【画像認識】CreateMLのObject Detection、うまく動かないの巻
0. そうだ、鳥認識写真アプリを作ろう
僕は鳥が好きなiOSエンジニアだ。
鳥を認識して写真を撮るアプリを作りたいなーと思った。
でも"鳥"にもいろいろあるから、まずは
ドバト(カワラバト)を単にObject Detectionするアプリを試しに作ることにした。
1. Object Detectionのモデル作成準備
Object Detectionのモデル作成には CreateMLを使うことにした。
CreateMLでドバトを認識するモデルを作るには、
まずは大量のドバトの写真が必要だ。
家を飛び出して、その辺にいるドバトを写真に収めてきた。
アプリを作りたいのと同時に、
写真の枚数によってモデルの精度がどのように変わってくるのか
についても知りたかったので、TraningDataを以下のように用意してみた。
一枚の写真に複数のドバトが映っているものも含まれている。
- ドバトの写っている写真20枚のTraningData
- ドバトの写っている写真30枚のTraningData
...(10枚ずつ増えていく)... - ドバトの写っている写真90枚のTraningData
- ドバトの写っている写真100枚のTraningData
- ドバトの写っている写真100枚 + 写っていない写真20枚のTraningData
- ドバトの写っている写真100枚 + 写っていない写真50枚のTraningData
2. 写真にannotationをする
さて写真データは用意できたが、TraningDataにドバトがいる場合
それらを四角で囲って「ここにドバトがいるよ!」ってannotationしてやる必要がある。
今回はこれをやるのに labelImage を使った。
使い方は以下が詳しかったので参考にした。
以下 labelImage を使う際に、上記URLとはやり方を変えた点があったので残しておく。
labelImageを使う際の注意点も残しておく。
変更点①
上記URLの
"2. インストール (3) 起動。" において、
python labelImg.py
を実行すると以下のように表示された。
Traceback (most recent call last):
File "labelImg.py", line 29, in <module>
