高精度 Human-Instance-Segmentation (People-Instance-Segmentation, Person-Instance-Segmentation) の実装アイデア
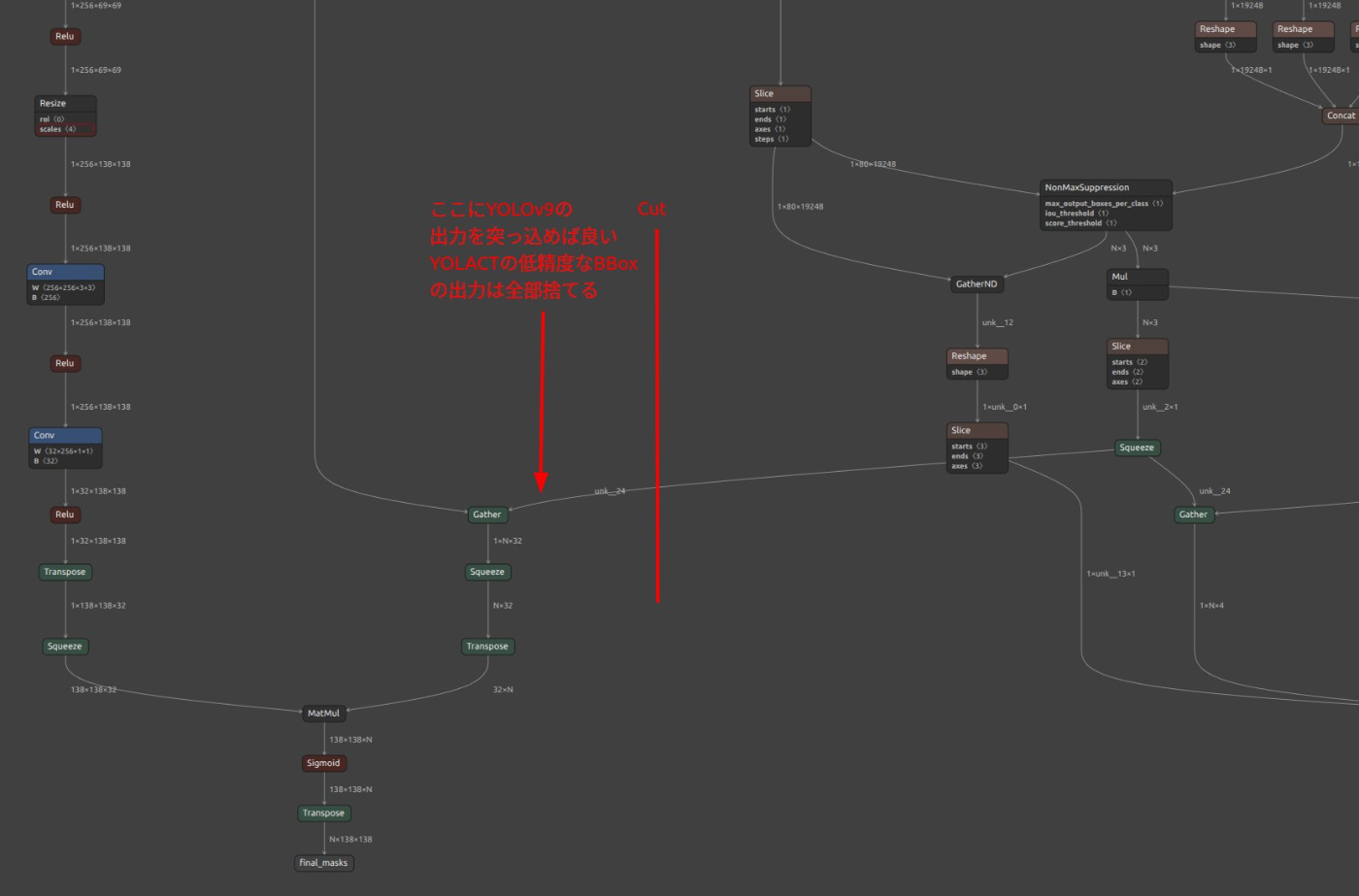
YOLACT-Edge を Person クラスのみで学習したあとに下図の部分でカットして YOLOv9 に合成すりゃいい。
mkdir -p images
mkdir -p annotations
7z x -o./images -bb1 train2017.zip
7z x -o./images -bb1 val2017.zip
rm val2017.zip train2017.zip
mv sama-coco-train.zip annotations/
mv sama-coco-val.zip annotations/
unzip -qqd . ./sama-coco-val.zip
unzip -qqd . ./sama-coco-train.zip
rm sama-coco-val.zip sama-coco-train.zip
MS-COCO の Train セットを 10,000枚 ずつ高速に解凍
ファイル一覧を 10,000 行ごとに分割し、そのリストを 7z x に渡すワンライナー/スクリプトを組み合わせます。以下では ファイル名の昇順 で 10,000 枚ずつ ./images00, ./images01, … に展開する手順を示します。
RAMディスクをマウント
# 24 GiB の RAM ディスクを /mnt/ram にマウント(sudo が必要)
sudo mkdir -p /mnt/ram
sudo mount -t tmpfs -o size=64G tmpfs /mnt/ram
#!/usr/bin/env bash
set -euo pipefail
# set -x # デバッグトレースは不要になったのでコメントアウト
# ファイルディスクリプタの制限を増やす (念のため残します)
ulimit -n 65536
ZIP=train2017.zip # 入力アーカイブ
CHUNK=10000 # 1 フォルダあたり枚数
PREFIX=images # 出力ディレクトリ接頭辞
TMPDIR=/mnt/ram/7z_tmp # RAM ディスク領域
mkdir -p "$TMPDIR"
echo "[1] build list..."
