はじめに
PKSHA Technology のソフトウェアエンジニアの新冨です。
私のチームでは社内問い合わせ管理ソフトウェアである PKSHA AI ヘルプデスクを開発しています。PKSHA AI ヘルプデスクに関する詳しい説明は以下の記事を参考にしてください。
先日、問い合わせ者用の Teams 風なチャット画面を ChatGPT 風なデザインに刷新しました。このプロジェクトで私は主担当エンジニアとして、Cursor と MCP(Model Context Protocol)を中心に複数の AI ツールを統合し、開発サイクル全体を AI フローとして再構築しました。「AI にコードを書かせる」だけでなく、タスク起票から仕様参照、フィードバック反映、QA、PR 作成までを一連の循環として AI に組み込むと、開発の速度と品質が変わりました。
この記事を通して読者が、Cursor と MCP を軸に AI を組み合わせて高速な実務開発サイクルの構築方法を知り、AI が強かった領域/弱かった領域を両方扱い、読者が現場で再現できる判断基準を持ってもらえると幸いです。
このプロジェクトにおける登場人物と役割
- SWE: ソフトウェアエンジニア。プロダクトのコード編集権を持ち、リリース作業を担当する
- QAE: 品質保証エンジニア。機能要件を満たしているか、非機能要件の実装が妥当か調べてフィードバックする
- Designer: 新しい画面のあるべき姿を Figma で作成する。実装された画面と Figma に差分があれば指摘しフィードバックする
- PdM: プロダクトオーナー。顧客にプロダクトを出して良いか最終判断し、修正が必要な場合はフィードバックする
Cursor × MCPで構築した開発フローと得られた効果
試行錯誤の結果、以下のフローの効率が最も良かったです。
開発フローの全体像
Cursor と MCP で目指したのは、開発工程を個別に AI 化することではなく、開発サイクル全体を AI を核に循環させることです。
図として表現すると以下の通りで、Cursor は自動的に MCP を利用して各種リソースから情報を取得し、その入出力の監視・コードのアウトプット制御として SWE が関与する形になります。
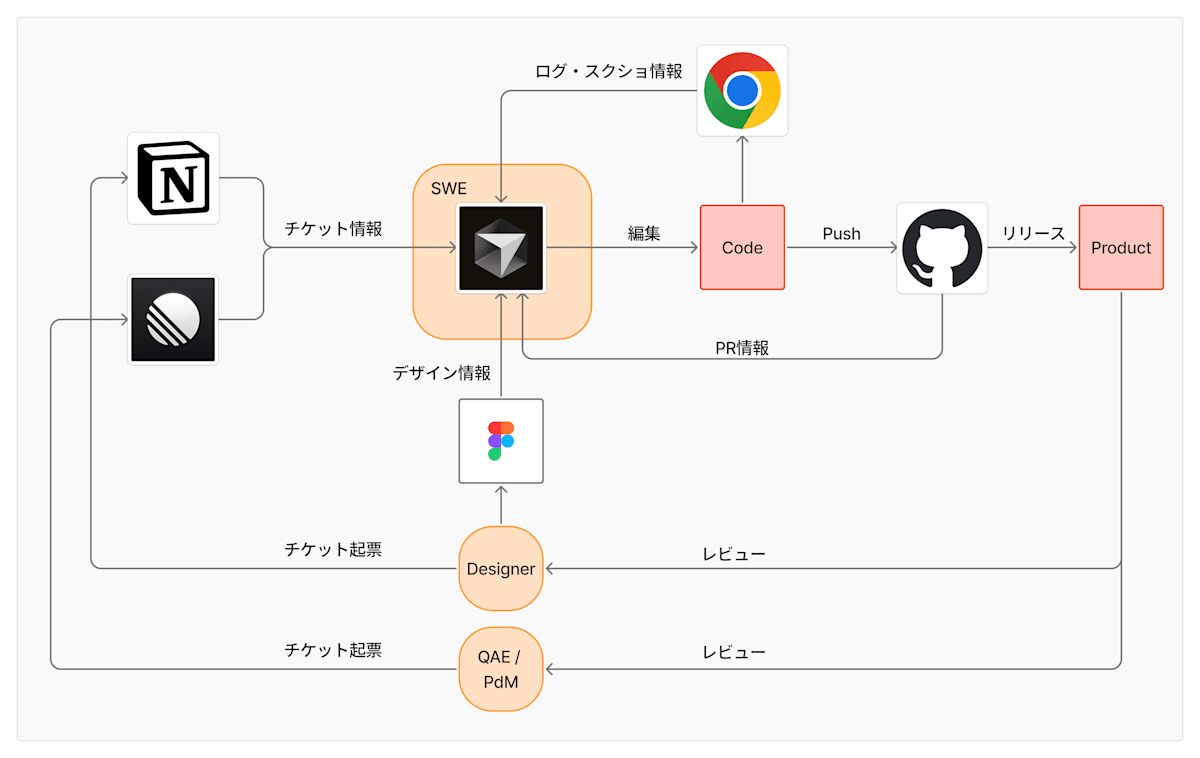
Cursorを中心とした開発フローの全体像
開発フローは以下の通りです。
- 仕様・フィードバック・デザインがチケットとして整備される
- QAE のバグ/改善指摘は Linear
- Designer の修正指示や議論の集約は Notion
- UI の一次情報は Figma
- Cursor が MCP 経由で一次情報を直接参照する
- Linear / Notion / Figma / GitHub / Chrome DevTools の情報を MCP 経由で引き出す
- Cursor が実装・修正まで行う(半自動)
- チケット内容をほぼそのまま入力プロンプトとして使い、修正案からコード変更まで実施する
- Slash Command で PR / lint / test / review を回す
- PR 概要作成、CI 修正、レビュー補助などをテンプレ化して半自動化する
- QA・デザイン FB を再び入力として反復する
- 修正依頼 → AI 修正 → 確認 → PR というループが高速に回る
ポイントは「SWE 以外のメンバーの指示やデータを AI が直接読み取り、コードに落とす」ことが前提になっている点です。
AI導入の肝・なぜこの開発フローが速く回ったか
この開発フローが成立し、速度と品質の両方に効いた理由は 3 点あります。
- SWE の役割シフト:「解釈して実装する人」から「AI 出力の品質保証と難所に集中する人」へ変わりました。従来は QAE や Designer のフィードバック、仕様、デザインの意図を SWE が一度解釈してコードへ翻訳していた。AI がその翻訳から実装まで担うようになると、SWE は出力の正しさや体験の質を担保することに集中できた。
- MCP による一次情報への直アクセス:開発が速いのは「モデルが賢いから」ではなく、AI が Linear / Notion / Figma / GitHub / DevTools といった一次データに直アクセスできる構造を作ったから。調査→理解→実装の間に挟まっていた転記や要約のコストが消え、ループが短くなった。
- Slash Command による半自動化:PR 概要作成、lint / test 修正、レビュー観点出しなど、毎回実施するがコード化しづらい作業をテンプレ化した。Slash Command に落とすことで、人の判断だけ残しつつ反復作業を高速化できた。
