自由入力解像度対応 Detection Transformer を錬成するトリック
この記事は CyberAgent AI Lab Advent Calendar 2024 3日目の記事です。
1. Detection Transformer の課題感
Detection Transformer はとても性能が高いです。一方で下記の課題感を日々感じています。
- 学習コストがとても高い
- 学習時に推論解像度が固定されてしまってスケールしない
- アスペクト比の変更に弱い(これはCNNでも同じです)
- モデルの入力解像度が固定されてしまっているので前処理が手間
1.と2.は2つで1つのような相互関係性のある課題で、高解像度あるいは低解像度で性能をしっかり発揮させるためには、推論時の入力解像度を学習着手前から強く意識し、高解像度で推論する見込みなら高解像度であらかじめ学習させておかないと、推論時に期待するパフォーマンスを得られません。この検証結果については下記の 460_RT-DETRv2-Wholebody25 の README に検証の過程から結果までをまとめていますので、気になる方は一度ご覧ください。
どれほど良くないか、が直感的に分かる結果だけをここにシェアしておきます。下図は RT-DETRv2-X を自作の強力なデータセットで学習したモデルを使用して推論した結果です。ただ、この記事は 高解像度の画像を640x640で学習したTransformerで推論すると性能が著しく落ちる ということを主眼にお伝えしたいのではなく、この固定解像度でしか推論できないモデルを自由入力解像度に対応した ONNX として生成するトリックを共有することを目的としています。下図の画像の精度の良し悪しは本題とはあまり関係がありません。
| 内容 | 値 |
|---|---|
| モデルの入力解像度 | 640x640 |
| 画像の解像度 | 1600x898 |

画像引用:https://github.com/biubug6/Face-Detector-1MB-with-landmark
2. RT-DETRv2 のデータローダー
本題に移る前に、RT-DETRv2 の学習時に使用されるデータローダーがどのような前処理を行って画像を学習に使用しているかを見ておきます。
train_dataloader:
dataset:
transforms:
ops:
- {type: RandomPhotometricDistort, p: 0.5}
- {type: RandomZoomOut, fill: 0}
- {type: RandomIoUCrop, p: 0.8}
- {type: SanitizeBoundingBoxes, min_size: 1}
- {type: RandomHorizontalFlip}
- {type: Resize, size: [640, 640], }
- {type: SanitizeBoundingBoxes, min_size: 1}
- {type: ConvertPILImage, dtype: 'float32', scale: True}
- {type: ConvertBoxes, fmt: 'cxcywh', normalize: True}
policy:
name: stop_epoch
epoch: 71 # epoch in [71, ~) stop `ops`
ops: ['RandomPhotometricDistort', 'RandomZoomOut', 'RandomIoUCrop']
collate_fn:
type: BatchImageCollateFuncion
scales: [480, 512, 544, 576, 608, 640, 640, 640, 672, 704, 736, 768, 800]
stop_epoch: 71 # epoch in [71, ~) stop `multiscales`
shuffle: True
total_batch_size: 16 # total batch size equals to 16 (4 * 4)
num_workers: 4
val_dataloader:
dataset:
transforms:
ops:
- {type: Resize, size: [640, 640]}
- {type: ConvertPILImage, dtype: 'float32', scale: True}
shuffle: False
total_batch_size: 32
num_workers: 4
Resize 処理の実装は下記にあります。torchvision.transforms.v2 の Resize を呼び出しているだけのようです。
""""Copyright(c) 2023 lyuwenyu. All Rights Reserved.