LC_ALL=C 7z l -slt "$ZIP" |
awk -F'= ' '/^Path = / && /\.jpg$/{print $2}' |
sort > "$TMPDIR/all.txt"
total_images=$(wc -l < "$TMPDIR/all.txt")
echo "DEBUG: ZIPファイルから抽出された画像の総数: $total_images 枚"
split -l "$CHUNK" -d -a 3 "$TMPDIR/all.txt" "$TMPDIR/list_"
chunks=$(ls "$TMPDIR"/list_* | wc -l)
echo "[2] $chunks 個のチャンクに分割されました (CHUNKサイズ: $CHUNK)"
n=0
for lst in "$TMPDIR"/list_*; do
idx=$(printf '%02d' "$n")
ram="/mnt/ram/extract$idx"
out="${PREFIX}${idx}"
echo "--- チャンク $idx の処理を開始します (リストファイル: $lst) ---"
echo "[3] chunk $idx → RAM"
mkdir -p "$ram" "$out" # mkdir -p を元に戻す
#### 7-Zip(スイッチ→ZIP→@listfile の順!)####
echo "DEBUG: 7z コマンドを実行中: 7z x -bb0 -aos -o\"$ram\" \"$ZIP\" @\"$lst\""
7z x -bb0 -aos -o"$ram" "$ZIP" @"$lst"
code=$?
echo "DEBUG: 7z の終了コード: $code"
if (( code > 1 )); then
echo "エラー: チャンク $idx で 7z エラーが発生しました。終了コード: $code"
exit $code
fi
#### rsync → 実ディスク ####
echo "DEBUG: rsync コマンドを実行中: rsync -a --info=progress2 \"$ram\"/ \"$out\"/"
rsync -a --info=progress2 "$ram"/ "$out"/
rsync_code=$?
echo "DEBUG: rsync の終了コード: $rsync_code"
case $rsync_code in
0|23|24)
;;
*)
echo "致命的なエラー: チャンク $idx で rsync エラーが発生しました。終了コード: $rsync_code"
exit 3
;;
esac
echo "DEBUG: rsync 後の処理に進みます。"
rm -rf "$ram"
echo "DEBUG: rm -rf \"$ram\" 完了。"
echo "DEBUG: n の値 (インクリメント前): $n"
n=$((n+1))
echo "DEBUG: n の値 (インクリメント後): $n"
echo "--- チャンク $idx の処理が完了しました ---"
echo "DEBUG: 次のチャンク処理へ移行します。"
done
echo "[DONE] $n folders (images00 … images$(printf '%02d' $((n-1))))"
RAMディスクをアンマウント
sudo umount /mnt/ram
sudo rm -rf /mnt/ram
imagesXX フォルダを個別の imagesXX.tar.gz にアーカイブし、その後それら全てを trainval2017.tar.gz にまとめるスクリプト
#!/usr/bin/env bash
set -euo pipefail
# 個別のimagesXX.tar.gzを作成
for i in $(seq -w 00 11); do
FOLDER="images${i}"
ARCHIVE="${FOLDER}.tar.gz"
echo "Archiving ${FOLDER} to ${ARCHIVE}"
tar -czf "${ARCHIVE}" "${FOLDER}"
done
# 全てのimagesXX.tar.gzをtrain2017.tar.gzにまとめる
echo "Archiving all imagesXX.tar.gz to train2017.tar.gz"
tar -czf train2017.tar.gz images*.tar.gz
echo "Archiving complete."
sudo apt update
sudo apt install gh
gh auth login
git clone https://github.com/PINTO0309/human-instance-segmentation.git && cd human-instance-segmentation
git clone https://github.com/PINTO0309/human-edge-detection.git&& cd human-edge-detection
pip install numpy==1.26.4 opencv-python==4.11.0.86 onnx==1.14.0 Pillow==10.0.0 matplotlib==3.7.0 pycocotools==2.0.7 tqdm==4.65.0 einops==0.7.0 tensorboard==2.14.0 onnxsim==0.4.30 onnxruntime-gpu==1.22.0 gdown==5.2.0 pandas==2.3.1 seaborn==0.13.2 pyyaml==6.0.2 scipy==1.15.3 segmentation-models-pytorch==0.5.0 albumentations==2.0.8 gdown==5.2.0
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv --python 3.10
source .venv/bin/activate
uv sync
cd data/annotations
wget https://xxx/instances_val2017_person_only_no_crowd.json
wget https://xxx/instances_train2017_person_only_no_crowd.json
cd ..
cd images
wget https://xxx/val2017_person_only_no_crowd.tar.gz
wget https://xxx/train2017_person_only_no_crowd.tar.gz
cd ..
tar -zxvf val2017_person_only_no_crowd.tar.gz
rm val2017_person_only_no_crowd.tar.gz
tar -zxvf train2017_person_only_no_crowd.tar.gz
rm train2017_person_only_no_crowd.tar.gz
tar -zxvf images01.tar.gz
tar -zxvf images02.tar.gz
tar -zxvf images03.tar.gz
tar -zxvf images04.tar.gz
tar -zxvf images05.tar.gz
tar -zxvf images06.tar.gz
mkdir train2017
mv images01/* train2017/
mv images02/* train2017/
mv images03/* train2017/
mv images04/* train2017/
mv images05/* train2017/
mv images06/* train2017/
rm -rf images*
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/ubuntu/human-edge-detection/.venv/lib/python3.10/site-packages/tensorrt_libs
Custom Variant
Custom Variant
uv run python train.py \
--model_variant nano \
--num_epochs 50 \
--use_focal_loss \
--focal_alpha 0.5 \
--focal_gamma 3.0 \
--learning_rate 0.002
uv run python train.py \
--model_variant nano \
--num_epochs 50 \
--use_focal_loss \
--focal_alpha 0.8 \
--focal_gamma 4.0 \
--learning_rate 0.003
uv run python train.py \
--model_variant nano \
--num_epochs 50 \
--use_focal_loss \
--focal_alpha 0.95 \
--focal_gamma 5.0 \
--learning_rate 0.006
uv run python train.py \
--model_variant nano \
--use_focal_loss \
--focal_alpha 0.3 \
--focal_gamma 2.0 \
--learning_rate 0.001
uv run python train.py \
--model_variant base \
--use_focal_loss \
--focal_alpha 0.3 \
--focal_gamma 2.0 \
--learning_rate 0.001
---
uv run python train.py \
--model_variant base \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_100.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--use_focal_loss \
--focal_alpha 0.3 \
--focal_gamma 2.0 \
--learning_rate 0.001
uv run python train.py \
