Open12
Unity Barracuda用の GatherND 実装とONNXエクスポート
Barracuda's Flatten does not support axis, which is affecting the model, and Reshape's dimensionality mismatch error occurs when the model is loaded to the end while ignoring axis. Thus, I would expect that replacing Flatten with Reshape would load successfully.
- 4D GatherND

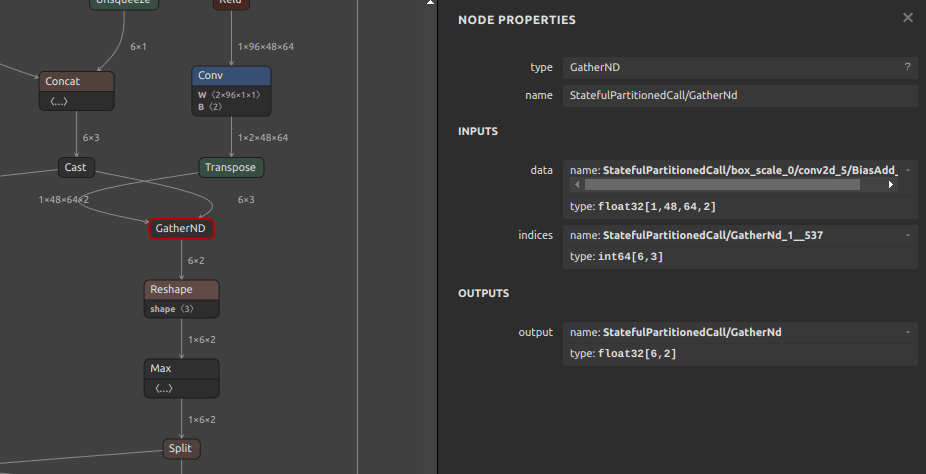
StatefulPartitionedCall/GatherNd [1,48,64,2] [6,3] [6,2] / [1,48,64,2] [6,3] [6,2]
StatefulPartitionedCall/GatherNd_1 [1,48,64,2] [6,3] [6,2] / [1,48,64,2] [6,3] [6,2]
StatefulPartitionedCall/GatherNd_2 [48,64,34] [6,2] [6,34] / [48,64,2] [6,3] [6,2]
StatefulPartitionedCall/GatherNd_3 [48,64,17,2] [102,3] [102,2] / [48,64,17,2] [102,3] [102,2]
StatefulPartitionedCall/GatherNd_4 [48,64,17] [102,3] [102] / [48,64,17] [102,3] [102]
GatherNDを別のOPへ置き換える完成形
make_gathernd_replace.py
#! /usr/bin/env python
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '-1'
import tensorflow as tf
import numpy as np
np.random.seed(0)
from ast import literal_eval
from argparse import ArgumentParser
import onnx
import tf2onnx
def barracuda_gather_nd(params, indices):
idx_shape = indices.shape
params_shape = params.shape
idx_dims = idx_shape[-1]
gather_shape = params_shape[idx_dims:]
params_flat = tf.reshape(
params,
tf.concat([[-1], gather_shape], axis=0),
)
axis_step = tf.math.cumprod(
params_shape[:idx_dims],
exclusive=True,
reverse=True,
)
mul = tf.math.multiply(
indices,
axis_step,
)
indices_flat = tf.reduce_sum(
mul,
axis=-1,
)
result_flat = tf.gather(
params_flat,
indices_flat,
)
return tf.reshape(
result_flat,
tf.concat([idx_shape[:-1], gather_shape], axis=0),
)
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument(
'-ms',
'--model_name_suffix',
type=int,
default=0,
help='Model name suffix',
)
parser.add_argument(
'-ds',
'--data_shape',
type=str,
nargs='+',
required=True,
help='Shape of input data "data"',
)
parser.add_argument(
'-is',
'--indices_shape',
type=str,
nargs='+',
required=True,
help='Shape of input data "indices"',
)
parser.add_argument(
'-o',
'--opset',
type=int,
default=11,
help='onnx opset'
)
args = parser.parse_args()
model_name_suffix = args.model_name_suffix
data_shape = []
for s in args.data_shape:
try:
val = literal_eval(s)
if isinstance(val, int) and val >= 0:
data_shape.append(val)
else:
data_shape.append(s)
except:
data_shape.append(s)
data_shape = np.asarray(data_shape, dtype=np.int32)
indices_shape = []
for s in args.indices_shape:
try:
val = literal_eval(s)
if isinstance(val, int) and val >= 0:
indices_shape.append(val)
else:
indices_shape.append(s)
except:
indices_shape.append(s)
indices_shape = np.asarray(indices_shape, dtype=np.int32)
opset = args.opset
MODEL=f'barracuda_gather_nd_{model_name_suffix}'
# Create a model - TFLite
data = tf.keras.layers.Input(
shape=data_shape[1:],
batch_size=data_shape[0],
dtype=tf.float32,
)
indices = tf.keras.layers.Input(
shape=indices_shape[1:],
batch_size=indices_shape[0],
dtype=tf.int32,
)
output = barracuda_gather_nd(data, indices)
model = tf.keras.models.Model(inputs=[data, indices], outputs=[output])
