【TFJS】_FusedMatMul only supports rank-1 bias but got rank 3. at Object.fusedBatchMatMul
問題
LSTM, GRU, RNN を含む ONNX から変換した TensorFlow.js モデルをブラウザ上で実行したい。多くのパターンでは正常に動作するが、 LSTM, RNN, GRU を含むモデルは TensorFlow.js への変換は問題なく行えるものの、wasm を使用してモデルを実行したときに下記のエラーが発生することがある。
pip show tensorflowjs | grep Version
Version: 4.22.0
pip show onnx2tf | grep Version
Version: 1.27.1
# tensorflowjs_converter が 2025年4月4日の時点では
# tensorflow v2.17.0以前のバージョンとの組み合わせでしか正常動作しない
pip show tensorflow | grep Version
Version: 2.17.0
Uncaught (in promise) Error: _FusedMatMul only supports rank-1 bias but got rank 3.
at Object.fusedBatchMatMul [as kernelFunc] (_FusedMatMul.ts:70:13)
問題の再現
まずは再現する。LSTMを含む ONNX を TensorFlow.js モデルへ変換する。まずは ONNX から saved_model へ変換する。
onnx2tf -i xxx.onnx -kat input
CLI からでも saved_model を tensorflow.js フォーマットへ変換可能だが、後続の処理との差分を明確にするためあえて Python のスクリプトを使用して saved_model を tensorflow.js へ変換する。
from tensorflowjs.converters import tf_saved_model_conversion_v2
tf_saved_model_conversion_v2.convert_tf_saved_model(
saved_model_dir="saved_model",
output_dir="tfjs_model",
)
python convert_saved_model_to_tfjs.py
生成した tensorflow.js モデルをブラウザ上で推論するためだけのHTMLファイルを作成する。なお、今回は問題が発生しやすい wasm バックエンド、webgl バックエンド、および、webgpu バックエンドのうち、wasm バックエンドを使用して推論する。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>TensorFlow.js 推論ベンチマーク</title>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@4.22.0/dist/tf.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-backend-wasm/dist/tf-backend-wasm.js"></script>
</head>
<body>
<h1>TensorFlow.js モデル推論ベンチマーク</h1>
<div id="results"></div>
<script>
const models = [
{ name: "tfjs_model", inputShape: [1, 30, 11] },
];
async function benchmarkModel(modelInfo) {
const modelPath = `${modelInfo.name}/model.json`;
const model = await tf.loadGraphModel(modelPath);
const inputTensor = tf.randomNormal(modelInfo.inputShape);
// Warm-up run (ignored)
const dummy_output = model.execute(inputTensor);
// Benchmarking
const iterations = 10;
const times = [];
for (let i = 0; i < iterations; i++) {
const start = performance.now();
const output = model.execute(inputTensor);
const end = performance.now();
times.push(end - start);
}
const avgTime = times.reduce((a, b) => a + b, 0) / times.length;
return {
model: modelInfo.name,
averageTime: avgTime.toFixed(3)
};
}
async function runBenchmarks() {
const resultsDiv = document.getElementById('results');
await tf.ready();
await tf.setBackend('wasm');
for (const modelInfo of models) {
const result = await benchmarkModel(modelInfo);
const p = document.createElement('p');
const backEnd = await tf.getBackend();
p.textContent = `${result.model}: Backend: ${backEnd}, 平均推論時間: ${result.averageTime} ms`;
resultsDiv.appendChild(p);