得られた効果
この開発フローにより、開発のボトルネックが移動しました。
- フィードバック→修正の反復が高速化:チケットをそのままプロンプトとして使うため、SWE 側の翻訳作業がほぼ消える。「起票されたものが翌朝には直っている」レベルの速度をフローとして実現できた。起票の粒度が的確だったことも大きい。
- PR 前工程の品質と速度が安定:diff・背景・仕様を AI が吸い上げ、PR 概要をテンプレで生成することで、説明漏れや品質のムラが減った。
- SWE の時間配分が"書く→判断する"に変化:AI が実装を引き受ける分、SWE は「期待通り動くか」「UI 体験として気持ち悪くないか」「影響範囲や設計上の筋が通っているか」といった点へ集中できるようになった。
AI前提の開発フローを作るための要素技術
それではここから、このフローを実現するための具体的な要素技術について説明します。
AI に実装まで走らせるには、入力(タスク・仕様・背景)の設計が本体です。ここを曖昧にすると AI の出力が不安定になります。
Linearの書き方と紐付けかた
チケット起票時には、背景と完了条件を必ず書き、「どうなったら OK か」をできるだけ具体化します。1 issue が大きくなりすぎると AI が扱える粒度を超えてしまうため、1 つの issue で扱うのは 1 つの機能や修正に絞ることが重要です。Linear が単なるタスク管理ではなく、AI が読む"仕様の一部"になるイメージです。
もともと私たちのチームの開発フローでは、branch 名または PR タイトルに Linear ID を含めることで、1 issue = 1 PR を基本単位として運用しています。CI が PR から Linear ID を抽出し、自動的に Linear チケットと PR を紐づける仕組みを整えることで、Linear の in review や merged へのステータス自動遷移も実現できます。この構造だと AI が PR の目的や背景を追いやすく、PR 生成やレビュー、QA 修正時のコンテキストがブレなくなります。
CursorにMCPを統合する
MCP の価値は、AI の性能自体よりも「AI が参照できる情報の範囲と鮮度を広げること」にあります。今回 Cursor に接続した MCP は以下の通りです。
- GitHub MCP server: PR / diff / リポジトリ情報を AI が直接取得する
- Linear MCP: チケット背景 / 完了条件をそのままプロンプトとして扱う
- Notion MCP: デザイナーからの修正指示や議論ログを参照する
- Figma MCP(Dev Mode): デザインやトークンなど一次情報を取得する
- Chrome DevTools MCP: console.log や network など実行時情報を AI に渡す
Linear MCP や Notion MCP は認証が必要ですが、各公式ドキュメントの手順通りに進めれば問題なくセットアップできます。
今回は使っていませんが個人的に便利だと思っている MCP サーバーは以下の 2 つです。
上記の MCP server をまとめて利用するための mcp.json は以下の通りです。
{
"mcpServers": {
"github": {
"command": "docker",
"args": [
"run", "-i", "--rm",
"-e", "GITHUB_TOOLSETS",
"-e", "GITHUB_PERSONAL_ACCESS_TOKEN",
"ghcr.io/github/github-mcp-server"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "<your_pat>",
"GITHUB_TOOLSETS": "repos,users,pull_requests,code_security" // GitHubへのwrite系の権限はあえて外してある
}
},
"linear": {
"type": "http",
"url": "https://mcp.linear.app/sse"
},
"notion": {
"type": "http",
"url": "https://mcp.notion.com/mcp"
},
"Figma Dev Mode MCP": {
"type": "sse",
"url": "http://127.0.0.1:3845/sse"
},
"chrome-devtools": {
