

LLMを活用したチャットボットの開発には様々な工夫ポイントがありますよね。
①参照データセットをベクトルデータベースに入れられる形に前処理する
②分割サイズ
③どの程度overlapさせるか
③何のアルゴリズムでEmbeddingするか
④LLMはChatGPT,Claudeなど様々あるが、何を選択するか
⑤どのようなプロンプトを作成してユーザーへの回答を作成するか
この5つのポイントで何を選択するかによって、チャットボットの回答が変わってきます。
そのため、どんなデータを参照させるのか、誰が質問するのか、データに合わせて状況に合わせて、開発者はチャットボットをチューニングしていると思います。
このように開発者としては、様々な工夫を凝らしてチャットボットを開発するのですが、こちらでコントロールできないことがあります。
それは、ユーザーの質問内容。
どんなに素晴らしいチャットボットを構築しようとも、ユーザーが分かりづらい文章を送ってしまえば正しい回答は出てきません。。。工夫した開発も水の泡。
そんな時におすすめの手法があります。
HyDE(Hypothetical Document Embeddings)と呼ばれる手法で、
ユーザーからの質問を直接ベクトル化するのではなく、LLMに仮説的に回答を作らせて、その回答をベクトル化して検索に使います。
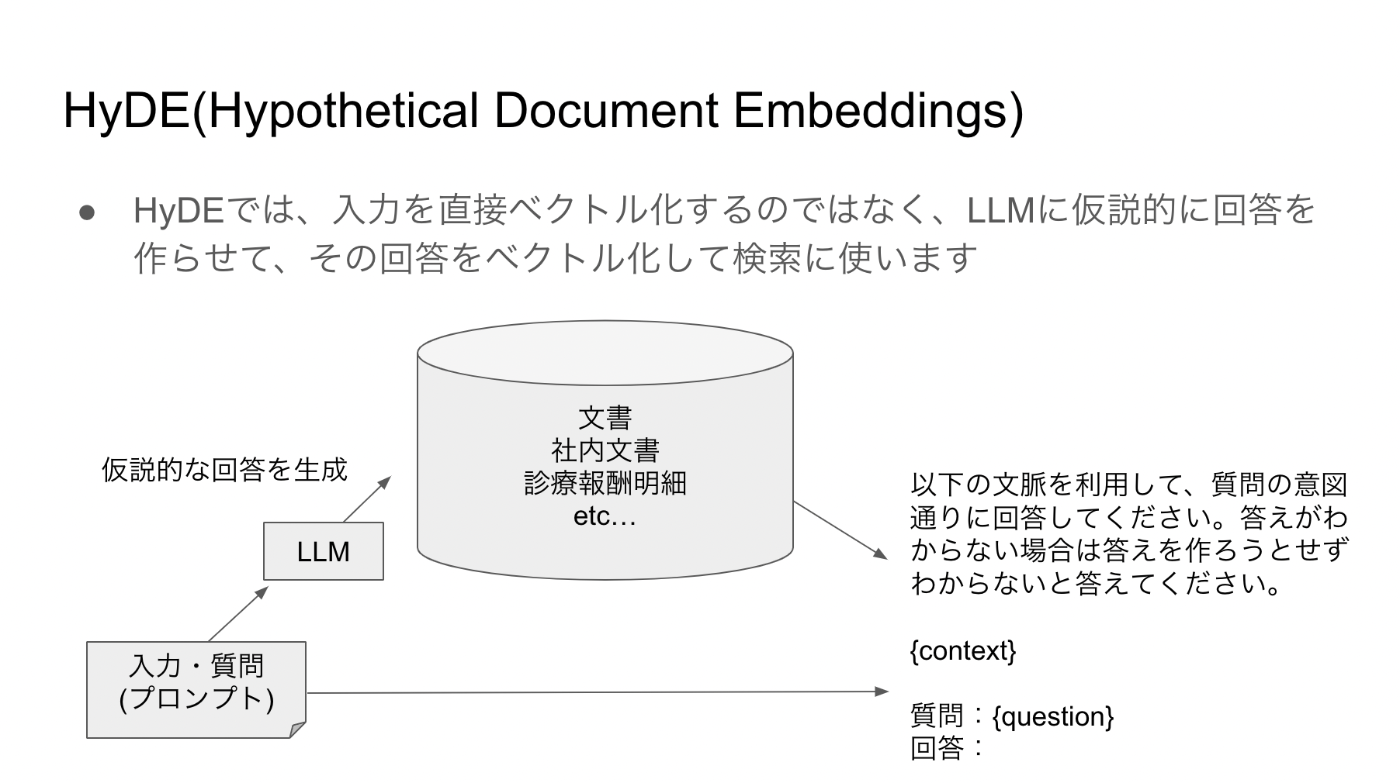
HyDEのアプローチは、具体的には、以下のようなプロセスを経て、答えを見つけます。
-
仮説の生成:
- 最初に、HyDEは質問から仮説的な答えを生成します。
-
仮説を使った検索:
- 次に、この仮説的な答えを使って、ドキュメントの集合を検索します。
-
高精度の検索:
- この方法により、通常の検索方法よりも高い精度で関連するドキュメントを見つけることができると考えられています。
簡単に言えば、HyDEは賢い探偵のようなもので、ユーザーの質問内容からヒントを得て、それを使って大量の文書の中から必要な情報を見つける方法です。
ユーザーが開発者の意図通りの質問をしてくれない、、、そんな時はぜひこちらの手法を使ってみてください。
もちろん、株式会社piponでも技術でお困りのことがある方はオンライン相談が可能です。
こちらから会社概要資料をDLできます!
お問い合わせ内容に「オンライン相談希望」とご記載ください。
株式会社piponでは定期的に技術勉強会を開催しています。
ChatGPT・AI・データサイエンスについてご興味がある方は是非、ご参加ください。
株式会社piponではChatGPT・AI・データサイエンスについて業界ごとの事例を紹介しています。ご興味ある方はこちらのオウンドメディアをご覧ください。

株式会社piponのテックブログです。 ChatGPTやAzureをメインに情報発信していきます! お問い合わせはフォームへお願いします。 会社HP pipon.co.jp/ フォーム share.hsforms.com/19XNce4U5TZuPebGH_BB9Igegfgt
Discussion