--model_variant base \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_100.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--use_focal_loss \
--focal_alpha 0.6 \
--focal_gamma 2.0 \
--learning_rate 0.001
uv run python train.py \
--model_variant base \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--use_focal_loss \
--focal_alpha 0.3 \
--focal_gamma 2.0 \
--learning_rate 0.001
uv run python train.py \
--model_variant base \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--use_focal_loss \
--focal_alpha 0.75 \
--focal_gamma 2.0 \
--learning_rate 0.002 \
--warmup_epochs 5 \
--batch_size 8 \
--num_epochs 50 \
--disable_heavy_augmentation
uv run python train.py \
--model_variant base \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--use_focal_loss \
--focal_alpha 0.75 \
--focal_gamma 2.0 \
--learning_rate 0.002 \
--batch_size 8 \
--num_epochs 50 \
--disable_heavy_augmentation
uv run python train.py \
--model_variant base \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--use_focal_loss \
--focal_alpha 0.75 \
--focal_gamma 2.0 \
--learning_rate 0.002 \
--batch_size 4 \
--num_epochs 50 \
--disable_heavy_augmentation
uv run python train.py \
--model_variant base \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--learning_rate 0.002 \
--batch_size 4 \
--num_epochs 50 \
--disable_heavy_augmentation
uv run python train.py \
--model_variant base \
--train_ann data/annotations/instances_train2017_person_only_no_crowd.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd.json \
--learning_rate 0.003 \
--batch_size 4 \
--num_epochs 50
---
オプション2: Warmup付きの段階的学習
uv run python train.py \
--model_variant base \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--use_focal_loss \
--focal_alpha 0.2 \
--focal_gamma 1.5 \
--learning_rate 0.002 \
--warmup_epochs 10 \
--lr_scheduler cosine \
--min_lr 0.0001 \
--batch_size 8 \
--num_epochs 50
---
オプション4: 2段階アプローチ(推奨)
# ステージ1: 基礎学習(Focal Lossなし)
uv run python train.py \
--model_variant base \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--pos_weight 10 \
--learning_rate 0.002 \
--lr_scheduler none \
--batch_size 8 \
--num_epochs 10
# ステージ2: Focal Lossで精度向上
uv run python train.py \
--resume checkpoints/checkpoint_epoch_10_base_640x640_00463.pth \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--use_focal_loss \
--focal_alpha 0.2 \
--focal_gamma 1.2 \
--learning_rate 0.001 \
--additional_epochs 40
Custom + BCE Loss
Custom + BCE Loss
############ Small
uv run python train.py \
--model_variant base \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--learning_rate 0.001 \
--batch_size 4 \
--num_epochs 50 \
--disable_heavy_augmentation
Pretrained + BCE Loss
Pretrained + BCE Loss
############ Small
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--backbone mobilenetv2 \
--use_pretrained \
--staged_unfreeze \
--staged_unfreeze_interval 3 \
--batch_size 4 \
--num_workers 4 \
--num_epochs 100
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--backbone mixnet_s \
--use_pretrained \
--staged_unfreeze \
--staged_unfreeze_interval 3 \
--batch_size 4 \
--num_workers 4 \
--num_epochs 100
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--backbone resnet18 \
--use_pretrained \
--staged_unfreeze \
--staged_unfreeze_interval 3 \
--batch_size 2 \
--num_workers 2 \
--num_epochs 100
############ Full
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd.json \
--backbone mobilenetv2 \
--use_pretrained \
--batch_size 8 \
--num_workers 8 \
--staged_unfreeze \
--staged_unfreeze_interval 3 \
--num_epochs 1000
sudo mount -o remount,size=250G /dev/shm
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd.json \
--backbone mobilenetv2 \
--use_pretrained \
--batch_size 45 \
--num_workers 45 \
--staged_unfreeze \
--staged_unfreeze_interval 3 \
--num_epochs 1000
==================================
##### 0 - 70 epoch
##### loss=1.0690, bce=0.5865, dice=0.4436, ovlp=0.0389, lr=0.000952
sudo mount -o remount,size=250G /dev/shm
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd.json \
--backbone mixnet_s \
--use_pretrained \
--batch_size 45 \
--num_workers 45 \
--diversity_weight 0.0 \
--instance_aware_weight 0.0 \
--overlap_penalty_weight 0.5 \
--freeze_backbone_epochs 5 \
--staged_unfreeze \
--staged_unfreeze_interval 3 \
--num_epochs 500
##### 71 epoch -
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd.json \
--resume checkpoints/checkpoint_epoch_70_mixnet_s_640x640_00545.pth \
--backbone mixnet_s \
--use_pretrained \
--batch_size 45 \
--num_workers 45 \
--learning_rate 0.000952 \
--diversity_weight 0.0 \
--instance_aware_weight 0.0 \
--overlap_penalty_weight 0.5 \
--freeze_backbone_epochs 0 \
