なぜこの記事を書くのか?
DataplexのデータリネージAPIを有効にすることで、BigQueryのテーブル間の依存関係を簡単に可視化することが出来る。
特定のテーブルを参照しているテーブルが少ないうちはGUIを使うだけで問題ないが、よく参照されるテーブルの依存関係を把握する際に辛い部分もある。
こういった作業を容易にするために、APIから情報を取得することで簡単にデータを取れるようにした。
このAPIから情報を取得、一覧として表示するコードが誰かの役に立つことを祈って記事にした。
どんな感じの出力が得られるのか?
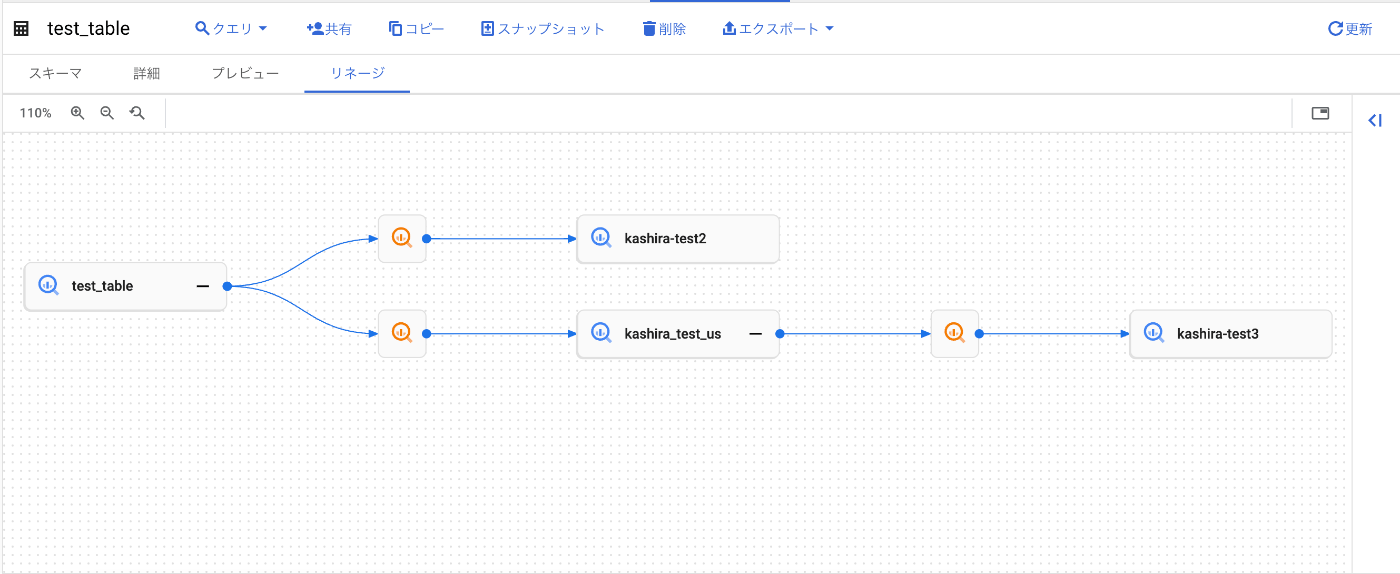
GUIでの可視化
スクリプトの出力結果
pythonスクリプトのアウトプット
--関連するテーブル一覧--
bigquery:project_id.dataset_id.kashira-test2
bigquery:project_id.dataset_id.kashira-test3
bigquery:project_id.dataset_id.kashira_test_us
--json形式の出力--
{"bigquery:project_id.dataset_id.kashira_test_us": {"bigquery:project_id.dataset_id.kashira-test3": null}, "bigquery:project_id.dataset_id.kashira-test2": null}
整形したjson
{
"bigquery:project_id.dataset_id.kashira_test_us": {
"bigquery:project_id.dataset_id.kashira-test3": null
},
"bigquery:project_id.dataset_id.kashira-test2": null
}
環境
- python
- python 3.8.10
- 利用パッケージ
- google-cloud-datacatalog-lineage = "^0.2.2"
事前準備
DataplexのデータリネージAPIの有効化、権限の追加をしておいてください。
またpythonのスクリプトを動かすためにローカル(macなど)でGCPのクレデンシャルをセットする必要があります。
gcloud auth login
コード
出来るだけ綺麗に書いたつもりですが、気になる所があれば指摘してください。
mainにテーブル名と、プロジェクト番号を指定する部分があるので、そこを各自で書き換えてから使ってください。
ロケーションはデフォルトでusなので、tokyoリージョンなどの場合には適宜ロケーションを変更してください。
sample.py
from typing import Dict
from google.cloud.datacatalog import lineage
from google.cloud.datacatalog.lineage_v1.services.lineage import pagers
import json
def _fetch_links(
project_number: str,
fully_qualified_name: str,
location: str = "us",
) -> pagers.SearchLinksPager:
"""FQDNから参照されている下流のテーブルを取得する。
Args:
project_number (int): GCPのプロジェクト番号
fully_qualified_name (str): FQDN. "bigquery:project_id.dataset_id.table_name"の形式で来ることを想定している
location (str, optional): location. Defaults to "us".
