Open6
データセントリックのネタ集め
-
前回
- データの品質向上によってモデル本来の性能を引き出すことにある程度成功し、リアル環境下でのノイズ耐性が大幅に向上した
- 副次的効果として画像解像度大幅削減により計算量を大幅に減らしても一定の精度を維持することができるようになった
-
Now
- 一人で高品質データを1年間手作業で作り続けている
- 2024年12月末時点でのアノテーション量は 約600,000個、作業時間は推定数千時間
- YOLO で強力な検出性能を実現できた

- 引き続き物体検出と骨格検出のアノテーションしかしていないので、物体検出・骨格検出の話しかできない
- ドメインが「人」に完全に偏っている
- 既知のタスク自体の考え方を根っこから変えたいというモチベーション
- 通信環境やお金に制約がほとんど無い人はこの話を受けて頑張ることに価値はあまり無い気がするので Gemini 2.0 を使ったほうが 1,000万倍 価値があるものを生み出せると思う
- この取り組みは、研究でも特定の事業とも紐付かないただの個人の興味本位の取り組み
- 数学的・論理的に何も証明していないのであくまで経験則の域を出ない話ととらえてほしい
- 人によって、やり方が合う・合わないは必ずあるので、ただ真似をするのはおすすめしない
-
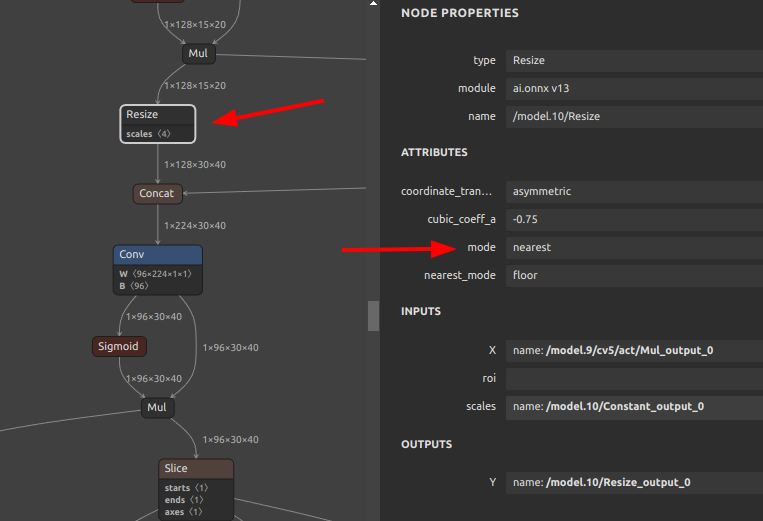
アノテーションツール CVAT
- 拡大・縮小時にバイリニア補間が自動適用される
-
画像拡大時のバイリニア補間
- 最終的にデータを学習させるモデルがおそらくバイリニア補間だから良く効く?
- YOLOv9 の場合は内部処理がすべて
nearestだったので関係なし
- 単純に目視アノテーションのサポートにしかならない
-
基準があいまいな場合のオブジェクトのアノテーション方針検討
-
あいまいの定義について考えてみる- 境界・サイズが曖昧
- 中心位置が曖昧
- テクスチャが曖昧
- オブジェクト間の位置関係である程度判断できそうならアノテーションする
- オブジェクトのテクスチャが全体的にフラット過ぎて位置関係すらも予測不能ならアノテーションしない

- そもそも対象とすべきオブジェクトなのかどうかが曖昧
- 究極、最終的に自分で画像を見て対象オブジェクトと識別できたか、識別できなかったか、しか無い
- 識別できたならアノテーションする、識別できなかったならアノテーションしない
- 人力判断の確信度が 50% を上回るか下回るかぐらいの判断しかできない
-
-
最小サイズ 3x3 ピクセル
-
最大サイズ 画像全体
-
480x360 のリアル画像サイズでの例, 000000049338.jpg, 2356




