LangExtractで辛いクレーム抽出を快適に!
はじめに

私は某コンビニで3年ほどアルバイトをしていました。今回は、業務の中で最もストレスかつ時間を食う、お客様のクレームについて焦点を当てます。一部では、毛が抜けるほど辛辣なクレームも存在します。そんなクレームを、楽しく抽出する最先端の方法をご紹介します。
※今回は、クレームをテキストデータで取得できたと仮定し、それらの非構造化テキストデータを構造化データに出力させる処理を行います。
LangExtractとは
Googleが2025年7月30日にリリースした、非構造化テキストから構造化データを抽出するOSSのPythonライブラリです。LangExtractの核となる技術は、医療情報の抽出や電子カルテの情報処理のために開発された機能(薬剤、投与量、その他の属性などの関係性を対応付ける)でしたが、これを応用し開発されました。
対象読者
非構造化テキストデータを構造化データに変換・出力したい人。
例えば、お客様のクレーム(テキストデータ)を正確かつ効率的に抽出したい人
記事を読むメリット
非構造化テキストから欲しい情報を構造化データとして、安全かつ信頼性高く、抽出することができる。さらに、変換した構造化データの引用元を明確にすることができる。
本文
LangExtract 7つの特徴
- 正確なsource grounding
- 抽出された情報は引用元のテキストに対応付けられる。さらに、下の画像で示すように、引用元のテキストを強調表示することで抽出した情報の評価と検証が容易になる。
- 信頼性の高い構造化された出力
- 希望する出力形式をLangExtractのデータ表現で定義し、下の画像のようにいくつかの例 (few-shot) を与えるだけで、LangExtractはスキーマに対応できる。これにより、一貫性のある構造化出力が可能。
- 最適化された長文の情報抽出
- 長文の情報抽出は複雑になりがち。しかし、LangExtractはチャンク分割戦略、並列処理、注目するコンテキストでの複数回の抽出パスを使用し、処理することで長文の情報抽出を最適化する。
- インタラクティブな可視化
- テキストからインタラクティブな独立したHTMLの可視化をわずか数分で作成可能。LangExtractは、抽出されたエンティティを文脈内で確認し、数千のアノテーションを簡単に探索することができる。
- LLMのための柔軟なサポート
- クラウド・ローカル問わず、好みのLLMを選べる。
- 異なるドメインに柔軟
- 少数の適切な例を指定するだけで、ファインチューニングなしに、どの分野においても情報抽出タスクを定義できる。
- LLMの知識を活用できる
- LLMのもつ知識を活用して補完的な情報を提供することも可能。補足知識の正確性や関連性はどのLLMを選択するか、また適切なプロンプト例を書けるかどうかにかかっている。
試してみたコード
ライブラリのInstall
pip install langextract
情報抽出タスクの定義
なるべく明確に質の良いいくつかのスキーマの例 (few-shot) を与えるのがコツ
# 必要なライブラリのインポート
import textwrap
import langextract as lx
from google.colab import userdata
# 適切なプロンプトを書く
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")
# いくつかのスキーマの例 (few-shot) を与える
examples = [
lx.data.ExampleData(
text=(
"ROMEO. But soft! What light through yonder window breaks? It is"