--num_epochs 500 \
--disable_heavy_augmentation
=============================
sudo mount -o remount,size=250G /dev/shm
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd.json \
--backbone mixnet_s \
--use_pretrained \
--batch_size 16 \
--num_workers 16 \
--diversity_weight 0.0 \
--instance_aware_weight 0.0 \
--overlap_penalty_weight 0.8 \
--freeze_backbone_epochs 5 \
--staged_unfreeze \
--staged_unfreeze_interval 3 \
--dropout 0.2 \
--batch_size 16 \
--weight_decay 0.001 \
--num_epochs 500 \
--disable_heavy_augmentation
=============================
sudo mount -o remount,size=250G /dev/shm
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd.json \
--backbone mixnet_s \
--use_pretrained \
--batch_size 45 \
--num_workers 45 \
--diversity_weight 0.0 \
--instance_aware_weight 0.0 \
--overlap_penalty_weight 0.5 \
--use_instance_relation \
--relation_loss_weight 0.2 \
--dropout 0.0 \
--freeze_backbone_epochs 5 \
--staged_unfreeze \
--staged_unfreeze_interval 3 \
--num_epochs 500 \
--disable_heavy_augmentation
sudo mount -o remount,size=250G /dev/shm
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--backbone mixnet_s \
--use_pretrained \
--batch_size 45 \
--num_workers 45 \
--diversity_weight 0.0 \
--instance_aware_weight 0.0 \
--overlap_penalty_weight 0.5 \
--use_instance_relation \
--relation_loss_weight 0.2 \
--dropout 0.0 \
--freeze_backbone_epochs 5 \
--staged_unfreeze \
--staged_unfreeze_interval 3 \
--num_epochs 500 \
--disable_heavy_augmentation
sudo mount -o remount,size=250G /dev/shm
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd.json \
--backbone mixnet_s \
--use_pretrained \
--batch_size 45 \
--num_workers 45 \
--learning_rate 0.0005 \
--diversity_weight 0.0 \
--instance_aware_weight 0.0 \
--overlap_penalty_weight 0.5 \
--use_instance_relation \
--relation_loss_weight 0.05 \
--dropout 0.0 \
--freeze_backbone_epochs 0 \
--num_epochs 200 \
--save_frequency 1 \
--disable_heavy_augmentation
yolo_fusion
sudo mount -o remount,size=250G /dev/shm
uv pip install onnxruntime-gpu
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd_500.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd_100.json \
--backbone mixnet_s \
--use_pretrained \
--use_yolo_features \
--yolo_fusion_mode attention \
--batch_size 16 \
--num_workers 16 \
--diversity_weight 0.0 \
--instance_aware_weight 0.0 \
--overlap_penalty_weight 0.5 \
--dropout 0.0 \
--freeze_backbone_epochs 0 \
--num_epochs 50 \
--save_frequency 1 \
--disable_heavy_augmentation
uv run python train_pretrained.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd.json \
--backbone mixnet_s \
--use_pretrained \
--use_yolo_features \
--yolo_fusion_mode attention \
--batch_size 16 \
--num_workers 16 \
--diversity_weight 0.0 \
--instance_aware_weight 0.0 \
--overlap_penalty_weight 0.5 \
--dropout 0.0 \
--freeze_backbone_epochs 0 \
--num_epochs 50 \
--save_frequency 1 \
--disable_heavy_augmentation
python inference.py \
--folder test \
--ann_file data/annotations/instances_train2017_person_only_no_crowd.json \
--output_dir out \
--checkpoint checkpoints/checkpoint_epoch_0010_mixnet_s_640x640_01943.pth \
--use_auxiliary \
--apply_refinement
- YOLO
入力: 1x3x640x640 RGB image -> YOLO
出力: /model.34/Concat_output_0 1x1024x80×80 の特徴マップ - 境界検出モデル
入力: /model.34/Concat_output_0 1x1024x80×80 の特徴マップ
正解ラベル: 640x640 ではないCOCOフォーマットから抽出したインスタンスごとのセグメンテーション境界
出力: 640x640 のサイズの境界線確率のマップ - 出力
3クラスとし、0:背景、1: 推定対象マスク、2: 推定対象外マスク、の3クラスにして、教師ROI(バウンディングボックス)の内側に含まれる教師マスクには推定対象とするマスクと推定対象外のマスクを両方含めるようにすることでアテンションが効きやすい状況を作る。
以下では Binary Cross Entropy (BCE) Loss と (Categorical) Cross Entropy (CE) Loss の違いを、用途・数式・モデル出力形状・よくある実装パターンの観点から整理します。
整理
1. 用語の整理
- Binary Cross Entropy (BCE): 各出力が「独立した二値 (0/1)」ラベルを持つとみなす損失。1出力=1つの Bernoulli 事象。複数出力の場合は「マルチラベル分類」(各ラベルが独立に 0/1 を取る)。
- (Categorical) Cross Entropy (CE): 複数クラスの「排他的」分類(1サンプルにつきちょうど1クラス)を前提とし、出力は「全クラスに対する確率分布(合計1)」として扱う。
2. 数式
Binary Cross Entropy (単一ラベル)
ロジット
複数ラベル(クラス数
Cross Entropy (多クラス排他)
ロジットベクトル
ラベルを one-hot ベクトル
3. ラベル依存関係の違い
| 項目 | BCE | CE |
|---|---|---|
| ラベル関係 | 各ラベルは独立(0/1) | 全クラス排他・1つだけ正解 |
| 出力活性化 | シグモイド(各ユニット独立確率) | ソフトマックス(総和=1の分布) |
| 想定タスク | 二値分類 / マルチラベル分類 | 多クラス分類(排他) |
4. 出力テンソル形状(PyTorch想定)
| タスク | 推奨Loss | モデル出力 | 正解ラベル形式 |
|---|---|---|---|
| 二値分類 (1出力) | BCEWithLogitsLoss |
[N] または [N,1] ロジット |
[N] 0/1 float |
| 二値分類 (2ロジット方式) | CrossEntropyLoss |
[N,2] ロジット |
[N] クラスID (0 or 1) |
| マルチクラス排他 (C>2) | CrossEntropyLoss |
[N,C] ロジット |
[N] クラスID (int) |
| マルチラベル (Cラベル独立) | BCEWithLogitsLoss |
[N,C] ロジット |
[N,C] 0/1 float |
5. 二値分類で BCE と CE(2クラス)のどちらを使う?
理論的にはどちらでも可。
2クラス分類を
- 1ロジット+シグモイド+BCE(軽量・自然)
- 2ロジット+ソフトマックス+CE(フレームワーク標準多クラス API をそのまま利用)