前提的なメンタルモデル
- 僕が何かすごいことをしているように見えるとしたらそれは違う。金銭的コストや時間的コストを言い訳にしてやるべきことをみんながやっていないだけ。
- いずれ機械に代替されることはわかっているが、そもそも機械的に正確に処理するために、まずは人間が正確なデータを与えない限り永遠に機械が人に近づけない、だからこれは人類の使命とも言える
- 手作業でデータを作り込むのはとてもコストが高く本来は現実的ではないことを理解しつつ、それでもやる。Kaggleなどで提案されているような手法のほうがよほど現実的な路線。手作業は大きくスケールしない。
- 「うまくいくか分からない」は全人類共通の悩みなので、小さく初めて早いタイミングで方向性の良し悪しを見極めるための試行錯誤を大量に繰り返す。そもそも今あなたがやろうとしていることは人類初なはず。答えは自分で確かめて見つける。
- 残念ながら、いかに注意深く、慎重に、ゆっくり、丁寧に作業をしていても人間は100%ミスをする、という前提を置いたタスク設計にしないとダメ
- いっきにゴールを目指そうとしない
- できる限り似たような粒度の作業に細かく分解して異なる粒度の作業の並列度を上げない
- あいまいな判断基準になる部分の対応セオリーを何十種類も意識しながら正確に作業、は不可能
- 並列度を上げる代わりに作業サイクル数を増やしたほうが良い
- 前例が無いチャレンジしかしない
- 前例が無いからこの先に何が起こるか気になる、ワクワクする
- 何が起こっても特に失敗とはとらえない。適当に考えた仮説が誤っていたか正解していたか、が明らかになったにすぎない。
- 新しいアルゴリズムを考えるのとは全く違う切り口で、力技で仮説を証明していくスタイル
- 儲かる、儲からない、最速で結果を出していかなければならない、納期ありき、無価値、のような外野のゴミコメントはすべて無視。それらの考え方で直近の世界線で戦えている、と明言できる人が居るなら理解できるが正直そうなっているとは全く思わない。ゆえに、スタート時点の考え方が全世界の99.7%の人間が間違っている、ぐらいの心持ち。
- しっかり寝る
- とてもしんどいと感じたときは止め時→寝る→寝たら不思議とモチベが復活する
- 作業サイクル数を実質∞と想定する。すなわち、ファイナルリミットを明確に設定しない。
- 時間はどれだけ掛けてもよい
- 人間のメンタルは極めて脆い
テクニック面
- アノテーションしつつ学習を常に回す。現状の作業の方向性がポジティブなのかネガティブなのか気づくチェックポイントをワントライの中で数十箇所設けておくイメージ。
- 方向性が間違っているなら早い段階で軌道修正する。ゼロからすべてやり直す。ゼロからのやり直しは少なくとも最悪のシナリオではない。むしろ手戻りを最小限にとどめることができたことに両手を上げて喜ぶべき。
- 対象データセットの5%程度から学習を回す。どれだけ精度値が乱高下しても気にしてはならない。むしろ、精度値が乱高下するのが当たり前。気にすべきところは精度値の高低ではなくラベル量やそのバランス、trainセットとvalセットの画像セット内に含まれる高難易度画像の比率・低難易度画像の比率から、どのような実利用時の性能が出せるモデルになっているか
- 精度の数値は超参考値
- 細かく学習して生成した重みを使用して何度も推論テストを実施し、アノテーションをしながらモデルのウィークポイントを見つけることに集中する
- 明らかなウィークポイントを特定したら自撮りでもなんでもいいので弱点を補間するための画像セットを一定数必ず足す。50枚前後 で十分効果は出る。
- データセットの母数が大きすぎるとウィークポイント補間用画像セットの効果が相対的にとても小さくなってしまうので、大量の画像データセットを使えば性能が上がる、という固定観念は最初に完全に捨てること
- あらかじめ 3x3 の最小サイズのボックステンプレートを用意しておいてコピペしかしない
- CVATブラウザバージョンだけど
CTRL + CとCTRL + Vでボックスをコピペできる - 常に 3x3 のボックスをコピペしたあとに対象領域境界まで手動で引き伸ばしてアジャストしている



- 必ず画像の右下、あるいは画像の右上から徐々に左方向にアノテーションしてできるかぎり人力認識に漏れが生じないようにする
- 横方向のラスタスキャンをするイメージ

- 対象クラス間にある程度位置普遍性があるなら、上から下、右から左に流れるように処理できるクラスをまとめて処理する、とか(ブツブツ独り言を発話しながら作業して心地よい感じのリズムになるように)
- 肩→肩→肘→肘→膝→膝
- 手→手→足→足
- 目→目→鼻→口→耳→耳
- 作業粒度・分類粒度ができるだけ近いタスクにまとめて実施した例
- 全身(スーパークラス)で1周
- 頭部で1周
- 顔で1周
- 目・鼻・口・耳で1周
- 手で1周
- 足で1周
- 頭部向きで1周
- 性別で1周
- 世代で1周
- バイリニアに極小オブジェクトを引き伸ばして本来存在しない色情報を捏造してからアノテーションしているので、極小オブジェクトは本来モデルから見ると境界がほとんど見えていないはず
- したがって、極小オブジェクトの境界面はだいたい正しければ影響は無い、という想定
- 綺麗に境界を目視で識別できるならしっかりやるべき、できないならこだわる意味はあまりない、と考える

