PDFファイルを渡したらmarkdown化したものをアウトプットしてくれるプログラムを作りたい!
業務でたくさんのPDFの内容をmarkdown化しなければならなくなったがなるべく楽をしたいので良い方法はないかと模索したところ、chatgptで全部いけそうだったので、ファイル名に渡したらmarkdownファイルをアウトプットしてくれるようなプロンプト x プログラムを作る。
サンプルPDFはこちら、京都市の児童手当に関する説明PDF。

いけそう、もう完成か?


あとはAPI経由でPDF送信できるようにすれば終わり!かと思いきやAPI経由ではPDFは送れないそうなので、ローカルでテキスト抽出->テキストAPI経由で送信->md化したものを受け取ってローカルに保存、という感じでやってみる。
PDFからテキストの抽出
zenn記事のこちらを参考にしながら...助かりすぎる...!!
TypeScriptでpdfからテキストを抽出する(PDF.js)
bunの導入
ランタイムにはbunを利用。
よくわからないけど、typescriptがそのまま動いて早いらしい...
curl -fsSL https://bun.sh/install | bash
source ~/.zshrc
テキスト抽出していく
PDF.jsの導入。
PDF.js
npm install --save pdfjs-dist
あ〜、bunだとbun addを使うのね。
bun add @types/node
参考にしたプログラムをちょっと修正したのが以下。
import * as fs from "fs";
import * as pdfjsLib from "pdfjs-dist";
async function extractTextFromPDF(): Promise<string> {
const pdfPath = "./childmoney.pdf";
const pdfData = new Uint8Array(fs.readFileSync(pdfPath));
const loadingTask = pdfjsLib.getDocument({ data: pdfData });
const pdf = await loadingTask.promise;
const maxPages = pdf.numPages;
let pdfText = "";
for (let pageNumber = 1; pageNumber <= maxPages; pageNumber++) {
const page = await pdf.getPage(pageNumber);
const content = await page.getTextContent({ includeMarkedContent: false });
const pageText = content.items.map((item) => ("str" in item ? item.str : "")).join("\n");
pdfText += pageText + "\n";
}
fs.writeFileSync("./output.txt", pdfText);
console.log(pdfText);
return pdfText;
}
extractTextFromPDF().catch((error) => {
console.error(error);
});
🔽 bun run pdfToMd.ts!!
ふむふむ良い感じ。

chatgptのAPIを叩く
chatgptのAPIを取得
とりあえずfetchでアクセス
こちらの記事を参考に。
(https://zenn.dev/erukiti/articles/ts-chatgpt-api)[TypeScriptを使ってChatGPT APIをアクセスしてみる]
import * as fs from 'fs';
async function convertTextToMarkDown(): Promise<void> {
const textFilePath = "./output.txt";
const text = await fs.readFileSync(textFilePath, "utf-8");
const url = "https://api.openai.com/v1/chat/completions";
const gptModel = "gpt-3.5-turbo";
const apiKey = process.env.OPENAI_API_KEY;
const messages = [{role: "user", content: "Please say hello."}];
const body = JSON.stringify({
model: gptModel,
messages
})
const res = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${apiKey}`,
},
body
})
const data = await res.json();
console.log(data);
}
convertTextToMarkDown().catch((error) => {
console.error(error);
});
🔽
うーんなんか上手くいかない。

API叩くように別に課金しないといけないらしい
OpenAI APIのエラー(openai.error.RateLimitError)について
課金額、tierでRPM, RPDとかが変わる。

Rate limitについて
あれ、設定したけど変わらん...
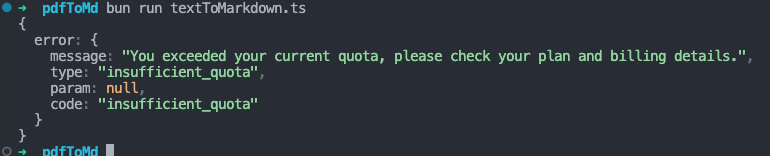
fetchで叩いたのがよくなかった?
ちゃんとopenaiのSDKを使ってリクエストしてみる。
OpenAIのSDKを使う
API reference
OpenAI Node API Library
以下で導入。
npm install openai@^4.0.0
サンプルコード。
import * as fs from 'fs';
import OpenAI from 'openai';
async function convertTextToMarkDown(): Promise<void> {
const textFilePath = "./output.txt";
const text = await fs.readFileSync(textFilePath, "utf-8");
const url = "https://api.openai.com/v1/chat/completions";
const model = "gpt-3.5-turbo";
const apiKey = process.env.OPENAI_API_KEY;
const messages = [{role: "user", content: "Please say hello."}];
const openai = new OpenAI({ apiKey });
const chatCompletion = await openai.chat.completions.create({
messages: [{role: "user", content: "Please say hello."}],
model,
});
console.log(chatCompletion.choices[0].message);
}
convertTextToMarkDown().catch((error) => {
console.error(error);
});
いけた〜!
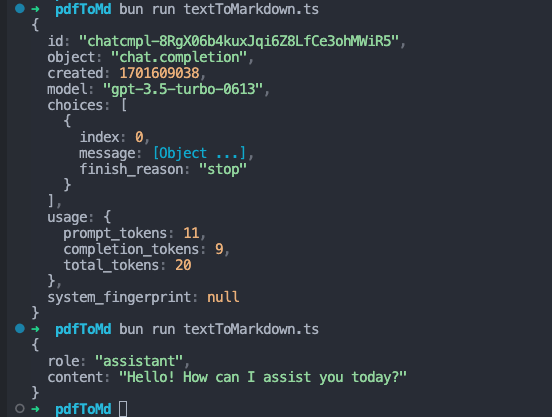
あとはこれでリクエストを送れば...!
const prompt = `以下のテキストをmarkdown形式に変換してください。
${text}`
const openai = new OpenAI({ apiKey });
const chatCompletion = await openai.chat.completions.create({
messages: [{role: "user", content: prompt[0]},{role: "user", content: prompt[1]}],
model,
});
あれ...?!

なるほど、送受信できるリクエスト文字数(トークン数)に上限があるみたいですね。
PDFページごとにファイルを分割してファイルごとにリクエスト送信、受信するようにする
ざっくり。
表の情報が漏れがちなのでなんとかしたい...
最終的な完成品!
精度は何とも言えないけど一からPDFー>Markdownするのに比べたらだいぶマシかも?プロンプトエンジニアリングの勉強にもなった!