で実装できる。
数学的には、2ロジット版 CE は 1ロジット版ロジスティック回帰と等価(ロジット差のみが効く)ですが、実装やクラス重み付けの仕方が多少異なります。
6. マルチラベル vs マルチクラス
| シナリオ | 例 | 選ぶLoss |
|---|---|---|
| 写真に「犬」「猫」「人」が同時に写り得る | 各ラベル独立 ON/OFF | BCE (BCEWithLogitsLoss) |
| 画像は「犬」「猫」「鳥」のいずれか1種 | 排他的クラス分類 | CE (CrossEntropyLoss) |
7. 数値安定性と実装注意
BCE 系
- 実装は原則
BCEWithLogitsLossを使い、モデル出力はロジット(シグモイド前) にする。これが数値安定(log-sum-exp trick内蔵)。 - 既にシグモイドした確率を渡すなら
BCELoss(非推奨気味、数値不安定になりがち)。
CE 系
-
CrossEntropyLossは softmax + NLLLoss を内部でまとめて実装しているので、モデルからはロジットをそのまま渡す(softmaxを事前にかけない)。 - ラベルはクラスインデックス(int)で渡すのが基本(one-hot を渡すなら
log_softmax+nll_lossまたは KLDiv など別ルート)。
8. クラス不均衡への対応
| Loss | 重み付け手段 | メモ |
|---|---|---|
BCEWithLogitsLoss |
pos_weight(正例強調)、weight(要素別) |
マルチラベルで正例の希少性調整に有効 |
CrossEntropyLoss |
weight(クラス別スカラー) |
バランス不良データでクラス重み |
不均衡が極端なら BCE + focal loss 変種、CE + focal loss (γ, α) なども検討。
9. ミニコード例
二値 (1ロジット) BCEWithLogitsLoss
logits = model(x) # shape [N] or [N,1]
targets = y.float() # shape [N]
loss_fn = torch.nn.BCEWithLogitsLoss()
loss = loss_fn(logits.squeeze(), targets)
マルチクラス CE
logits = model(x) # shape [N, C]
targets = y.long() # shape [N], 各要素 0..C-1
loss_fn = torch.nn.CrossEntropyLoss()
loss = loss_fn(logits, targets)
マルチラベル BCEWithLogitsLoss
logits = model(x) # shape [N, C]
targets = y.float() # shape [N, C], 0/1
loss_fn = torch.nn.BCEWithLogitsLoss()
loss = loss_fn(logits, targets)
10. よくある間違い
- softmax後を CrossEntropyLoss に渡す → ダメ(2重で softmax し非数値安定)。
- sigmoid後を BCEWithLogitsLoss に渡す → ダメ(内部で再度シグモイド計算前提)。
- マルチラベル問題を
CrossEntropyLossで扱う(排他前提と矛盾)。 - ターゲット型を int/float 逆にする。
11. まとめ(超短縮)
-
排他的クラス分類 →
CrossEntropyLoss(softmax前のロジットを渡す)。 -
独立した複数ラベル (0/1) → マルチラベル →
BCEWithLogitsLoss(シグモイド前ロジット)。 -
2クラス問題 はどちらでも可だが、1ロジット+
BCEWithLogitsLossがシンプル。
3クラスとし、0:背景、1: 推定対象マスク、2: 推定対象外マスク、の3クラスにして、教師ROI(バウンディングボックス)の内側に含まれる教師マスクには推定対象とするマスクと推定対象外のマスクを両方含めるようにすることでアテンションが効きやすい状況を作る。
教師入力1:YOLOの中間層から抽出した特徴マップ 1x1024x80×80
教師入力2:インスタンスセグメンテーションの推定領域を示す ROI 領域の正規化座標 X1, Y1, X2, Y2 あるいは cx, cy, w, h
教師入力3:インスタンスセグメンテーションの推定対象マスクと推定対象外マスク含む正解マスク(推定対象マスクと推定対象外マスクのみアノテーションされており、この2つ以外の領域は全て背景とする)
このようなアイデアでインスタンスセグメンテーションのデコーダー部分のみを3クラスのインスタンスセグメンテーションタスクと定義した場合、どのようなモデル設計およびLoss設計が考えられるか。
以下に、「YOLO中間特徴 + ROI座標 + 3クラス(背景/推定対象/推定対象外)マスク」構成でインスタンスセグメンテーション用デコーダを学習するモデル設計と Loss 設計の選択肢を整理します。
「推定対象外」クラスを ROI 内で明示的に教えることで、対象と非対象を対比的に学習させ、注意(アテンション)誘導・誤検出抑制・マスク境界の洗練を狙う設計方針です。
設計
0. 前提再確認(あなたの設計意図)
-
入力画像は 640×640(例)。YOLO 中間層特徴:
[B, 1024, 80, 80](stride=8換算)。 -
教師 ROI: 正規化 (x1,y1,x2,y2) または (cx,cy,w,h)。
-
教師マスク: ROI 内に
1: 推定対象マスク (positive instance)-
2: 推定対象外マスク (distractor / ignore-target)
ROI 外および未アノテーション領域は0: 背景。
-
YOLO 本体は凍結。デコーダのみ学習。
1. ラベル表現とテンソル整形
1.1 解像度整合
- 元マスク (640×640) を stride=8 でダウンサンプル → 80×80 の教師ラベル(学習安定&速い)。
- もしくはデコーダは ROI 域のみ高解像度アップサンプリングしてフル 640×640 出力。
1.2 3クラス one-hot / index
- PyTorch なら
CrossEntropyLossに整数クラスIDマップ[B, H, W]を渡せばOK(logitsは[B,3,H,W])。 - 「推定対象外」クラスを厳密にラベル付けできない領域(境界不確実、未アノテーション)には ignore_index を設定する選択肢もあり。
2. ROI 情報のモデルへの渡し方(重要)
ROI をどう「条件」として渡すかで性能が大きく変わります。代表的に以下。
| 方針 | 説明 | 長所 | 短所 |
|---|---|---|---|
| A: ROI Crop Head (Mask R-CNN風) | 特徴マップから ROIAlign → 小パッチ (e.g., 14×14) → Conv stack → Upsample → 3ch mask | 計算軽い/ROI依存明確 | ROI外コンテキスト喪失。複数ROIバッチ処理要 |
| B: ROI Positional Encoding Broadcast | ROIを 80×80 上にブロードキャスト(距離, inside-flag, norm coords等)→ 特徴にconcat | 全体文脈維持/単一forwardで複数ROI可 (マスク畳み込みで繰返し) | 入力ch増加/学習に工夫必要 |
| C: Dynamic Filter (CondInst系) | ROIから埋め込みベクトル→動的畳み込みフィルタ生成→特徴へ適用→マスク | 多インスタンス拡張性/柔軟 | 実装やデバッグ難 |
まずは A(ROIAlign型)が実装コストと安定性のバランス◎。
3. モデルブロック例(A: ROIAlign型の最小構成)
YOLO frozen backbone/head ─┐
├─> F ∈ ℝ[B,1024,80,80]
ROI boxes (in image coords) ┘
For each ROI:
1. Scale ROI to feature coords:
fx1 = x1 / stride, fx2 = x2 / stride, etc.
2. ROIAlign(F, ROI) -> R ∈ ℝ[B_roi, 1024, h_r, w_r] (e.g., 14×14)
3. Small ConvNet:
Conv(1024→256) + GN/BN + ReLU
Conv(256→256) × n
Upsample progressive to fixed high-res (e.g., 56×56 or 112×112)
4. Final 3-ch Conv → logits_3
5. (Optional) Paste back into image canvas at ROI loc; else compare to cropped GT mask resized to same ROI resolution.
4. 教師マスクの ROI 切り出し
2通り:
(a) ROI内クロップ学習(推奨第一歩)
- GTマスクを ROI でクロップし、ROI座標で正規化リスケール(学習ヘッド出力と同サイズ)。
- Loss は ROI内のみ計算(pixel数少なく高速/ROI中心学習)。
(b) フルイメージ出力 + ROI重み付け
- デコーダがフル 80×80(または640×640)マップを出力。
- Lossは全域計算だが、ROI内画素の重み↑、ROI外は軽く(もしくは背景のみ supervise)。
- ROI外まで対象外クラスを引きずりたくない場合に。
5. Loss 設計オプション
以下を組み合わせる形で設計します。
5.1 ベース損失(必須)
3クラス排他 → CrossEntropyLoss。
-
weight=[w_bg, w_pos, w_neg]でクラス不均衡補正。 - ROI内画素が少ない場合、
w_pos/w_negを上げる。
5.2 Dice(またはSoftDice/Tversky)補助
- 特に pos(=1) マスク境界が重要なら CE + Dice(pos)。
- distractor(=2) の描写精度も欲しければ class-wise Dice を両方に適用。
- 係数例:
Loss = λ_ce * CE + λ_dice_pos * Dice_pos + λ_dice_neg * Dice_neg.
