1 社内文書の準備
ここでは社内文書をNotionで管理していることを想定して、サンプルデータをNotion上に作成します。
1.1 Integrationの作成
Integrationにて、新しいIntegrationを作成する。
ここで生成されたトークンはNotion APIを利用する際に必要となるので控えておいてください。
1.2 データベースの作成
Notionで社内文書を管理するデータベースを作成します。
1.2.1 Notionでページを追加し、「テーブル」を選択してください。

1.2.2 ここでは以下のようなデータベースを作成しました。
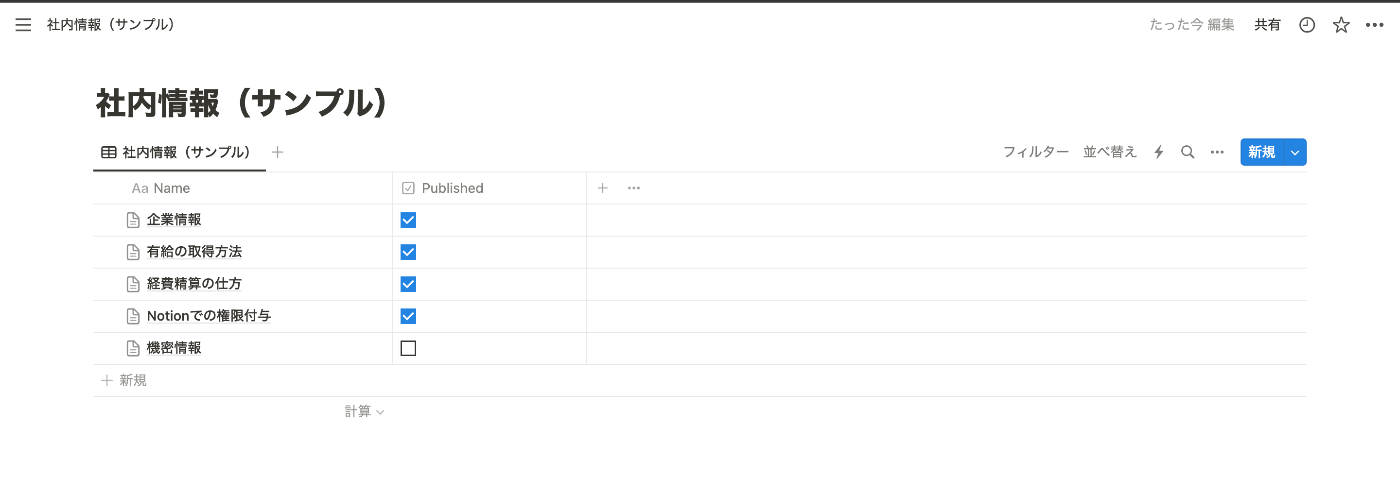
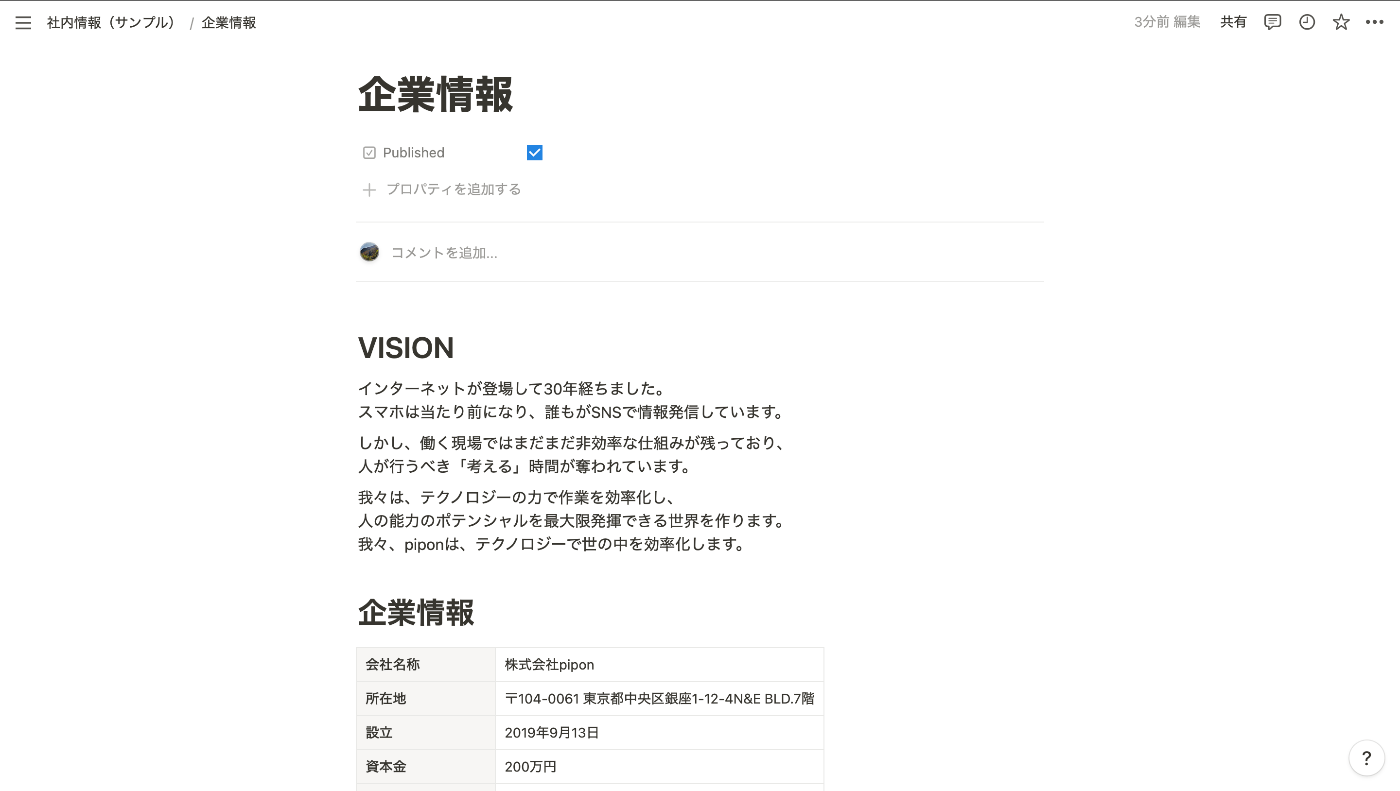
1.2.3 データベースにアクセスできるように先ほど作成したIntegrationを追加します。

2 社内文書の取得
Notion APIでデータベースにアクセスして、データを取得していきます。
2.1 「insert_internal_documents」というフォルダを作成し、Visual Studio Codeで開きます。
2.2 「insert_internal_documents.ipynb」というファイルを作成します。
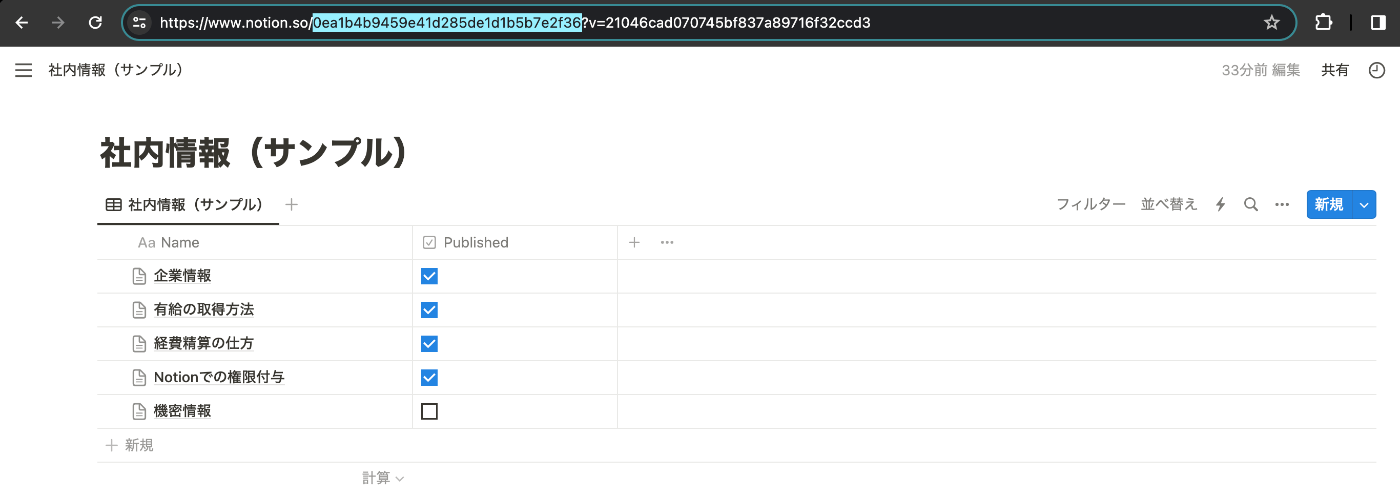
2.3 先ほど控えたNotion APIのトークンとデータベースIDを設定します。データベースIDはNotionのURLから確認することができます。下の画像では「0ea1b4b9459e41d285de1d1b5b7e2f36」の部分がデータベースIDです。
import requests
# Notion APIトークン
token = 'secret_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
# データベースID
database_id = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
2.4 データベースからPublishedにチェックが入っているページの情報を取得する関数を作成します。
# ページの取得
def get_pages(token, database_id):
# ヘッダーにAuthorizationを設定
headers = {
'Authorization': f'Bearer {token}',
'Notion-Version': '2022-06-28' # Notion APIバージョン
}
# フィルタリング条件を設定
filter_condition = {
"property": "Published", # チェックボックスのプロパティ名
"checkbox": {
"equals": True # Trueであるアイテムをフィルタリング
}
}
url = f'https://api.notion.com/v1/databases/{database_id}/query'
data = {
"filter": filter_condition
}
response = requests.post(url, headers=headers, json=data)
pages = response.json()
return pages
2.5 先ほど取得したページの情報にあるページIDからページの内容を取得する関数を作成します。
# ページの内容を取得
def get_page_data(token, page_id):
# Notion APIエンドポイント
endpoint = f"https://api.notion.com/v1/blocks/{page_id}/children"