"""
import torch
import torch.nn as nn
import torchvision
torchvision.disable_beta_transforms_warning()
import torchvision.transforms.v2 as T
import torchvision.transforms.v2.functional as F
import PIL
import PIL.Image
from typing import Any, Dict, List, Optional
from .._misc import convert_to_tv_tensor, _boxes_keys
from .._misc import Image, Video, Mask, BoundingBoxes
from .._misc import SanitizeBoundingBoxes
from ...core import register
RandomPhotometricDistort = register()(T.RandomPhotometricDistort)
RandomZoomOut = register()(T.RandomZoomOut)
RandomHorizontalFlip = register()(T.RandomHorizontalFlip)
Resize = register()(T.Resize)
# ToImageTensor = register()(T.ToImageTensor)
# ConvertDtype = register()(T.ConvertDtype)
# PILToTensor = register()(T.PILToTensor)
SanitizeBoundingBoxes = register(name='SanitizeBoundingBoxes')(SanitizeBoundingBoxes)
RandomCrop = register()(T.RandomCrop)
Normalize = register()(T.Normalize)
このような前処理の手法で学習してもある程度性能はしっかり出ていますので、無理に周囲をパディングして正方形に加工し、そのうえで 640x640 に Resize しなくても問題は無い、と論文著者は考えているようです。実際に試すと分かりますが、冒頭でサンプルとして添付した 1600x898 のようなとても大きな解像度の画像を使用しない限りは大きな問題になることはありません。
3. PyTorchやONNXで推論するときの前処理の面倒さ