5.3 Boundary / Contour Loss(任意)
- マスク境界をラペシアンや距離変換で細線化し、BCEまたは L1 で境界整合性を促す。
- 特に「推定対象外」を境界沿いサンプルとして使う設計も可(positives at edges)。
5.4 Contrastive / Margin 的拡張(高度)
ROI内で「pos vs neg」特徴埋め込みを距離分離する(pixel embedding or region embedding)。
- Pixel-level embedding networkから pos/neg センター距離を分離 (InfoNCE, Triplet)。
- 主損失とは別の補助 head として追加。
5.5 Focal化(不均衡強い場合)
CEをFocalCE化(γ>0)。または pos/neg 画素のみ focal。
例:FocalCE(logits, target, gamma=2, alpha_classwise)。
6. クラス重み設計の実務フロー
- データ統計: ROIクロップマスク内で各クラス画素数を集計。
- 逆頻度重み:
w_c = 1 / (freq_c + ε)正規化。 - 上限クリップ(極端不安定回避)。
- ログスケーリング(
w_c = log(K/freq_c))でマイルド化。
7. 実装スケッチ(ROIクロップ学習 + CE+Dice)
class RoiSegHead(nn.Module):
def __init__(self, in_ch=1024, mid_ch=256, num_classes=3, out_size=56):
super().__init__()
self.block = nn.Sequential(
nn.Conv2d(in_ch, mid_ch, 3, padding=1),
nn.GroupNorm(32, mid_ch),
nn.ReLU(inplace=True),
nn.Conv2d(mid_ch, mid_ch, 3, padding=1),
nn.GroupNorm(32, mid_ch),
nn.ReLU(inplace=True),
)
self.upsample = nn.Sequential(
nn.Upsample(size=(out_size, out_size), mode='bilinear', align_corners=False),
nn.Conv2d(mid_ch, mid_ch, 3, padding=1),
nn.ReLU(inplace=True),
)
self.classifier = nn.Conv2d(mid_ch, num_classes, 1)
def forward(self, feats_roi):
x = self.block(feats_roi)
x = self.upsample(x)
return self.classifier(x) # [B_roi,3,out_size,out_size]
Loss 部分
def ce_dice_loss(logits, target, class_weights=None, dice_classes=(1,)):
# logits: [B,3,H,W], target: [B,H,W] int
ce = F.cross_entropy(logits, target, weight=class_weights, reduction='mean')
# Dice for selected classes only (e.g., pos=1, neg=2)
dice_total = 0.0
for c in dice_classes:
# one-hot slice
tgt_c = (target == c).float()
prob_c = F.softmax(logits, dim=1)[:, c, ...]
inter = (prob_c * tgt_c).sum()
denom = prob_c.sum() + tgt_c.sum() + 1e-6
dice = 1 - (2 * inter / denom)
dice_total = dice_total + dice
dice_total = dice_total / max(len(dice_classes), 1)
return ce + dice_total
8. ROI 情報を特徴に注入する改良(Bプラン)
ROI を単に切り出すのではなく、**「YOLO特徴全体 + ROIマップをチャネル追加」**でコンテキストを生かす方法:
生成する補助チャネル例(80×80):
- binary mask: inside ROI=1, else 0
- 距離到中心: 正規化 (dx, dy)
- スケール: ROI幅/高さを全ピクセルにブロードキャスト
- relative coords: ( (x - cx)/w, (y - cy)/h )
これらを concat → [B,1024+K,80,80] → U-Net風デコーダ → 3ch logits。
ROI依存の空間注意が自然に学習される。
9. 推定対象外(クラス2)の使いどころ
推定対象外は単なる「背景の一部」とせず、**「ROI内の競合インスタンス」「ノイズ」「似たパターン」**を明示教師する点に価値があります。
期待効果:
- 誤った大域領域膨張を抑止(posとnegを分離)。
- ROI中心へのアテンション強化(特に複数物体密集時)。
- 後段で pos のみ抜き出したいとき信頼度向上。
10. 学習バッチ構成の注意
| 設定 | 推奨 |
|---|---|
| ROI サンプリング | 各画像から K 個(正例GT box, hard負例, IoU thresholdで混ぜる) |
| Hard Negative Mining | 推定対象外が多いROIを優先サンプリング |
| Data Aug | ROI jitter / scale jitter / random crop to encourageロバスト性 |
11. 推論フロー例(ROI提供前提)
- 画像入力 → YOLO推論(凍結)→ bbox提案 (または外部ROI)。
- 中間特徴取り出し。
- 各 ROI についてデコーダ forward → 3chマスク (ROI解像度)。
- posチャンネル確率マップを select(必要ならnegも利用して信頼度再計算)。
- 画像座標に戻して貼り付け/閾値化/ポリゴン化。
12. アブレーション(やると効果検証が早い)
| 実験 | 比較目的 |
|---|---|
| 2クラス (背景/推定対象) vs 3クラス | neg導入効果 |
| ROIクロップ vs 全体+ROIチャネル | コンテキスト重要度 |
| CEのみ vs CE+Dice vs CE+Dice+Boundary | 境界精度と安定性 |
| クラス重みあり/なし | 不均衡耐性 |
13. 最小ステップで始める推奨構成(実装優先)
- ROIAlign型クロップヘッド(A)。
- 出力 56×56(高速・十分)。
- CrossEntropyLoss(weighted) + Dice(pos)。
- Distractor クラスは CE のみ(初期はDice対象外)で学習安定化。
- 学習収束後、Diceをnegにも拡張、Boundary loss追加で精緻化。
14. クイック疑似コード(学習ループ断片)
# feats: [B,1024,80,80] from YOLO (frozen)
# rois: [R,5] (batch_idx, x1,y1,x2,y2 in image px)
# gt_masks_full: list of [H,W] int masks per image (0/1/2)
roi_feats = roi_align(feats, rois, output_size=(14,14), spatial_scale=1/stride)
# build roi-level gt targets
roi_targets = []
for (b,x1,y1,x2,y2) in rois:
gt = gt_masks_full[b][y1:y2, x1:x2]
gt = resize(gt, (56,56), interp='nearest')
roi_targets.append(torch.from_numpy(gt))
roi_targets = torch.stack(roi_targets).to(device) # [R,56,56]
logits = seg_head(roi_feats) # [R,3,56,56]
loss = ce_dice_loss(logits, roi_targets, class_weights=torch.tensor([w0,w1,w2]).to(device))
loss.backward()
15. 追加検討ポイント
- 複数インスタンス重複時:ROI作成前に NMS 後の bboxで巡回/マスク合成順序。
- 半教師/弱教師:推定対象外が未アノテーションの時は ignore_index にして誤監視抑制。
- マルチスケール特徴:1024@80×80 に加え、別段階 (e.g., 512@40×40) を FPN的に融合しても良い。
まとめ(超短)
- ROI条件付き 3クラスセグヘッドで「対象 vs 非対象」を対比学習 → アテンション誘導。
- 実装の出発点は ROIAlign → 小型デコーダ → 3ch CE(重み付け) + Dice(pos)。
- 発展で neg活用, ROIブロードキャスト, Boundary/Contrastive補助Loss。
必要なら、実コード雛形(PyTorch版)、クラス重み自動計算スクリプト、ROI特徴切り出し関数、学習ループテンプレート などを提示できます。どこから進めますか?