" the east, and Juliet is the sun."
),
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"},
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"},
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"},
),
],
)
]
# 入力(今回は架空のクレーム)をもとに、抽出開始
input_text = (
"The lunch box I bought at the convenience store this morning had expired. I didn't notice until after I finished eating it, so there's nothing I can do about it now. Why didn't the clerk throw it away? I can't believe they would sell expired food to customers. They must think we're stupid! And since it's summer, I'm worried I might get sick..."
)
# Colab secretsからAPI keyの取得
GOOGLE_API_KEY = userdata.get('GOOGLE_API_KEY')
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.0-flash-lite",
api_key=GOOGLE_API_KEY,
)
# 結果の出力
print(result)
結果の可視化
# JSONL fileに保存
lx.io.save_annotated_documents([result], output_name="/content/test_output/extraction_results.jsonl")
# インタラクティブな結果を可視化するHTMLファイルを生成
html_content = lx.visualize("/content/test_output/extraction_results.jsonl")
html_content = html_content.data
with open("visualization.html", "w") as f:
f.write(html_content)
出力されたHTML ファイル
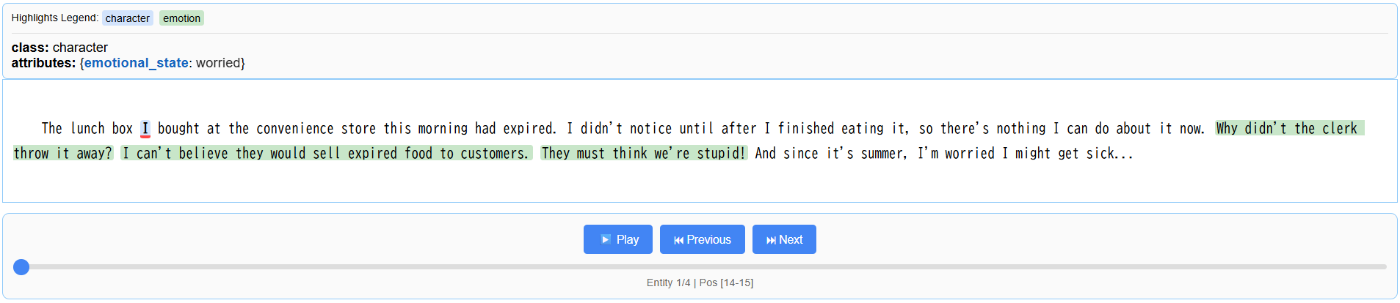
左上のcharacterでI(お客様)がemotionでworried(心配している)、と正しい意図を抽出できています。
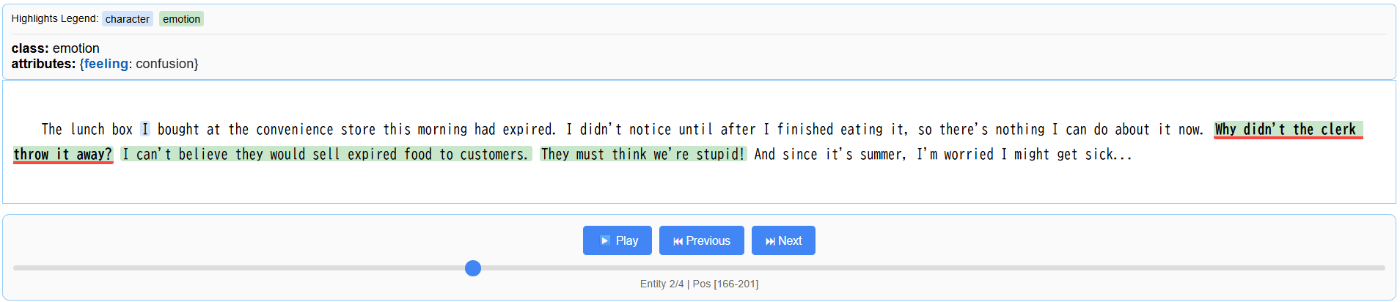
emotionでconfusion(困惑)と正しく意図を抽出できています。

emotionでdisbelief(不信感)と正しく意図を抽出できています。

emotionでanger(怒り)と正しく意図を抽出できています。
まとめ

このように手軽にテキストから属性別に構造化されたデータを抽出することができました。正面から向き合って読むのが辛い過激なクレーム文や、整理されていない重要な情報やノウハウが埋め込まれたテキストに対して、信頼性高く構造化データを抽出する有効な手法の1つだといえます。
私も触ったばかりで、まだ使いこなせてはいませんが、LLMのモデルを変えたり、プロンプトを工夫しより良い抽出を目指します。
ここまで記事を見てくださりありがとうございました。
Discussion