直近2年〜3年以内にリリースされた物体検出系のモデルは概ね上記と同じ前処理の方式を採用しているように見えます。したがって、ほとんどの前処理は複数のモデル間で共通化できる のです。少し前に流行っていた Transformer ベースの骨格検出モデルのように、前処理でアフィン変換などのよほど複雑な処理を記述する必要が無い場合はほぼ前処理を共通化できます。
ここでこう考えるようになります。毎回毎回推論コードに同じ前処理を1行も書きたくない。Resize も Normalization も RGB <-> BRG 変換も、全て。 と。いやいや、コードを書いても2〜3行でしょ。と言われればそのとおりなのですが、そもそもプログラムを1行も書きたくない身の私としては、とてもクリティカルな問題です。実運用においては、モデルを10種類以上並列動作させることは当たり前のように行いますし、それぞれのモデルに合わせた前処理を毎回書いて、テストをしているとどこかでミスをすることが多かったです。モデルをコピー&ペーストしてRunしたら何もしなくても即座に動作してほしいです。
4. 固定解像度化してしまった Detection Transformer の Nx3xHxW 自由入力解像度化
RT-DETRv2-X を使用して学習し、PyTorchからONNXへエクスポートするとき、1x3x640x640 に固定して出力することはチュートリアルどおりの手順でとても簡単にできます。最近の論文実装にはあらかじめ pytorch_to_onnx.py のようなエクスポート用のコードがコミットされているほど、定型文だけでほぼ確実にエクスポートは成功します。しかし、記事の最初と途中で記載したように以下の点で扱いにくいモデルが生成されるか、あるいはエラーが発生してそもそも期待するモデルを出力できません。
-
1x3x640x640のような固定解像度で出力されるため、プログラム側にResize処理を記述する必要がある - プログラム側に
/ 255.0のような正規化処理を記述する必要がある - OpenCVやPillowと組み合わせて使用する前提の場合、RGB<->BGRのチャンネル転置処理を記述する必要がある
- Nバッチ化や可変解像度化して出力しようとするとあらゆる箇所でエラーが発生する
そこで、下記のスクリプトを使用して、モデルに前処理を全てマージしてしまいます。正規の論文実装を大きく変更しています。
4-1. ONNXエクスポートスクリプト
Nバッチ化、自由入力解像度化に先立ち、論文実装のモデルの構造を一部最適化します。最適化、と言っても、RT-DETRv2 のモデル構造を書き換えるのではなく、TorchVision の非常に非効率な実装を書き換えます。ここでは詳細には記載しませんが、ポイントは
-
Reshape時に-1を使用しない - 必要のない
Gatherオペレーションを全て抹消する