model.summary()
output_path = 'barracuda_gathernd'
tf.saved_model.save(model, output_path)
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS,
tf.lite.OpsSet.SELECT_TF_OPS
]
tflite_model = converter.convert()
open(f"{output_path}/{MODEL}.tflite", "wb").write(tflite_model)
# Create a model - ONNX
model_proto, external_tensor_storage = tf2onnx.convert.from_tflite(
tflite_path=f"{output_path}/{MODEL}.tflite",
opset=opset,
output_path=f"{output_path}/{MODEL}.onnx",
)
# Optimization - ONNX
model_onnx1 = onnx.load(f"{output_path}/{MODEL}.onnx")
model_onnx1 = onnx.shape_inference.infer_shapes(model_onnx1)
onnx.save(model_onnx1, f"{output_path}/{MODEL}.onnx")
python make_gathernd_replace.py \
--model_name_suffix 0 \
--data_shape 1 48 64 17 \
--indices_shape 6 3 \
--opset 11

NUM=0
onnx2json \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--output_json_path barracuda_gather_nd_${NUM}.json \
--json_indent 2
sed -i -e 's/"elemType": 6,/"elemType": 7,/g' barracuda_gather_nd_${NUM}.json
sed -i -e 's/"dataType": 6,/"dataType": 7,/g' barracuda_gather_nd_${NUM}.json
sed -i -e 's/"rawData": "AAwAAEAAAAABAAAA"/"rawData": "AAwAAAAAAABAAAAAAAAAAAEAAAAAAAAA"/g' barracuda_gather_nd_${NUM}.json
json2onnx \
--input_json_path barracuda_gather_nd_${NUM}.json \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
NUM=1
onnx2json \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--output_json_path barracuda_gather_nd_${NUM}.json \
--json_indent 2
sed -i -e 's/"elemType": 6,/"elemType": 7,/g' barracuda_gather_nd_${NUM}.json
sed -i -e 's/"dataType": 6,/"dataType": 7,/g' barracuda_gather_nd_${NUM}.json
sed -i -e 's/"rawData": "AAwAAEAAAAABAAAA"/"rawData": "AAwAAAAAAABAAAAAAAAAAAEAAAAAAAAA"/g' barracuda_gather_nd_${NUM}.json
json2onnx \
--input_json_path barracuda_gather_nd_${NUM}.json \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
NUM=2
onnx2json \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--output_json_path barracuda_gather_nd_${NUM}.json \
--json_indent 2
sed -i -e 's/"elemType": 6,/"elemType": 7,/g' barracuda_gather_nd_${NUM}.json
sed -i -e 's/"dataType": 6,/"dataType": 7,/g' barracuda_gather_nd_${NUM}.json
sed -i -e 's/"rawData": "QAAAAAEAAAA="/"rawData": "QAAAAAAAAAABAAAAAAAAAA=="/g' barracuda_gather_nd_${NUM}.json
json2onnx \
--input_json_path barracuda_gather_nd_${NUM}.json \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
NUM=3
onnx2json \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--output_json_path barracuda_gather_nd_${NUM}.json \
--json_indent 2
sed -i -e 's/"elemType": 6,/"elemType": 7,/g' barracuda_gather_nd_${NUM}.json
sed -i -e 's/"dataType": 6,/"dataType": 7,/g' barracuda_gather_nd_${NUM}.json
sed -i -e 's/"rawData": "QAQAABEAAAABAAAA"/"rawData": "QAQAAAAAAAARAAAAAAAAAAEAAAAAAAAA"/g' barracuda_gather_nd_${NUM}.json
json2onnx \
--input_json_path barracuda_gather_nd_${NUM}.json \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
NUM=4
onnx2json \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--output_json_path barracuda_gather_nd_${NUM}.json \
--json_indent 2