Returns:
pagers.SearchLinksPager: pagerオブジェクト。forで回せば上手いことやってくれるようにラップしてくれてある。
"""
if len(fully_qualified_name.split(".")) != 3:
raise RuntimeError(
"テーブル名の指定がおかしい。必ず`bigquery:project_id.dataset_id.table_name`で指定してください",
fully_qualified_name,
)
if fully_qualified_name.startswith("bigquery:") is not True:
raise RuntimeError(
"FQDNの指定がおかしい。必ず`bigquery:`から初めてください",
fully_qualified_name,
)
if not project_number.isdigit():
raise RuntimeError("projectの指定がおかしい。数字のみで指定してください", project_number)
source = lineage.EntityReference()
source.fully_qualified_name = fully_qualified_name
request = lineage.SearchLinksRequest()
request.source = source
request.parent = f"projects/{project_number}/locations/{location}"
lineage_client = lineage.LineageClient()
pager = lineage_client.search_links(request=request)
return pager
def _is_unnecessary_link(fully_qualified_name: str) -> bool:
"""機械的に作られる一時テーブルは除外する
ここは各自の環境でカスタマイズする
"""
# 処理しやすいように分割する
splited_fully_qualified_name = fully_qualified_name.split(".")
if len(splited_fully_qualified_name) != 3:
raise RuntimeError("FQDNの指定が異常", fully_qualified_name)
dataset_id = splited_fully_qualified_name[1]
# temp, tmpが含まれる場合は無視して良いとみなす
if "temp" in dataset_id:
return True
if "tmp" in dataset_id:
return True
return False
def _filter_links(
pager: pagers.SearchLinksPager,
) -> filter:
"""APIの検索から除外して良いlinkを省く
APIへの通信回数を減らすため、不要なlinkは再起的に検索しないようにする
"""
# _scriptから始まるデータセットなどの一時的なテーブルを除外して検索を早くする
unnecessary_dependency_filtered_pager = filter(
lambda link: not _is_unnecessary_link(
link.target.fully_qualified_name,
),
pager,
)
# Mergeクエリのようなsource = targetとなる依存関係を除外する
return filter(
lambda link: link.source != link.target,
unnecessary_dependency_filtered_pager,
)
def _fetch_link_as_json(
project_number: str,
source_fully_qualified_name: str,
upstream_fully_qualified_name: str = None,
) -> "Dict[str]":
"""DataCatalogのData Lineageからリンクしているテーブルをjson形式で取得する.
サンプル:
source_fully_qualified_name->A->B, A->C, B->C, B<->Dの依存関係があるとする.
この場合の返り値は、以下のようになる.
{
A: {
B: {
C: None,
D: None
},
C: None,
}
}
Args:
project_number (str): GCPのプロジェクト番号
source_fully_qualified_name (str): 依存関係を調べたいFQDN
upstream_fully_qualified_name (str, optional): 上流の依存関係. A->B,B->Aの依存関係があると無限ループに入るので、これの対策. Defaults to None.
Returns:
Dict[str]: linkをdict形式で表したもの
"""
pager = _fetch_links(
project_number=project_number,
fully_qualified_name=source_fully_qualified_name,
)
# APIの通信回数を減らすため、考慮しなくて良いlinkは除外する
filtered_links = _filter_links(pager=pager)
# 違う処理で同じ依存関係ケースがあるので、テーブルの重複を省く
distinct_filtered_fqdn = set(
link.target.fully_qualified_name for link in filtered_links
)
# これ以上依存関係がない場合には再帰が止まる
if len(distinct_filtered_fqdn) == 0:
return None
# 依存先が更に依存されている場合は再帰的に確認する
dependency = {}
for fqdn in distinct_filtered_fqdn:
print(
{
"source": source_fully_qualified_name,
"target": fqdn,
}
)
# A<->Bの依存関係がある場合は無限ループに入るので打ち切る
if upstream_fully_qualified_name == fqdn:
dependency[fqdn] = None
print("打ち切り")
continue
dependency[fqdn] = _fetch_link_as_json(
project_number=project_number,
source_fully_qualified_name=fqdn,
upstream_fully_qualified_name=source_fully_qualified_name,
)
return dependency
def _convert_to_list(link_dict: dict) -> list:
"""関連するテーブルが一覧で分かるようにlistに変換する"""
# dictのキーが関連するテーブルなので、dictのキーを全てlistに詰めて返す
# https://qiita.com/yamjun/items/e898b7bc8bfc4afdb445#comment-c41b3b557fcbd9332d61
def _get_all_keys(_dict: dict) -> list:
keys = list(_dict.keys())
for value in _dict.values():
if isinstance(value, dict):
keys.extend(_get_all_keys(value))
return keys
return _get_all_keys(link_dict)
if __name__ == "__main__":
# "{project_id}.{dataset_id}.{table_name}"の形式
target_table = "{table}" # 各自で入力してください
# 検索対象のプロジェクト
# 適当にいつも使っているプロジェクトを入れる。
# どのプロジェクトを指定しても同じ結果が返ってくる。
# 指定したプロジェクトにあるテーブルしか返らないということもない。
project_number = "{project_number}" # 各自で入れください
link_dict = _fetch_link_as_json(
project_number=project_number,
source_fully_qualified_name=f"bigquery:{target_table}", # FQDNの指定は`bigquery:project_id.dataset_id.table_name`
)
# dictのままだとドキュメントとして使いにくい部分があるので、listに変換する
table_list = _convert_to_list(link_dict)
# linkが重複している部分があるので、重複を排除
table_set = sorted(set(table_list))
print("--関連するテーブル一覧--")
for table in table_set:
print(table)
# エディタなどで整形しやすいようにjsonで出力
graph_json = json.dumps(link_dict)
print("--json形式の出力--")
print(graph_json)
参考
APIリファレンス
データリネージ情報モデル

Discussion