# リクエストヘッダー
headers = {
"Authorization": f"Bearer {token}",
"Notion-Version": "2022-06-28",
"Content-Type": "application/json",
}
# APIリクエストを送信してページの内容を取得
response = requests.get(endpoint, headers=headers)
if response.status_code == 200:
page_data = response.json()
return page_data
else:
print(f"エラー:{response.status_code}")
return None
2.6 ページの内容からテキストと子ページのタイトルを抽出する関数を作成します。
# ページの内容からテキストと子ページのタイトルを抽出
def extract_text_and_titles(data):
text = ""
for block in data['results']:
if block['type'] == 'paragraph':
text += block['paragraph']['rich_text'][0]['text']['content'] + '\n'
elif block['type'] == 'heading_1':
text += block['heading_1']['rich_text'][0]['text']['content'] + '\n'
elif block['type'] == 'heading_2':
text += block['heading_2']['rich_text'][0]['text']['content'] + '\n'
elif block['type'] == 'heading_3':
text += block['heading_3']['rich_text'][0]['text']['content'] + '\n'
elif block['type'] == 'bulleted_list_item':
text += block['bulleted_list_item']['rich_text'][0]['text']['content'] + '\n'
elif block['type'] == 'child_page':
text += block['child_page']['title'] + '\n'
# textの最後の改行を削除
text = text.rstrip('\n')
return text
2.7 上記3つの関数を用いてデータベースにあるページの内容とURLを取得する関数を作成します。
def get_notion_info(token, database_id):
# 保存用の配列
contents = []
# データベースからページを全て取得
pages = get_pages(token, database_id)
# ページデータを表示
for page in pages['results']:
page_url = page['url']
page_id = page['id']
page_data = get_page_data(token, page_id)
content = extract_text_and_titles(page_data)
# URLとページの内容を配列に追加
contents.append([page_url, content])
return contents
