LLMをこちらの思い通りのチャットボットになってもらうための手法はいくつかあります。
- プロンプトをゴリゴリと書いて、ChatGPTをこちらの意図通り動かす
- 文書をEmbeddingしてそれをベクトルデータベースに格納し、最適な文書を引っ張り、参照させながら、ユーザーの意図通りに動かす
- データを用意してChatGPTをファインチューニングさせる。
- LLaMA(Metaの開発したLLM)に自前のデータ加えた分野特化LLM作る
様々な方法がある中で、今回はファインチューニングを行う方法について解説します。
ここで言うファインチューニングは、よりパラメータ数の少ないニューラルネットワークを作り、そちらのパラメータだけをアップデートするParameter efficient fine-tuning(PEFT)と呼ばれる手法の話です。
層全体のパラメータ更新ではなくて、層の中の一部のパラメータの更新をします。
ファインチューニングは何がいいの?
ファインチューニングを選択するメリットを3点挙げると以下のようになります。
-
1.少ないデータでもパフォーマンスが良い!
一般的なモデルよりも少ないデータで高いパフォーマンスを出せるようになる場合がある。データが限られているケースで有用! -
2.特定用途への適応力向上!
特定の業界や用途に合わせた精度の高いレスポンスが可能になる。 -
3.既存の強みの活用!
ファインチューニングでは、元のモデルが持っている広範な知識や言語理解能力を維持しつつ、特定のタスクに特化させることができます。ChatGPTの持っている能力はそのままに、特定ドメインに特化させることができます。
そんな素敵なファインチューニングですが、
「LoRA: Low-Rank Adaptation of Large Language Mode」と言う論文が非常に有名です。
LoRA: Low-Rank Adaptation of Large Language Modeとは
この論文では、従来の「ファインチューニング」は、全てのモデルパラメータを再訓練する必要があり、大規模なモデルになるほどそれが困難となりますが、「Low-Rank Adaptation(LoRA)」と呼ばれる手法により、訓練する必要があるパラメータの数を大幅に削減できると書いています。
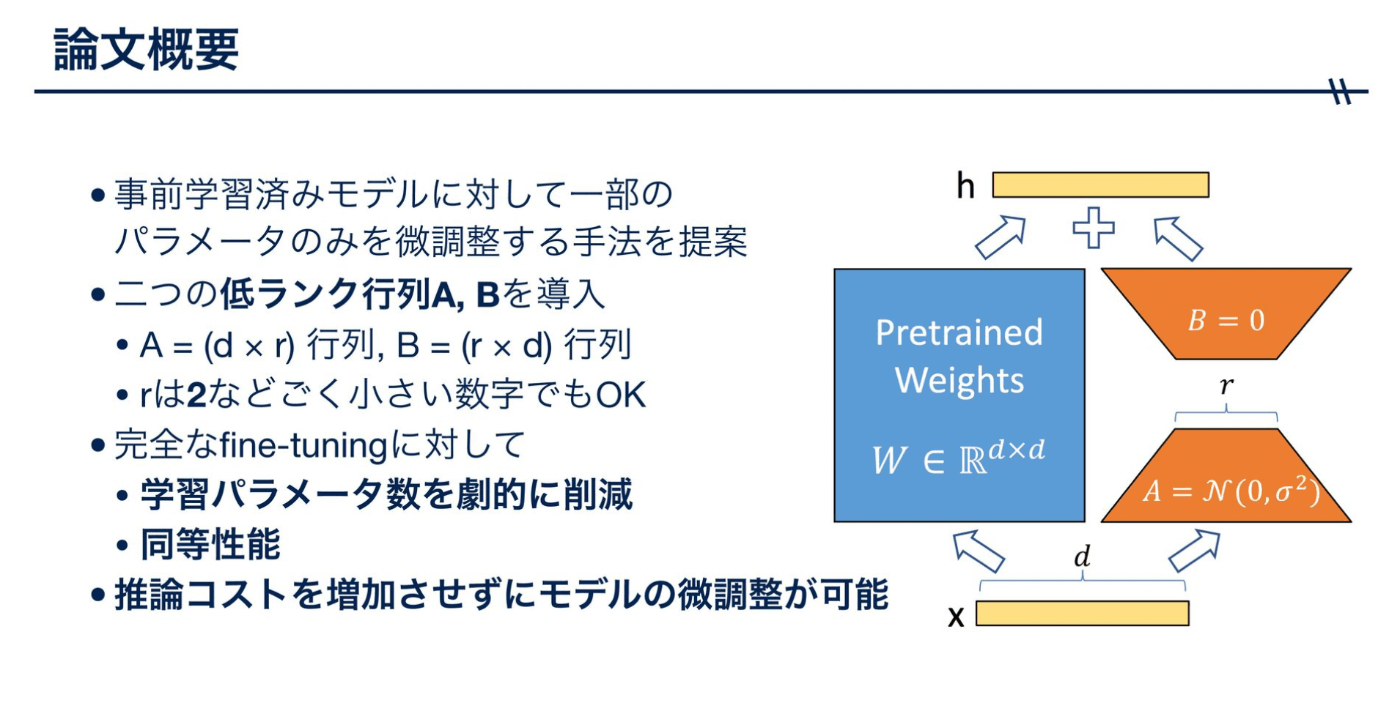
この画像が論文にも載っている、非常にわかりやすい画像になります。
各層のトランスフォーマー層に訓練可能な「ランク分解行列」を追加することで、パラメータを更新するのは、この画像のオレンジ色の台形のところだけで良くなるということが解説されています。
台形部分だけでよければ、長方形の部分より面積小さくなります。
これだけ学習させるところが小さくなる分、計算量も減らすことができるのです。
行列を2つ用意していて。
最初、d ✖️ r ✖️ r ✖️ dになるのですが、
行列の公式で、最初の次元と最後の次元の計算結果と同じになるのです。
最終的にd ✖️ dになります。
すごいシンプルな数値で当てはめると、
長方形だと・・・・
d = 10 とすると
d x d = 100 の計算コストがかかるが、
台形だと・・・・
r = 1
d x r = 10 とすると
d x r + d x r = 10 + 10 = 20 の計算コストで良いのです。
かなり計算コストが削減されました
望み通りのLLMを開発したい、と考えた時にこの手法によって、ファインチューニングが選択肢の1つになり得るということで、LoRAの解説でした。
最後にお知らせです!GPTの勉強会を定期的に開催しています!
ご興味ある方はこちらからご参加ください!
また、piponの案件事例をまとめているオウンドメディアはこちらになります。こちらも是非チェックしてください。

株式会社piponのテックブログです。 ChatGPTやAzureをメインに情報発信していきます! お問い合わせはフォームへお願いします。 会社HP pipon.co.jp/ フォーム share.hsforms.com/19XNce4U5TZuPebGH_BB9Igegfgt
Discussion