uv run python main.py \
--train_ann data/annotations/instances_train2017_person_only_no_crowd.json \
--val_ann data/annotations/instances_val2017_person_only_no_crowd.json \
--data_stats data_analyze_full.json \
--epochs 100 \
--batch_size 32 \
--lr 1e-3 \
--optimizer adamw \
--weight_decay 1e-4 \
--scheduler cosine \
--min_lr 1e-6 \
--gradient_clip 5.0 \
--num_workers 16 \
--validate_every 1 \
--save_every 1
experiment multiscale distance_loss cascade best_miou best_epoch
multiscale_distance True True False 0.462614 6
variable_roi_hires True True False 0.476987 8
variable_roi_progressive1 True True False 0.476360 4
variable_roi_progressive_focal True True False 0.468136 7
hierarchical_segmentation True False False 0.465206 14
hierarchical_segmentation_unet True False False 0.466997 6
class_specific_decoder True False False 0.473900 8
uv run python run_experiments.py \
--configs multiscale_distance \
--epochs 100 \
--batch_size 32
uv run python run_experiments.py \
--configs variable_roi_hires \
--epochs 100 \
--batch_size 32
uv run python run_experiments.py \
--configs variable_roi_progressive1 \
--epochs 100 \
--batch_size 32
uv run python run_experiments.py \
--configs variable_roi_progressive_focal \
--epochs 100 \
--batch_size 32
### 学習中
uv run python run_experiments.py \
--configs hierarchical_segmentation \
--epochs 100 \
--batch_size 32
### 学習中
uv run python run_experiments.py \
--configs hierarchical_segmentation_unet \
--epochs 100 \
--batch_size 32
### 学習中
uv run python run_experiments.py \
--configs hierarchical_segmentation_unet_v2 \
--epochs 100 \
--batch_size 32
uv run python run_experiments.py \
--configs hierarchical_segmentation_unet_v2_warm_restarts \
--epochs 150 \
--batch_size 32
uv run python run_experiments.py \
--configs hierarchical_segmentation_unet_v3 \
--epochs 100 \
--batch_size 32
uv run python run_experiments.py \
--configs hierarchical_segmentation_unet_v4 \
--epochs 100 \
--batch_size 32
### 収束しない
uv run python run_experiments.py \
--configs class_specific_decoder \
--epochs 100 \
--batch_size 32
uv run python validate_advanced.py experiments/multiscale_distance/checkpoints/checkpoint_epoch_0020.pth \
--override training.batch_size=2 \
--override data.train_annotation="data/annotations/instances_train2017_person_only_no_crowd_500.json" \
--override data.val_annotation="data/annotations/instances_val2017_person_only_no_crowd_100.json"
uv run python validate_advanced.py experiments/variable_roi_hires/checkpoints/checkpoint_epoch_0020.pth \
--override training.batch_size=2 \
--override data.train_annotation="data/annotations/instances_train2017_person_only_no_crowd_500.json" \
--override data.val_annotation="data/annotations/instances_val2017_person_only_no_crowd_100.json"
uv run python validate_advanced.py experiments/variable_roi_progressive1/checkpoints/checkpoint_epoch_0020.pth \
--override training.batch_size=2 \
--override data.train_annotation="data/annotations/instances_train2017_person_only_no_crowd_500.json" \
--override data.val_annotation="data/annotations/instances_val2017_person_only_no_crowd_100.json"
uv run python validate_advanced.py experiments/variable_roi_progressive_focal/checkpoints/checkpoint_epoch_0020.pth \
--override training.batch_size=2 \
--override data.train_annotation="data/annotations/instances_train2017_person_only_no_crowd_500.json" \
--override data.val_annotation="data/annotations/instances_val2017_person_only_no_crowd_100.json"
uv run python validate_advanced.py experiments/hierarchical_segmentation/checkpoints/checkpoint_epoch_0020.pth \
--override training.batch_size=2 \
--override data.train_annotation="data/annotations/instances_train2017_person_only_no_crowd_500.json" \
--override data.val_annotation="data/annotations/instances_val2017_person_only_no_crowd_100.json"
uv run python validate_advanced.py experiments/hierarchical_segmentation_unet/checkpoints/checkpoint_epoch_0020.pth \
--override training.batch_size=2 \
--override data.train_annotation="data/annotations/instances_train2017_person_only_no_crowd_500.json" \
--override data.val_annotation="data/annotations/instances_val2017_person_only_no_crowd_100.json"
uv run python validate_advanced.py experiments/hierarchical_segmentation_unet_v2/checkpoints/checkpoint_epoch_0020.pth \
--override training.batch_size=2 \
--override data.train_annotation="data/annotations/instances_train2017_person_only_no_crowd_500.json" \
--override data.val_annotation="data/annotations/instances_val2017_person_only_no_crowd_100.json"
uv run python validate_advanced.py experiments/hierarchical_segmentation_unet_v3/checkpoints/checkpoint_epoch_0020.pth \
--override training.batch_size=2 \
--override data.train_annotation="data/annotations/instances_train2017_person_only_no_crowd_500.json" \
--override data.val_annotation="data/annotations/instances_val2017_person_only_no_crowd_100.json"
uv run python validate_advanced.py experiments/hierarchical_segmentation_unet_v4/checkpoints/checkpoint_epoch_0020.pth \
--override training.batch_size=2 \
--override data.train_annotation="data/annotations/instances_train2017_person_only_no_crowd_500.json" \
--override data.val_annotation="data/annotations/instances_val2017_person_only_no_crowd_100.json"
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r112m224 --epochs 20 --batch_size 2
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r112m192 --epochs 20 --batch_size 2
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r112m160 --epochs 20 --batch_size 2
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r112m112 --epochs 20 --batch_size 2
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r96m192 --epochs 20 --batch_size 16
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r96m160 --epochs 20 --batch_size 16
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r96m112 --epochs 20 --batch_size 16
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r96m96 --epochs 20 --batch_size 16