2.8 最後に作成した関数を実行することで、データベースにあるページの内容とURLをリストで取得できていることを確認する。
contents = get_notion_info(token, database_id)
print(contents)
[['https://www.notion.so/Notion-5ac93f250a764049880e2d1e4bcebebe', 'Notionで新規ページを作成する権限を付与してもらう方法は以下の手順に従います。\nワークスペースの管理者に連絡\n最初に、ワークスペースの管理者(北爪さん)に連絡し、ページ作成の権限を要求します。\n権限レベルの確認\n管理者は、あなたのアカウントがどの権限レベルにあるかを確認します。Notionでは、一般的に「メンバー」または「管理者」になる必要があります。\n権限の変更\n管理者は、ワークスペースの設定にアクセスし、あなたのアカウントの権限を「メンバー」や「管理者」に変更できます。\nページ作成の確認\n権限が変更された後、新しいページを作成して、権限が正しく設定されていることを確認します。\n追加の設定\n必要に応じて、特定のページやフォルダーに対する追加のアクセス権を設定することができます。'], ['https://www.notion.so/544110ecdefc441282d1731132e940fb', '経費精算の手順は以下の通りです。\n経費の規定確認\n精算可能な経費とその条件を、会社の経費規定やマニュアルで確認します。\nレシートや領収書の収集\n精算する経費に関するレシートや領収書を収集します。\n経費報告書の作成\n所定の経費報告書に、日付、経費の種類、金額、経費の目的や理由を記入します。デジタルのシステムを使用する場合は、オンラインで入力します。\n添付資料の準備\nレシートや領収書のコピー、必要に応じて移動経路や時間帯の説明を添付します。\n上司への提出・承認依頼\n報告書と添付資料を上司に提出し、承認を依頼します。\n経理部門への提出\n上司の承認を得た後、報告書と添付資料を経理部門に提出します。\n精算の処理待ち\n経理部門での精算処理を待ちます。この段階で不明点があれば経理部門から問い合わせが来ることがあります。\n精算金の受領\n精算が完了し、指定された方法(銀行振込、給与との併給など)で精算金を受領します。\n注意点\nレシートや領収書は紛失しないように注意し、必要な情報が全て記載されていることを確認します。\n精算申請はできるだけ早めに行うことが望ましいです。'], ['https://www.notion.so/5d5bf255419540a483ad54bfcc7b8474', 'VISION\nインターネットが登場して30年経ちました。\nスマホは当たり前になり、誰もがSNSで情報発信しています。\nしかし、働く現場ではまだまだ非効率な仕組みが残っており、\n人が行うべき「考える」時間が奪われています。\n我々は、テクノロジーの力で作業を効率化し、\n人の能力のポテンシャルを最大限発揮できる世界を作ります。\n我々、piponは、テクノロジーで世の中を効率化します。\n企業情報\n会社名称:株式会社pipon\n所在地:〒104-0061 東京都中央区銀座1-12-4N&E BLD.7階\n設立:2019年9月13日\n資本金:200万円\n代表取締役社長:北爪聖也\n代表メールアドレス:seiyakitazume@pi-pon.com'], ['https://www.notion.so/a3c34ef7df2747398b2137c5cba2f189', '有給休暇の取得手順は以下の通りです。\n有給休暇の残数確認\nまず、自分が取得可能な有給休暇の残数を人事部門や専用のシステムで確認します。\n日程の選定\n休暇を取りたい日程を決めます。