- アノテーションすべきかしないべきか迷うような特殊なパターンでの判断
- 目視で識別できるか、できないか、の判断基準以外の小難しい基準は考えない
- したがって、下図は半透明に透過してしまっているけど識別可能な範囲でアノテーションする

- 高強度のブラーが掛かった画像でも、目視でギリギリ識別可能な範囲ならば頑張って境界を決めてアノテーションする
- ただし、これはピクセル単位でどこに境界を置くべきか、のようなこだわりを持ちすぎてはいけないパターン
- モデル自体が普遍的な位置関係を少しでも重みとして保持している前提とするなら、ある程度の位置と大きさが正しく検出できていれば実運用においても許せる範囲の検出結果が出るはずだから
- アノテーションをしない、は許されないが、ある程度頑張って頭をひねりながら正解が分からないけどなんとかアノテーションする、は許す
- 人間が正解を言語化できるならちゃんとやる、言語化できないならモデルの学習過程での重みに頼る感覚、重みに頼るためにはザックリと正解の位置は与えておく必要がある
- 完全なる正解を人間が定義できるなら頑張るべき、そうでないなら無駄に頑張るべきではない

- モデルのアーキテクチャによって認識が得意な画像、不得意な画像は確実に存在する
- CNNはグレースケール画像が苦手、極小オブジェクトが得意、大量検出が得意、リスケールに強い
- Transformerはグレースケール画像も得意、極小オブジェクトが苦手、大量検出が苦手、リスケールに弱い
- データをしっかり作って複数のアーキテクチャ間で同一のデータセットを共用するなら、得意・不得意要素をまんべんなく散りばめたデータセットにすることが望ましい
- APの数値を上げるだけなら不得意パターンを含めないだけで簡単に数値は上げられるが、APを上げることが最終目的ではないはず
- mAP, AP の値にとらわれていては本質を見失う
- よく質問されがちなデータ量の観点
- 画像の合計枚数は指標としてあまり大きな意味はない
- なぜ画像の合計枚数にとらわれがちなのか
- データセット(画像セット)の中身をすべてチェックして傾向を把握する最重要にして必須の作業をしていないから、めんどくさいし泥臭すぎてやりたくないから、コスパ・タイパ重視だから、時間がとても掛かるしコストも掛かるから
- ヒストグラム分析などの統計的手法だけではなく、レアパターンやデータセットの全体的な傾向を把握することが重要
- 構図、対象オブジェクトの距離(サイズ)、ノイズパターン、明度、アスペクト比、1画像内の最大オブジェクト数、オクルージョンパターン、俯角・仰角パターン、回転、ひねり、など
- このあたりの全ての組み合わせを細かく指示して Sora でパターン生成できるようになると良いな、と思う
- 一例
- MS-COCO データセット: 約 200,000枚
- 80クラス分なのでナイーブに枚数が多くなるのは理解できる
- 自作データセット: 約 12,000枚
- 25クラス分、「人」のみの1ドメインに特化
- MS-COCO 4,000枚 + フォトメトリックノイズ付加/アスペクト比変更 4,000枚 + レアケース補強用他データセット 2,000枚 + 自撮り 2,000枚
- 僕が取り組んでいる人ドメインでのレアケースとは、車椅子、松葉杖、子供、女性
- 人種ごとの体格差により特に大人・子供の境界の定義がかなり難易度高めだった。そもそも文化的に大人・子供の定義が全く異なるうえに、アジア系は幼い容姿に見えがち、欧米系・アフリカ系は体格が良いので大人に見えがち
- 全体的にプロスポーツの画像比率が高く、選手・観客共に子供の比率がかなり低く偏っている。観客席はただでさえ映り込む人の数が大量なので、必然的にデータセット全体の属性が偏る
- MS-COCO データセット: 約 200,000枚
- よく質問されがちな作業分担の件
- ツライし天文学的な時間が溶けるのでできれば作業分担したい
- わかる、その気持ち
- 一人で全部やり切る場合
- 俺が、ルールだ。で終わり
- 自己責任
- なんとなく作業分担を考える
- PM・PL
- 予算
- スケジュール・納期
- ステークホルダーからの外圧をのらりくらりとかわしてプロジェクトメンバーを守る役割
- モデル設計者兼タスク設計者兼レビュアー
- 精神的にも体力的にも最もツラい
- 他人の雑な仕事をレビューするの、プログラムを読むのと同じでとてもストレスが掛かる