"command": "npx chrome-devtools-mcp@0.9.0", // npm package攻撃を考慮してバージョン直指定で利用する
"env": {},
"args": []
}
}
}
これらが Cursor から直接読めるだけで、調査・理解・実装の間のコピペ作業が格段に減ります。
Cursor から GitHub へのアクセス方法はいくつかあります。その中でも私はあえて gh コマンドではなく GitHub MCP を利用しています。具体的な理由としては以下の通りです。
- 大きな PR を gh で取ると省略が起き、結局 API 経由が必要になる
- gh はローカルユーザー権限と直結し、AI 操作時のガードレール設計がしづらい
- MCP は「AI が安全に使う前提」の I/O になっているため制御しやすい
- GitHub MCP では GitHub への write 系の権限をあえて外し利用している
実務で回したSlash Command / プロンプト
「言語化できるけど定型コード化しづらい作業」を Slash Command として利用し、作業を半自動化しました。
PR概要生成(/createpr)
このコマンドは、GitHub MCP で PR diff を取得し、PR / branch の Linear ID から Linear MCP で背景を取得します。 さらに概要に関連 Notion があれば Notion MCP で仕様情報を取得した上で、それらをまとめて PR 概要のテンプレを生成します。 PR の"説明品質を毎回担保できる"ことが大きなメリットです。 私たちの開発チームでは Linear や Notion に背景情報を詳細に書くのを推奨しています。 そのため GitHub PR にも毎回それらの内容を転記するのが面倒でした。 それをこのコマンドで半自動化できました。
使い方はシンプルで、/createpr https://github.com/<org>/<reponame>/pull/<no> を実行すると概要が作成されます。
実装スレッドでそのまま /createpr コマンドを使ったり、GitHub MCP / gh command で draft PR を直接作成して概要まで書かせることも可能です。 しかし、実装スレッドのまま実行すると試行錯誤の内容を反映してしまうため、新規スレッドで/createprを実行する方が望ましいです。 また、draft PR 作成後に含まれるファイルが本当に必要な差分かを目視でチェックしたいので、手間ではありますがあえて手動で draft PR を作成しています。
実際の Cursor Slash Command /createpr は以下のプロンプトで作成されています。
.cursor/commands/createpr.mdで保存して利用します。
GitHub MCPを利用して与えられたGitHub Pull Requestを取得してください。
そのファイル差分を元にPull Requestの概要欄に書く説明を作成して欲しいです。
Pull Request名に紐づいたbranch nameに識別子が入っている場合、それはLinearのチケットを指しています。
Linear MCPを利用して、関連するLinearチケットの情報を取得して概要欄の説明を書いてください
またNotion URLがあれば、Notion MCPを利用して関連情報を取得して欲しいです。
Human Readableな文章を心がけてください。
概要欄には以下の項目を書いて欲しいです。
- 概要: このPRで実現すること
- 背景: なぜこのPRが必要か
- 変更内容: このPRで何を実装したかざっくり。詳細を書きたい場合はdetails, summary blockを使う
装飾
- Markdownの強調は使わない
- 作成した文章はコードブロックに記述(コピーしやすいため)
- 項目名はh2(##)から始め、改行して本文を書く
- GitHubのURLはそのまま埋め込む(GitHub viewerが装飾してくれる)
- GitHub以外のURLはタイトルを表示してURLを埋め込む
- 人間に読みやすく、編集しやすいよう適度に改行と箇条書きを使う
lint 修正 (/lint)
CI 定義を参照しながらローカルの lint / test コマンド結果を解釈して修正します。「CI を通すための定型修正」は AI に任せやすい領域でした。実際の Cursor Slash Command /lint は以下のプロンプトで作成されています。 .cursor/commands/lint.mdで保存して利用します。
