))
print(header)
❯ python ./main.py
header_size: 30368
{'__metadata__': {'format': 'pt'}, 'model.embed_tokens.weight': {'dtype': 'F32', 'shape': [49152, 576], 'data_offsets': [0, 113246208]}, ...
ヘッダーのサイズは 30368 でした。ヘッダーの出力は途中で省略していますが、メタデータとモデルの各レイヤーの情報が含まれていることがわかります。
Rust でローカルのヘッダーを読む
Python と同様です。JSONのパースは面倒だったので文字列として読んでいます。
use std::{fs::File, io::Read};
fn main() {
let path = "./model.safetensors"; // safetensors ファイルがあるパス
let mut file = File::open(path).unwrap();
let mut buffer = vec![0u8; 8]; // 8 バイトのバッファを用意
file.read_exact(&mut buffer).unwrap(); // ファイルから 8 バイト読み込む
// リトルエンディアンでバッファを u64 に変換
let header_size = u64::from_le_bytes(buffer.try_into().unwrap());
println!("header_size: {}", header_size);
// ヘッダーのサイズ分だけ読み込む
let mut header_buffer = vec![0u8; header_size as usize];
file.read_exact(&mut header_buffer).unwrap();
let header = String::from_utf8(header_buffer).unwrap(); // テキストに変換
println!("{}", header);
}
❯ cargo run -q
header_size: 30368
{"__metadata__":{"format":"pt"},"model.embed_tokens.weight":{"dtype":"F32","shape":[49152,576],"data_offsets":[0,113246208]}, ...
TypeScript でリモートのヘッダーを読む
Safetensors が非常にシンプルな構造をしているおかげで、ファイル全体を読み込まずともヘッダー部分だけを取得してレイヤーの情報を取得することができます。 この特徴を利用して、HTTP の Range リクエストヘッダーと組み合わせることで、インターネット上の Safetensors ファイルの情報を完全なファイルをダウンロードすることなく得ることができます。Range ヘッダーについては MDN ドキュメントを参照してください。
以下に TypeScript を利用して、ファイル全体をダウンロードすることなくヘッダーを取得する例を示します。
// HuggingFace のモデルのダウンロード URL
const fileUrl = "https://huggingface.co/HuggingFaceTB/SmolLM-135M/resolve/main/model.safetensors"
const headerSizeRes = await fetch(fileUrl,
{
method: "GET",
headers: {
// https://developer.mozilla.org/ja/docs/Web/HTTP/Headers/Range
"Range": "bytes=0-7" // 8 バイト取得
}
}
)
const headerSize = await headerSizeRes.arrayBuffer().then((buffer) => {
// https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Global_Objects/DataView/getBigUint64
const view = new DataView(buffer)
// データの先頭0バイト目から8バイトをリトルエンディアンで読み取り、bigint型に変換
// https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Global_Objects/DataView/getBigUint64
return view.getBigUint64(0, true)
})
console.log(`headerSize: ${headerSize}`)
const headerRes = await fetch(
fileUrl,
{
method: "GET",
headers: {
// ヘッダーサイズに 7n (bigint) を足してヘッダー部分を取得
"Range": `bytes=8-${7n + headerSize}`
}
}
)
const json = await headerRes.json()
console.log(json)
❯ bun run ./main.ts | head -n 10
headerSize: 30368
{
__metadata__: {
format: "pt",
},
"model.embed_tokens.weight": {
dtype: "F32",
shape: [ 49152, 576 ],
data_offsets: [ 0, 113246208 ],
},
...
今回は Bun を使いましたが、標準機能しか使っていないため他のランタイム上でも動作するはずです。
Range ヘッダーを使う方法は公式ドキュメントでも紹介されており、実際に HuggingFace のモデルページの総パラメータ数やレイヤー情報の表示機能に使われています。(ネットワークタブから監視すると Range ヘッダーをつけてリクエストしているのが見れます)
おまけ
ほとんど自分用ですが、Safetensors のメタデータを読んだり消したりできるCLIツールを作ったので、興味があれば使ってみてください。
Discussion