}
}
runBenchmarks();
</script>
</body>
</html>
Webサーバーを起動する。
python -m http.server
ブラウザから http://localhost:8000/ にアクセスすると自動的に推論が実行され、冒頭のエラーが発生する。_FusedMatMul only supports rank-1 bias but got rank 3. at Object.fusedBatchMatMul
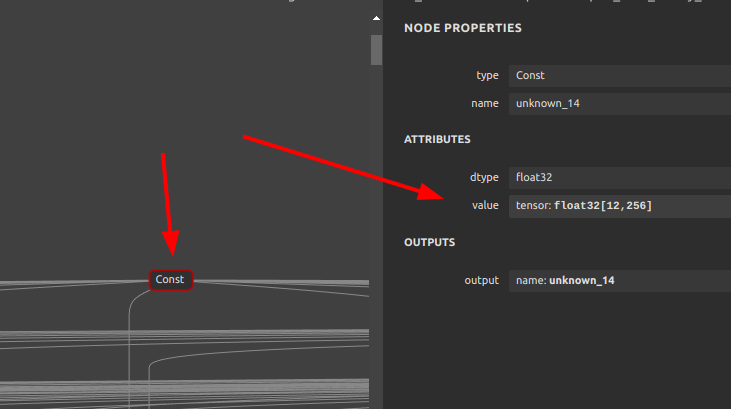
エラーメッセージが指し示している問題のオペレーションはこの _FusedMatMul。そしてバイアスとして入力されている unknown_14 という定数。

上記の _FusedMatMul のバイアスとして入力される下記の Const の値が、wasm バックエンドでは非対応な2次元の定数値になっているためエラーが発生する。wasm および webgl, webgpu は実装が不十分であり、MatMul に2次元以上のバイアスが設定されているとランタイムエラーが発生する。
解決策
そもそも、_FusedMatMul というオペレーションは、TensorFlow saved_model を生成した段階ではモデルの構造内には存在しない。したがって、tensorflowjs_converter を使用して saved_model から tfjs モデルへ変換した際に自動的に生成されている。
もっと具体的に、tensorflowjs_converter のロジックのどの部分が問題かというと、下記の部分の2個目の _run_grappler の処理である。 # rerun grappler to fuse conv2d/matmul というコメントが書かれているとおり、このモデル最適化処理 _run_grappler を実行するとモデルの最適化の過程で _FusedMatMul が生成される。
この処理では _run_grappler が2回コールされているため、2個目の _run_grappler のみを一時的に無効化する手段が必要となる。では、2個目の _run_grappler のみを強制的に無効化して tensorflow.js モデルへ変換する手順を説明する。
tensorflowjs_converter のロジックをパッケージカスタマイズせずに該当処理部分のみをインジェクションして強制的に書き換える手段で対応する。 skip_second_grappler.py というPythonファイルを新規作成し、下記の通りロジックを記載する。
import os
import tensorflowjs.converters.tf_saved_model_conversion_v2 as converter
# Save the original function
original_run_grappler = converter._run_grappler
# A global variable to count the number of calls
grappler_call_count = 0
# Functions for monkey patching
def selective_run_grappler(config, graph_def, graph, signature_def):
global grappler_call_count
grappler_call_count += 1
# Run _run_grappler the first time, skip _run_grappler the second time
if grappler_call_count == 1:
print(f"Running Grappler optimization (call #{grappler_call_count})")
return original_run_grappler(config, graph_def, graph, signature_def)
else:
print(f"Skipping Grappler optimization (call #{grappler_call_count})")
return graph_def
# Override Function
converter._run_grappler = selective_run_grappler
convert_saved_model_to_tfjs.py を下記のように書き換える。これは、tensorflowjs_converter を実行するタイミングで、一度だけモンキーパッチを適用してconvert_tf_saved_model の振る舞いを一時的に変更する最終手段である。これで2回目の _run_grappler の呼び出しだけが無効化される。美しくないがパッケージを改造しなくても正常に動作するので致し方ない回避策ではある。
from tensorflowjs.converters import tf_saved_model_conversion_v2
# tensorflowjs_converter にパッチの適用
exec(open('skip_second_grappler.py').read())
tf_saved_model_conversion_v2.convert_tf_saved_model(
saved_model_dir="saved_model",
output_dir="tfjs_model",
control_flow_v2=True,
)
再び変換を実行する。
python convert_saved_model_to_tfjs.py
下図のように、2個目の _run_grappler の処理をインジェクトしてスキップしたあとに生成された tensorflow.js モデルの MatMul は _FusedMatMul 化が回避された状態になる。MatMul と BiasAdd が分離した状態になっている。

wasm バックエンドを使用していてもエラーが発生せず正常に RNN, LSTM, GRU が推論できることが確認できる。