sed -i -e 's/"elemType": 6,/"elemType": 7,/g' barracuda_gather_nd_${NUM}.json
sed -i -e 's/"dataType": 6,/"dataType": 7,/g' barracuda_gather_nd_${NUM}.json
sed -i -e 's/"rawData": "QAQAABEAAAABAAAA"/"rawData": "QAQAAAAAAAARAAAAAAAAAAEAAAAAAAAA"/g' barracuda_gather_nd_${NUM}.json
json2onnx \
--input_json_path barracuda_gather_nd_${NUM}.json \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
rm barracuda_gather_nd_0.json
rm barracuda_gather_nd_1.json
rm barracuda_gather_nd_2.json
rm barracuda_gather_nd_3.json
rm barracuda_gather_nd_4.json
NUM_LIST=(
"0"
"1"
"2"
"3"
"4"
)
for((i=0; i<${#NUM_LIST[@]}; i++))
do
NUM=(`echo ${NUM_LIST[i]}`)
echo @@@@@@@@@@@@@@@@@ processing ${NUM} ...
sor4onnx \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--old_new ":0" "" \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
sor4onnx \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--old_new "serving_default_input_1" "bgn${NUM}_data" \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
sor4onnx \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--old_new "serving_default_input_2" "bgn${NUM}_indices" \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
sor4onnx \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--old_new "PartitionedCall" "bgn${NUM}_output" \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
sor4onnx \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--old_new "model/tf.math.multiply/Mul" "bgn${NUM}_Mul" \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
sor4onnx \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--old_new "model/tf.math.reduce_sum/Sum" "bgn${NUM}_Sum" \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
sor4onnx \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--old_new "const_fold_opt__7" "bgn${NUM}_reshape_const" \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
sor4onnx \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--old_new "Const" "bgn${NUM}_mul_const" \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
sor4onnx \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--old_new "model/tf.reshape/Reshape" "bgn${NUM}_Reshape" \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
sor4onnx \
--input_onnx_file_path barracuda_gather_nd_${NUM}.onnx \
--old_new "model/tf.reshape/Reshape" "bgn${NUM}_Reshape" \
--output_onnx_file_path barracuda_gather_nd_${NUM}.onnx
done

MoveNet MultiPose 対応
NUM=0
snc4onnx \
--input_onnx_file_paths movenet_multipose_lightning_192x256_p6.onnx barracuda_gather_nd_${NUM}.onnx \
--srcop_destop StatefulPartitionedCall/box_scale_0/conv2d_5/BiasAdd__521 bgn${NUM}_data StatefulPartitionedCall/GatherNd_1__537 bgn${NUM}_indices \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
svs4onnx \
--input_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx \
--from_output_variable_name "bgn${NUM}_output" \
--to_input_variable_name "StatefulPartitionedCall/GatherNd" \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
snd4onnx \
--remove_node_names StatefulPartitionedCall/GatherNd \