の2点です。気になる方は私の過去のブログ記事 ONNXモデルのチューニングテクニック (基礎編), ONNXモデルのチューニングテクニック (応用編1), ONNXモデルのチューニングテクニック (応用編2) をご覧ください。
4-2. 前処理生成と前処理・本体のマージスクリプト
Nバッチ、自由入力解像度の前処理を生成します。
スクリプトを実行すると下図の2種類の前処理が生成され、4-1. ONNXエクスポートスクリプト で生成したONNXモデル本体に自動的にマージされます。
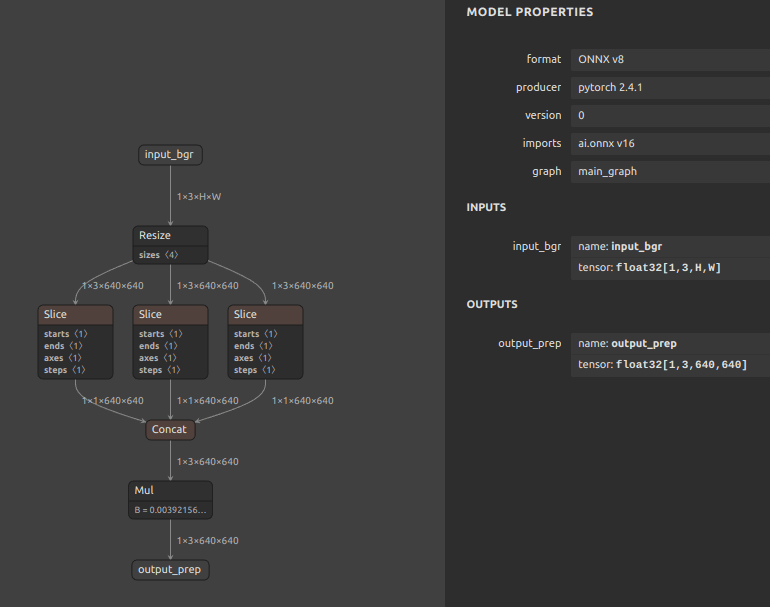
- 1バッチ、自由入力解像度の前処理部品
- Nバッチ、自由入力解像度の前処理部品
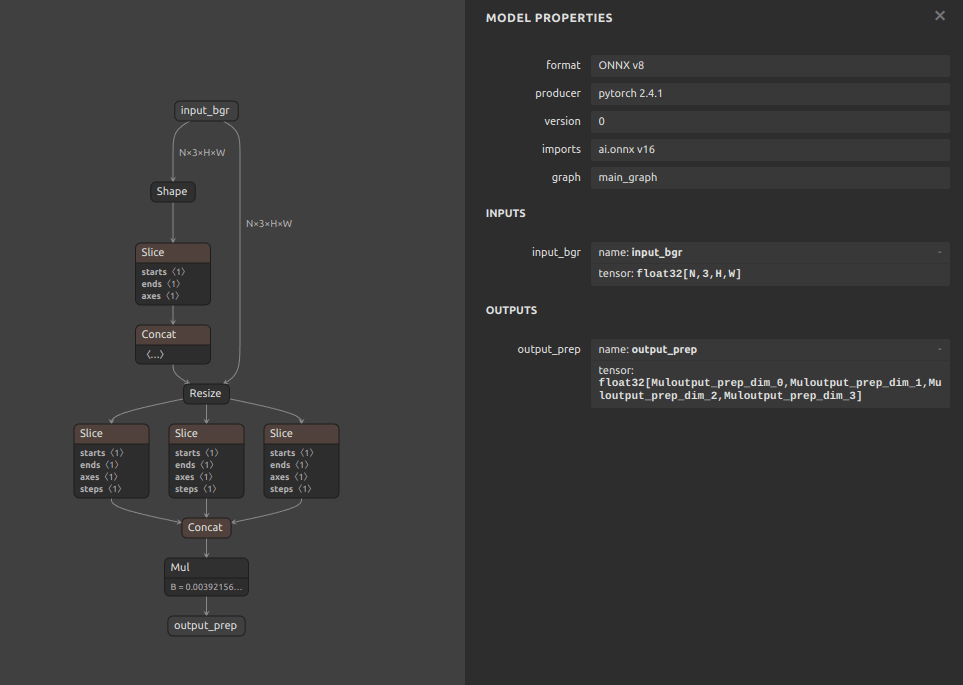
4-3. 解説
主なアイデアは下記の2点です。
- 前処理部分のみ Nバッチ、自由入力解像度で処理する
- モデル本体部分は 640x640 の固定解像度で処理する
前述したとおり、もともとモデル学習時のデータローダーはアスペクト比を維持するように記述されていませんでしたので、単純に入力された任意の解像度の画像を 640x640 に Resize するだけで同じ動作を実現できることが分かっていました。したがって、モデルの入力部のみを自由入力解像度とし、モデルにテンソルが入力された直後に 640x640 の固定解像度へ Resize するだけで済みます。残りの部分は通常のチャンネル転置と255.0除算による正規化を行っているだけです。
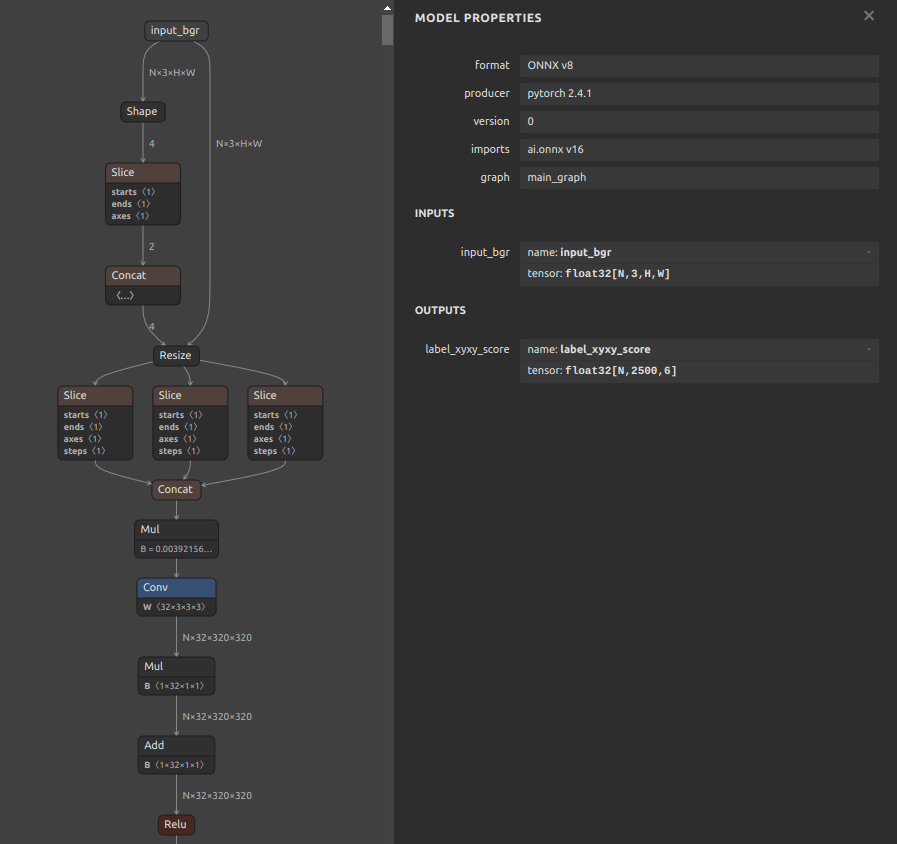
5. モデルの最終構造
前処理部分とモデル本体部分をマージして最終的に生成されたモデルの前半の部分だけを参考までに画像で共有します。 入力部が [N, 3, H, W] となっていますが、Conv 以降は [N, 32, 320, 320] となっており、Transformerのデフォルトの 640x640 サイズでの内部処理に影響を与えること無く自由な画像サイズでの推論を正常に実行できるモデルになりました。なお、このトリックは PyTorch では 実装不可能 です。
6. 終わりに
これでどのようなサイズの画像であっても前処理をプログラム側に一切記述しなくても正常に推論できる Detection Transformer モデルの完成です。このトリックは Detection Transformer のアーキテクチャのみならず、普段皆さんがお使いの CNN でも同じく適用可能ですので、ご興味があれば試してみてください。
では、続きは CyberAgent Developers Advent Calendar 2024 8日目 でお会いしましょう。
Discussion