有給休暇の申請期限は、急な体調不良等の例外を除き取得日の一週間前までとします。\n上司への相談\n休暇を取る前に、上司に相談し、休暇の理由と日程を伝えます。この時、業務に支障がないかどうかも話し合います。\n申請書の提出\n上司の承認を得たら、有給休暇申請書を作成し提出します。申請書は電子システムを使って提出することができます。\n申請の承認待ち\n申請書が人事部門によって処理され、承認されるのを待ちます。\n休暇の準備\n休暇中の業務に影響がないように、事前に業務の引き継ぎや準備を行います。\n休暇の取得\n承認されたら、休暇を取得します。この時、緊急連絡先などを職場に伝えておくことも重要です。\n復帰後のフォローアップ\n休暇から戻った後は、業務のキャッチアップや引き継いだ業務の報告を行います。\n注意点\n繁忙期など、会社の業務に支障をきたす時期には休暇の取得が難しい場合があります。\n長期休暇を取る場合は、より早めに手続きを進めることが望ましいです。']]
3 社内文書の挿入
取得したNotionのデータをCognitive Searchのインデックスへ追加します。
3.1 以下のライブラリをインストールします。
openai
tiktoken
python-dotenv
azure-search-documents==11.4.0b8
azure-identity==1.13.0b4
langchain
3.2 先ほど作成した「insert_internal_documents」フォルダに「.env」ファイルを追加します。
「OPENAI_API_EMBEDDING_MODEL_NAME」と「OPENAI_API_EMBEDDING_DEPLOYMENT_NAME」は、「第6章 Azure環境構築 6 Azure OpenAI」でドキュメントのベクトル化用にデプロイしたモデル名とデプロイ名です。
「OPENAI_API_KEY」はAzure上で「Azure OpenAI」の「キーとエンドポイント」のキーから取得します。
「AZURE_VECTORE_STORES_ADDRESES」は、Azure上で「Cognitive Search」の「概要」の「URL」から取得します。
「AZURE_VECTORE_STORES_PASSWORD」は、Azure上で「Cognitive Search」の「キー」の「プライマリ管理者キー」から取得します。
「AZURE_VECTORE_STORES_INDEX_NAME」はインデックスの名前で、任意の名前とします。
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxx
OPENAI_API_EMBEDDING_MODEL_NAME=text-embedding-ada-002
OPENAI_API_EMBEDDING_DEPLOYMENT_NAME=text-embedding-ada-002
AZURE_VECTORE_STORES_ADDRESES=https://xxxxxxxxxxxxxxxxxxxxxxxx.search.windows.net
AZURE_VECTORE_STORES_PASSWORD=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
AZURE_VECTORE_STORES_INDEX_NAME=sample-internal-documents
3.3 先ほど作成した「insert_internal_documents.ipynb」ファイルに取得したNotionのデータをCognitive Searchのインデックスへ追加するコードを記述していきます。まずは、文章とメタデータを受け取り、Documentのリストを返す関数を作成します。