CIを通すようにlint, formatエラーを修正して欲しいです
## client
以下のコマンドを実行して、error, warningが返ってきたら修正して欲しいです
CIは次のファイルで定義されています
`<repo>/.github/workflows/check.yml`
cd <repo> && docker compose exec -it client bash -c <cmd>
## server
infra層でのテスト例
cd <repo> && docker compose exec -it server bash -c 'cd ./infra && go test'
lint
cd <repo> && docker compose exec -it server bash -c 'golangci-lint'
review対応 (/review)
シニア SWE 視点でレビューし、機能 / 非機能・影響範囲・規約適合をチェックします。 必要なら Notion / Linear を参照して背景を理解させます。レビューの"見落としパターン"を減らす補助線として機能します。 この辺はまだ改善の余地があると思っています。
シニアソフトウェアエンジニアの視点でレビューしてください
必要に応じてNotionやLinearを参照して背景を理解してください
考慮ポイント
- 機能要件・非機能要件
- この機能を実装することで、影響を受ける関連実装がないか
- 既存リポジトリのコーディング規則に沿っているか(エラーハンドリング、ファイル名、メソッド名、ディレクトリ構造)
バグ対応ループ
上記の MCP Tool や Slash Command を Cursor に用意することで次のような体験を実現できました。
- QAE / Designer が起票したチケット ID を Cursor に渡すと、AI が Linear や Notion などの MCP を利用してチケット内容を取得し、修正案→コード修正まで実施する
- SWE が動作確認して GitHub へ push し、起票されたチケット ID とコードから半自動で PR 概要を作成し、レビュー依頼を行う
- レビューが完了しマージされると自動で dev 環境用の build が回り、dev 環境に最新の状態が反映される
- そして再度 QAE / Designer にレビュー依頼を行う
これにより Pull Request / コードの品質を維持したまま、QAE / Designer のフィードバックを迅速に反映できました。
実運用で分かったAIの適性と限界
Cursor / MCP の組み合わせはやはり銀の弾丸ではなく、当然弱みも一定ありました。実際に運用して見えてきた強みと弱みをまとめます。
高速化に成功した領域
最も効果を発揮したのは、lint / format / test のようなルールベース修正や、単純な UI 崩れ、状態の軽微な不具合といった自動修正系のタスクです。正解が比較的明確で差分として閉じている問題では、AI が安定して修正を提供できました。
情報取得の面でも大きな効果がありました。Linear / Notion / Figma / GitHub / DevTools を横断して参照することで、バグの原因特定や修正方針の確立が格段に速くなります。 AI が一次情報を読める状態にしておけば、「調査→理解→実装」が一気通貫で進むのが強みです。
さらに、PR 概要の自動生成、差分要約、レビュー観点の提示といった PR 生成支援も有効でした。書く負担を軽くするだけでなく、背景の取りこぼしや怒涛の PR 量でも品質を落とさない点が効きました。
人間の判断が必要だった領域
一方で、ビジュアル比較には明確な限界がありました。Figma / DevTools から画像を渡しても、余白のズレ、アニメーションの不自然さ、ピクセル単位での差分などは拾いきれないことがあります。AI はまだ"目が弱い"前提の開発フロー設計が必要です。
CSS があまり得意ではなかったため、フロントエンドの細かな修正やアニメーションの指示を的確に出すことができませんでした。
例えば、次のような指示の違いがありました。
- 私の指示:「ハンバーガーメニューを押したらサイドメニューがにゅっと出る感じのアニメーションを入れて欲しい」
- 的確な指示:「ハンバーガーメニューをタップしたら、サイドメニューをオーバーレイとして画面の左端から 0.2s でフェードインして欲しい」