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r80m160 --epochs 20 --batch_size 16
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r80m112 --epochs 20 --batch_size 16
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r80m96 --epochs 20 --batch_size 16
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r80m80 --epochs 20 --batch_size 16
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r64m112 --epochs 20 --batch_size 16
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r64m96 --epochs 20 --batch_size 16
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r64m80 --epochs 20 --batch_size 16
uv run python run_experiments.py --configs rgb_hierarchical_unet_v2_attention_r64m64 --epochs 20 --batch_size 16
uv run python run_experiments.py \
--configs rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r64x48m128x96_disttrans_contdet_baware_from_B0 \
--epochs 100 \
--batch_size 16 \
--mixed_precision
uv run python train_distillation_staged.py \
--config rgb_hierarchical_unet_v2_distillation_b0_from_b3_temp_prog \
--batch_size 16 \
--epochs 100 \
--mixed_precision
uv run python train_distillation_staged.py \
--config rgb_hierarchical_unet_v2_distillation_b1_from_b3_temp_prog \
--batch_size 4 \
--epochs 100 \
--mixed_precision
- B3 -> B7
Epoch 046: 100%|█████████████████████████████████████████████████████████| 3745/3745 [19:55<00:00, 3.13it/s, loss=0.5109, kl=0.0037, mse=1.4992, dice=0.2890] Using cached Teacher B3 mIoU: 0.8708 Validation: 100%|████████████████████████████████████████████████████████████████| 163/163 [00:24<00:00, 6.58it/s, loss=0.6223, mIoU_B7=0.8919, agree=0.9831] [Validation Summary] Total Loss: 0.5976 KL Loss: 0.0073 MSE Loss: 1.7558 BCE Loss: 0.1127 Dice Loss: 0.1997 Student B7 mIoU: 0.8838 Teacher B3 mIoU: 0.8708 B3-B7 Agreement: 0.9887 (98.87%) mIoU Difference (B7-B3): 0.0130
# B7からB0への蒸留(64x48/128x96)
python run_experiments.py \
--configs rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r64x48m128x96_disttrans_contdet_baware_distill_B7_to_B0 \
--epochs 20 \
--batch_size 4 \
--mixed_precision
# B7からB1への蒸留(80x60/160x120)
python run_experiments.py \
--configs rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r80x60m160x120_disttrans_contdet_baware_distill_B7_to_B1 \
--epochs 20 \
--batch_size 4 \
--mixed_precision
ONNX エクスポートコマンド
uv run python export_hierarchical_instance_peopleseg_onnx.py \
experiments/rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r80x60m160x120_disttrans_contdet_baware_from_B1/checkpoints/best_model_b1_80x60_0.8551.pth \
--dilation_pixels 1
テスト推論コマンド
uv run python test_hierarchical_instance_peopleseg_onnx.py \
--onnx experiments/rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r80x60m160x120_disttrans_contdet_baware_from_B1/checkpoints/best_model_b1_80x60_0.8551.onnx \
--annotations data/annotations/instances_val2017_person_only_no_crowd.json \
--num_images 50 \
--score_threshold 0.01

ONNX一括エクスポート
B=1
SCORE=8497
RSH=128
RSW=96
H=128
W=160
REH=$((RSH * 2))
REW=$((RSW * 2))
uv run python export_hierarchical_instance_peopleseg_onnx.py \
experiments/rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r${RSH}x${RSW}m${REH}x${REW}_disttrans_contdet_baware_from_B${B}/checkpoints/best_model_b${B}_0.${SCORE}.pth \
--output best_model_b${B}_${H}x${W}_${RSH}x${RSW}_0.${SCORE}_dil0.onnx \
--image_size ${H},${W}
uv run python export_hierarchical_instance_peopleseg_onnx.py \
experiments/rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r${RSH}x${RSW}m${REH}x${REW}_disttrans_contdet_baware_from_B${B}/checkpoints/best_model_b${B}_0.${SCORE}.pth \
--output best_model_b${B}_${H}x${W}_${RSH}x${RSW}_0.${SCORE}_dil1.onnx \
--image_size ${H},${W} \
--dilation_pixels 1
H=240
W=320
REH=$((RSH * 2))
REW=$((RSW * 2))
uv run python export_hierarchical_instance_peopleseg_onnx.py \
experiments/rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r${RSH}x${RSW}m${REH}x${REW}_disttrans_contdet_baware_from_B${B}/checkpoints/best_model_b${B}_0.${SCORE}.pth \
--output best_model_b${B}_${H}x${W}_${RSH}x${RSW}_0.${SCORE}_dil0.onnx \
--image_size ${H},${W}
uv run python export_hierarchical_instance_peopleseg_onnx.py \
experiments/rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r${RSH}x${RSW}m${REH}x${REW}_disttrans_contdet_baware_from_B${B}/checkpoints/best_model_b${B}_0.${SCORE}.pth \
--output best_model_b${B}_${H}x${W}_${RSH}x${RSW}_0.${SCORE}_dil1.onnx \
--image_size ${H},${W} \
--dilation_pixels 1
H=480
W=640
REH=$((RSH * 2))
REW=$((RSW * 2))
uv run python export_hierarchical_instance_peopleseg_onnx.py \
experiments/rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r${RSH}x${RSW}m${REH}x${REW}_disttrans_contdet_baware_from_B${B}/checkpoints/best_model_b${B}_0.${SCORE}.pth \
--output best_model_b${B}_${H}x${W}_${RSH}x${RSW}_0.${SCORE}_dil0.onnx \
--image_size ${H},${W}
uv run python export_hierarchical_instance_peopleseg_onnx.py \
experiments/rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r${RSH}x${RSW}m${REH}x${REW}_disttrans_contdet_baware_from_B${B}/checkpoints/best_model_b${B}_0.${SCORE}.pth \
--output best_model_b${B}_${H}x${W}_${RSH}x${RSW}_0.${SCORE}_dil1.onnx \
--image_size ${H},${W} \
--dilation_pixels 1
H=640
W=640
REH=$((RSH * 2))
REW=$((RSW * 2))
uv run python export_hierarchical_instance_peopleseg_onnx.py \
experiments/rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r${RSH}x${RSW}m${REH}x${REW}_disttrans_contdet_baware_from_B${B}/checkpoints/best_model_b${B}_0.${SCORE}.pth \
--output best_model_b${B}_${H}x${W}_${RSH}x${RSW}_0.${SCORE}_dil0.onnx \
--image_size ${H},${W}
uv run python export_hierarchical_instance_peopleseg_onnx.py \
experiments/rgb_hierarchical_unet_v2_fullimage_pretrained_peopleseg_r${RSH}x${RSW}m${REH}x${REW}_disttrans_contdet_baware_from_B${B}/checkpoints/best_model_b${B}_0.${SCORE}.pth \
--output best_model_b${B}_${H}x${W}_${RSH}x${RSW}_0.${SCORE}_dil1.onnx \
--image_size ${H},${W} \
--dilation_pixels 1