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
# 文章とメタデータを受け取り、Documentのリストを返す
def txtToDocs(content:str, metadata:dict):
docs = [Document(page_content=content, metadata=metadata)] # Documentのリストを作成
chunk_size=1000 # Documentの文字数の設定
separator='' # Documentの区切り文字の設定(''の場合、chunk_sizeで指定した文字数で区切る)
chunk_overlap=50 # 分割した文章のオーバーラップする文字数の設定
# 文章を分割するためのインスタンスを作成
text_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
separator=separator,
chunk_overlap=chunk_overlap
)
# Documentのリストを設定したパラメータで分割
splitted_docs = text_splitter.split_documents(docs)
return splitted_docs
3.4 ベクターストアのインデックスを作成する関数を作成します。
import os
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores.azuresearch import AzureSearch
# ベクターストアのロード
def azureLoad(fields=None):
embeddings: OpenAIEmbeddings = OpenAIEmbeddings(
deployment=os.environ['OPENAI_API_EMBEDDING_DEPLOYMENT_NAME'], # モデルのデプロイメント名
model_name=os.environ['OPENAI_API_EMBEDDING_MODEL_NAME'] # モデル名
) # OpenAIのモデルを使用してベクトル化
# ベクターストアのインスタンスを作成
vectore_stores: AzureSearch = AzureSearch(
azure_search_endpoint=os.environ['AZURE_VECTORE_STORES_ADDRESES'],
azure_search_key=os.environ['AZURE_VECTORE_STORES_PASSWORD'],
index_name=os.environ['AZURE_VECTORE_STORES_INDEX_NAME'],
embedding_function=embeddings.embed_query,
fields=fields
)
return vectore_stores
3.5 ベクターストアへのドキュメントの追加する関数を作成します。
from azure.search.documents.indexes.models import (
SearchableField,
SearchField,
SearchFieldDataType,
SimpleField
)
# ベクターストアへのドキュメントの追加
def azureAddDocuments(documents:list[Document]):
embeddings: OpenAIEmbeddings = OpenAIEmbeddings() # OpenAIのモデルを使用してベクトル化