私は Cursor の AI をそのまま活用して実装をしていたため、そのままプロダクトの品質低下に直結しました。 今回のプロジェクトにおいては別の SWE に頼ったりデザイナーからのフィードバックが必要でした。 やはり AI をうまく使いこなすためには、その領域の細かな指示を的確に出せる知識、人間側の言語化能力が重要だと痛感しました。
また互換性や暗黙前提の担保も課題です。 旧画面の暗黙仕様、既存コードの副作用、状態遷移の細部といった点は、AI だけに任せると理解がズレやすい領域です。 "何を守らないといけないか"を先に人間が構造化して渡す必要があります。
開発フロー運用で得た教訓
今回は、QAE や Designer が背景・完了条件・修正ポイントをチケットに丁寧に書いてくれたことが大きかったです。それをそのまま AI のプロンプトとして使うことで修正ループが高速化され、このワークフローが成果を最大化しました。
まさに、入力設計こそが成功の鍵です。
一方で、AI が実装を高速化するほど、SWE の価値は変化していきます。 設計・アーキテクチャの検討、暗黙仕様の顕在化、UI / UX の違和感の言語化、AI が出した変更の品質保証といった領域へ集中できるようになります。 "曖昧な要求を具体化する仕事"は今後も人間側に残ると強く実感しました。
今後の改善と拡張
今回のプロジェクトでいくつかの課題と改善の余地が見えてきました。
最も顕著だったのは、AI のビジュアル比較の限界です。
Cursor Sonnet-4.5 / Figma MCP / Chrome DevTools MCP の組み合わせでは、AI が Figma の画像と DevTools で取得した画面の画像を見比べても適切に差を指摘できませんでした。
修正も中途半端なものになりました。
一方で Figma の CSS を直接貼り付けると正しく修正できたことから、現状のツール群の組み合わせだけでは AI の「目の弱さ」を補いきれていないことが分かりました。
この課題への改善策として、まず Storybook MCP server の導入を検討しています。 コンポーネント単位で画像を取得できる環境を作ることで、ピクセル単位での差分を機械的に取得し、AI への入力として渡せるようになります。 加えて、Gemini 3.0 のような visual prompt 性能が高いモデルを局所的に使うことで、ビジュアル比較の精度を向上できる余地があります。
もう 1 つの改善方向は、Designer のフィードバックをコードや PR の段階で直接受けられる仕組みの構築です。 特に CSS が書ける Designer であれば、PR 中に直接指示や修正を完了できる可能性があります。 コードとレビュワーの距離が遠くなるほどフィードバックの反映速度は遅くなるため、Storybook や Claude Code、Devin の活用でこの距離を縮めることが現実的になってきています。
まとめ
Cursor と MCP を組み合わせることで、チケット / 仕様 / デザイン / PR / 実行ログといった一次情報が Cursor に集まります。 AI を核に「入力 → 実装 / 修正 → PR → QA / FB → 再入力」という循環を作ることができました。
このサイクルが速く回るための条件はシンプルです。
入力が構造化されていること(Linear / Notion テンプレ)、一次情報に AI が直アクセスできること(MCP 統合)、そして反復作業が Slash Command で半自動化されていることです。
読者の現場で最初に試すなら、Linear か Notion のどちらかを MCP で Cursor に繋ぎ、「1 チケット → 1PR → AI 修正」の小さな循環を回してみることをお勧めします。
AI は魔法ではありませんが、開発フローを"AI が回りやすい形"に再設計すると速度と品質の両方が変わります。
プロダクトレベルのフロントエンド開発をするのが初めてでしたが、かなり楽しい経験になりました。 社内では Cursor、Claude Code、Codex、GitHub Copilot、Devin、Antigravity、Kiro など使える環境が整っています。 それらを活用してより素早いプロダクト開発フローを確立していきたいと考えています。 あくまで現時点では最終的なハンドルは SWE が握る運用方針ですが、将来的には AI への権限委譲の範囲をさらに拡大できるポテンシャルを感じています。
今回の開発フローはフロントエンド開発のプロジェクトに特化したものです。 サーバーサイド開発など他の領域にはそのまま適用できない部分もあります。 しかし、ここで得られた知見を他分野に転移し、より汎用的なワークフロー構築を目指していきたいです。

Discussion