--input_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
NUM=1
snc4onnx \
--input_onnx_file_paths movenet_multipose_lightning_192x256_p6.onnx barracuda_gather_nd_${NUM}.onnx \
--srcop_destop StatefulPartitionedCall/box_offset_0/conv2d_6/BiasAdd__536 bgn${NUM}_data StatefulPartitionedCall/GatherNd_1__537 bgn${NUM}_indices \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
svs4onnx \
--input_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx \
--from_output_variable_name "bgn${NUM}_output" \
--to_input_variable_name "StatefulPartitionedCall/GatherNd_${NUM}" \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
snd4onnx \
--remove_node_names StatefulPartitionedCall/GatherNd_1 \
--input_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
NUM=2
snc4onnx \
--input_onnx_file_paths movenet_multipose_lightning_192x256_p6.onnx barracuda_gather_nd_${NUM}.onnx \
--srcop_destop StatefulPartitionedCall/kpt_regress_0/conv2d_8/BiasAdd__442 bgn${NUM}_data StatefulPartitionedCall/GatherNd_2__495 bgn${NUM}_indices \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
svs4onnx \
--input_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx \
--from_output_variable_name "bgn${NUM}_output" \
--to_input_variable_name "StatefulPartitionedCall/GatherNd_${NUM}" \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
snd4onnx \
--remove_node_names StatefulPartitionedCall/GatherNd_${NUM} \
--input_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
NUM=3
snc4onnx \
--input_onnx_file_paths movenet_multipose_lightning_192x256_p6.onnx barracuda_gather_nd_${NUM}.onnx \
--srcop_destop StatefulPartitionedCall/Reshape_8 bgn${NUM}_data StatefulPartitionedCall/GatherNd_4__593 bgn${NUM}_indices \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
svs4onnx \
--input_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx \
--from_output_variable_name "bgn${NUM}_output" \
--to_input_variable_name "StatefulPartitionedCall/GatherNd_${NUM}" \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
snd4onnx \
--remove_node_names StatefulPartitionedCall/GatherNd_${NUM} \
--input_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
NUM=4
snc4onnx \
--input_onnx_file_paths movenet_multipose_lightning_192x256_p6.onnx barracuda_gather_nd_${NUM}.onnx \
--srcop_destop StatefulPartitionedCall/Max bgn${NUM}_data StatefulPartitionedCall/GatherNd_4__593 bgn${NUM}_indices \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
svs4onnx \
--input_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx \
--from_output_variable_name "bgn${NUM}_output" \
--to_input_variable_name "StatefulPartitionedCall/GatherNd_${NUM}" \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
snd4onnx \
--remove_node_names StatefulPartitionedCall/GatherNd_${NUM} \
--input_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx \
--output_onnx_file_path movenet_multipose_lightning_192x256_p6.onnx
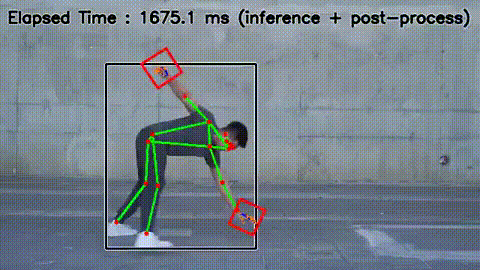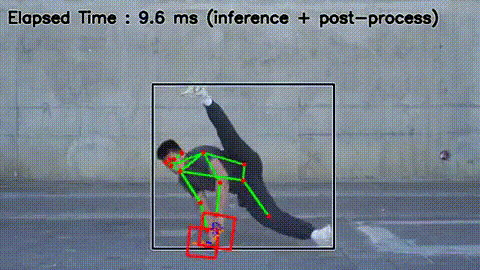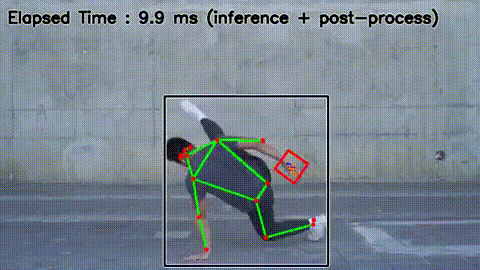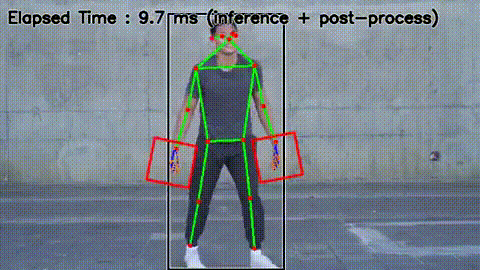
- Before
- After

MoveNet MultiPose 動作確認