# ベクターストアの検索フィールドの設定
# metadataでフィルタリングする場合は、filterable=Trueを設定する
fields = [
SimpleField(
name="id",
type=SearchFieldDataType.String,
key=True,
filterable=True,
),
SearchableField(
name="content",
type=SearchFieldDataType.String,
searchable=True,
),
SearchField(
name="content_vector",
type=SearchFieldDataType.Collection(SearchFieldDataType.Single),
searchable=True,
vector_search_dimensions=len(embeddings.embed_query("Text")),
vector_search_configuration="default",
),
SearchableField(
name="metadata",
type=SearchFieldDataType.String,
searchable=True,
),
# フィルタリングしたいmetadataはここに追加する
SimpleField(
name="notion_id", # フィルタリングしたいmetadataのキー
type=SearchFieldDataType.String, # フィルタリングしたいmetadataの型
filterable=True, # フィルタリング可能にする
),
]
vectore_stores = azureLoad(fields=fields) # ベクターストアのロード
res = vectore_stores.add_documents(documents) # ベクターストアへのドキュメントの追加
return res
3.6 取得したNotionのデータをCognitive Searchのインデックスへ追加します。
from dotenv import load_dotenv
load_dotenv() # .envファイルから環境変数を読み込む
for content in contents:
metadata = {
"notion_id": content[0],
}
docs = txtToDocs(content[1], metadata)
azureAddDocuments(docs)
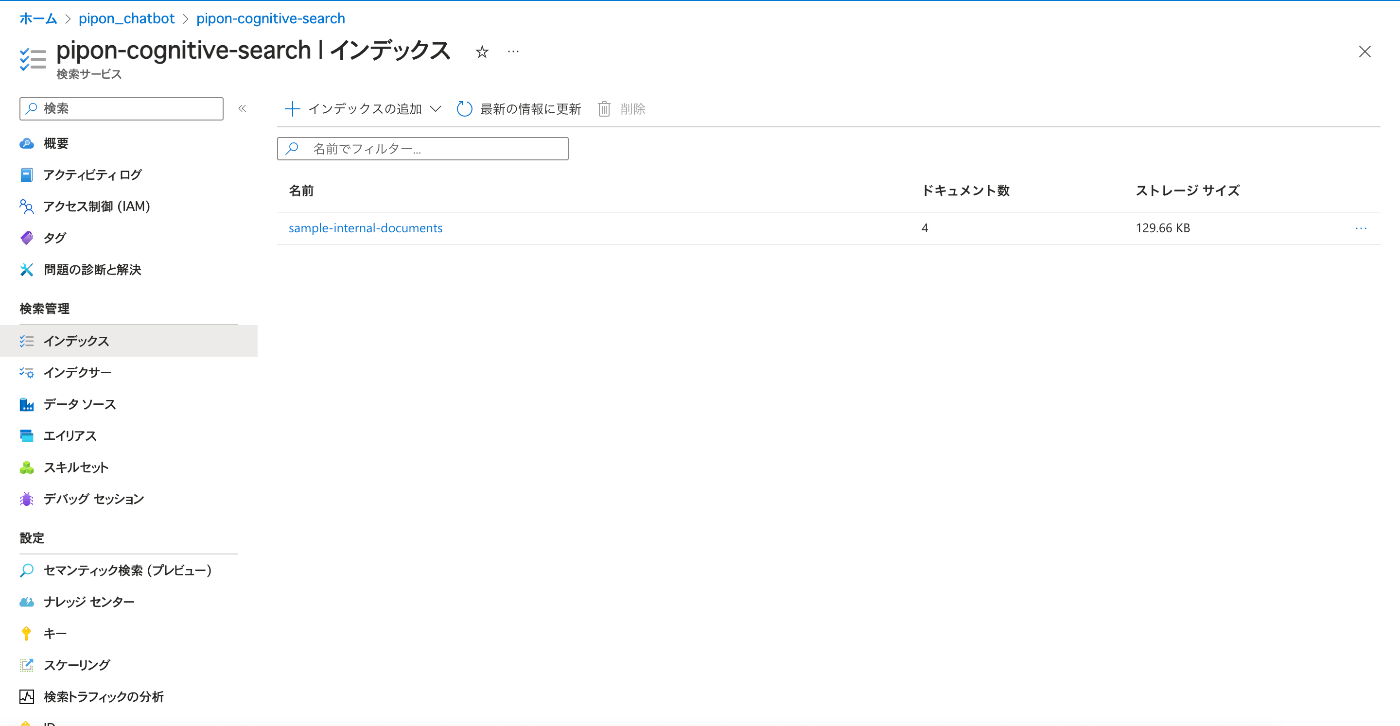
3.7 AzureのCongnitive Searchでインデックスが追加されていることを確認します。
お知らせ
もちろん、株式会社piponでも技術でお困りのことがある方はオンライン相談が可能です。
こちらから会社概要資料をDLできます!
お問い合わせ内容に「オンライン相談希望」とご記載ください。
お問い合わせはこちら
株式会社piponでは定期的に技術勉強会を開催しています。
ChatGPT・AI・データサイエンスについてご興味がある方は是非、ご参加ください。
技術勉強会についてはこちら
株式会社piponではChatGPT・AI・データサイエンスについて業界ごとの事例を紹介しています。ご興味ある方はこちらのオウンドメディアをご覧ください。
オウンドメディアはこちら

株式会社piponのテックブログです。 ChatGPTやAzureをメインに情報発信していきます! お問い合わせはフォームへお願いします。 会社HP pipon.co.jp/ フォーム share.hsforms.com/19XNce4U5TZuPebGH_BB9Igegfgt
Discussion