- レビューコストはアノテーションコストの3倍ぐらい高い感覚
- なぜなら、決めたルール通りに完ぺきに仕上がっているかを一片の狂いもなくチェックする必要があるから
- それすなわちアノテーションを一人で全部やり直すのと何ら変わらないことをしているのと同じ
- 意味がわからない
- アノテーター
- シンプルにツラい
- 人間がやることじゃない、と思わせるに値する単調作業
- それほどまでに単調な作業として成立するようにかなり細かくルール化してからお願いすべき
- 一方で、指示した細かいルールを全て意識しながらメンタル超人のように淡々とこなせる人はおそらく全人類の 0.000000001% ぐらいだと思う。
- 何故この単調作業が人類全体にとってとても有益な作業と成り得るか、みたいな、ある意味会社を起業するモチベーションに近いような社会貢献への意義や理想を高次のマインド部分で共感できるような人じゃないとモチベートできないはず
- それはきっと、アルバイトの方ではないしパートタイマーの方ではないと思う
- 単価は確実に超人単価でなければおかしい
- PM・PL
- 正直言って、コミュニケーションコストが無駄過ぎてお金も時間も一人でやるより5倍〜6倍は掛かる感覚
- はたして一人で全部やり切るのと、多くの人をアサインして作業分担してやるのと、どちらが現実的な話に聞こえるだろうか
- そもそも、アノテーションを作業分担しよう、という話の大前提条件であるアノテーターの体力、精神力、マインドセットの話を置き去りにしすぎ。無理
- よく質問されがちなデータの偏りの件
- 同時に学習するクラス間でのアノテーション量の偏り自体にはあまり意味が無い
- ラベル量は最低でも 3,000 個はあったほうがロバストなモデルになる
- 単純にラベル量を増やせば良いかというとそういうことではなく、前述の観点で様々な条件が組み合わさったラベルで量を確保するのが望ましい
- そもそもリアル環境下でサンプルを集めるのが大変
- 大前提の話として、どれだけ辛くてもサンプルを頑張って集める必要がある
- 以下、実際に実施しているアイデア
- ひとつの画像に対してフォトメトリックノイズを付加して最低でも1画像を2画像に増やす → 構図は完全に同じでノイズの入り具合だけが異なる画像を静的に生成しておく
- 作業対象ドメインによって生じうるノイズのパターンが異なるはずなのでそこはしっかり意識してどのノイズパターンを適用してもよいかをじっくり検討する
- 古典的アルゴリズムで付加したノイズが実利用環境下でほんとうに発生しうるノイズなのか、はじっくり検討する必要がある
- 例えば、対象オブジェクトのみが高速に移動していて強度のローカルモーションブラーが掛かっている状況と背景も一緒に高速に移動していてグローバルモーションブラーが掛かっている状況は異なる
- 生成AIで生成すれば良いじゃん
- やってみる
- Soraで生成したローカルモーションブラーをトレースした動画・画像サンプル、プロンプト「人が高速に走っていて高強度のローカルモーションブラーが掛かっている。」
- That's ゴミ
- 現状、生成AIで手を抜いて素材を集めるのは「私は」強くお勧めしない


- よく質問されがちな後継育成の件
- 全く興味が無い
- というより、僕と同じマインドセットで取り組める人はたぶん世界にもう一人ぐらい居るか居ないかなのでほぼ無理
- 同等の負荷を乗り越えられる体力と精神力を発揮できる前提であってほしくて、体力・精神力の強化面までフォローして育成するのは無駄にしか思えない
- 育成に時間を掛けている余裕があったら新たに50,000個アノテーションできそう
- 数多の地獄を経験して生き残ってきたソルジャーであってほしい
- 前提として、論文も書かないし、研究のように面白く新しい発見があるわけではない単調な作業なのでただしんどいだけ
- 99.998%ぐらいの人はtakerタイプなので自己犠牲呪文を唱える感じにはならないと思う。メガザルやメガンテを率先して連打できる人がはたしてどれぐらい居るのか
- 日本人の牧歌的な感覚とは間違いなく相性が悪い
- すべてを焼け野原にするほどの鬼気迫る気概が無いと成立しない気がする
- 今は、人を育てること以上に、そもそもしっかりコストを投じて必要なデータを集めることに集中したほうが良いと思ってる
- 上記のようなことを言っていると老害とバカにされるのはわかっているけど、本気、とはそういうものだと思う