from PyQt4.QtGui import *
ImportError: No module named PyQt4.QtGui
解決法としては、僕の環境では
python labelImg.py
ではなく
python3 labelImg.py
でうまくいった。
変更点②
上記URLの
"3. 使い方 (1) 「data/predefined_classes.txt」で学習に使用するクラスリストを定義。"
において、
今回はドバトのみを認識したいので
pigeon の一つだけを入力した。
変更点③
上記URLの
"3. 使い方 (2) ツールバー「保存する」の下にある「PascalVOC」をクリックして、「YOLO」に切り替える。" において、
今回はCreateML用にannotationするので、CreateML を選択した。
注意点①
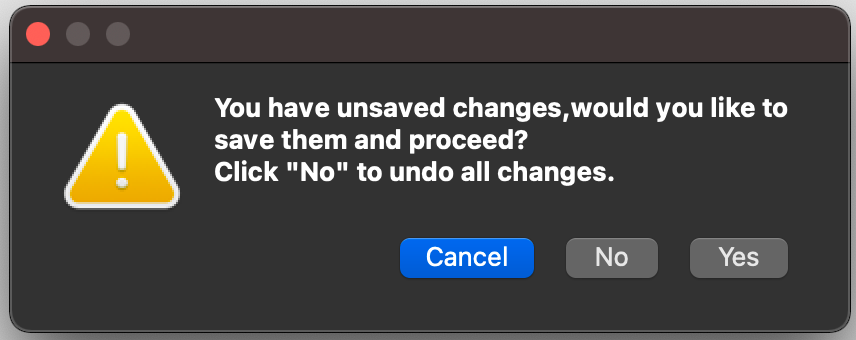
"3. 使い方 (3) ツールバー「ディレクトリを開く」で画像ファイルのフォルダを選択し、ツールバー「保存先を変更する」でアノテーションファイルのフォルダを選択。" において、
以下の表示が出るが、ここで Yes を選ぶとクラッシュした。
No を選ぶとうまくいく。。。🧐
クラッシュした後の画面は以下。
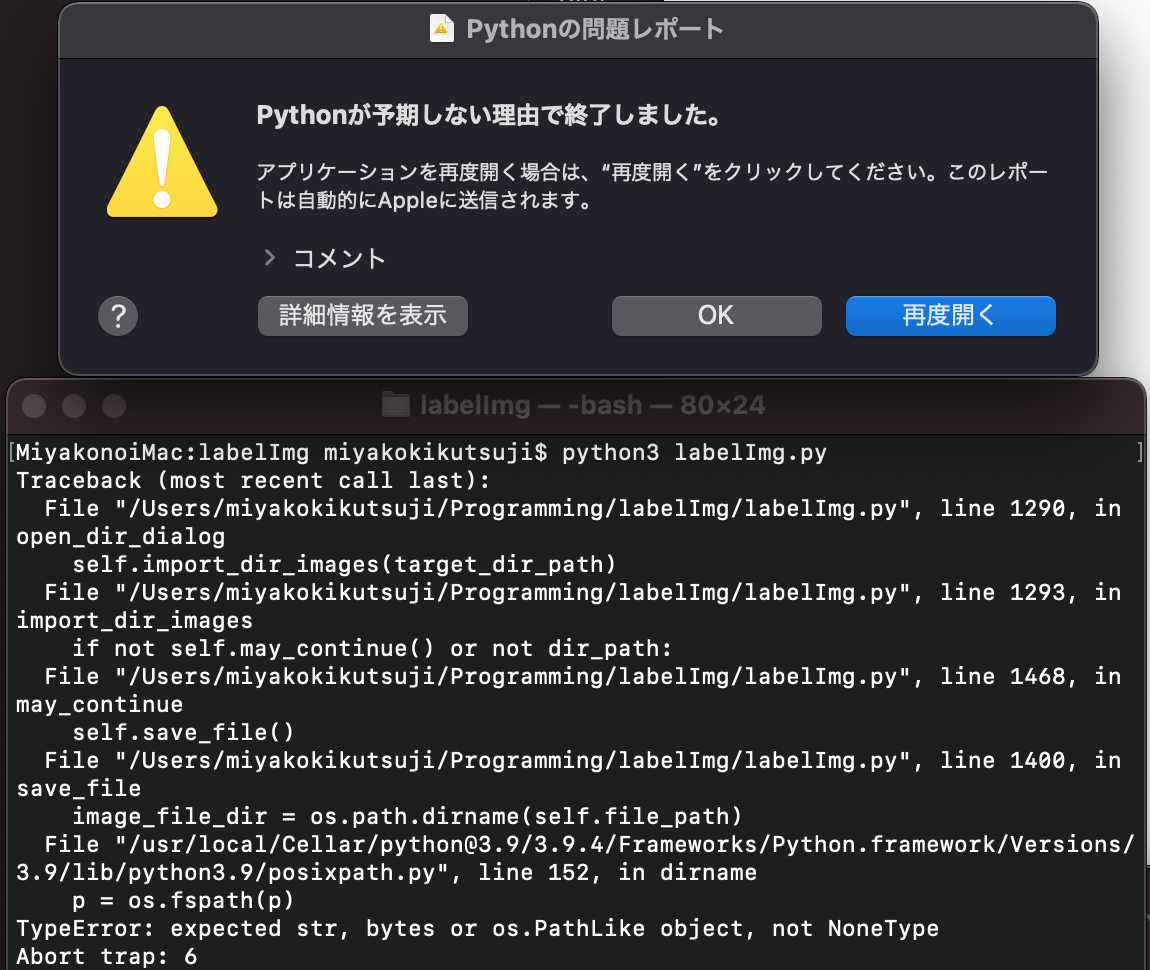
注意点②
写真上の物体を四角で囲んでannotationが終わったら、
写真一枚終わるごとに保存ボタンを押さないとうまく保存されない。
四角で囲ったのち保存せずに次の写真を開くと、
前の写真の四角で囲った事実が消えている。🧐
注意点③
ドバトの写っていない写真をTraningDataに含む場合、
それらの写真にannotationが無いことを以下のように明示する必要がある。
{
"image": "NoPigeon1.jpeg",
"annotations": []
}
自分の手で上記のjsonを書いてもよいが、labelImg上で
1.適当に四角で囲ってannotaionを"hoge"とする
↓
2."hoge"の四角を消去する
↓
3.保存ボタンを押す
ことにより上記のjsonが生成されたのでそのようにした。
3. TraningDataを学習させる
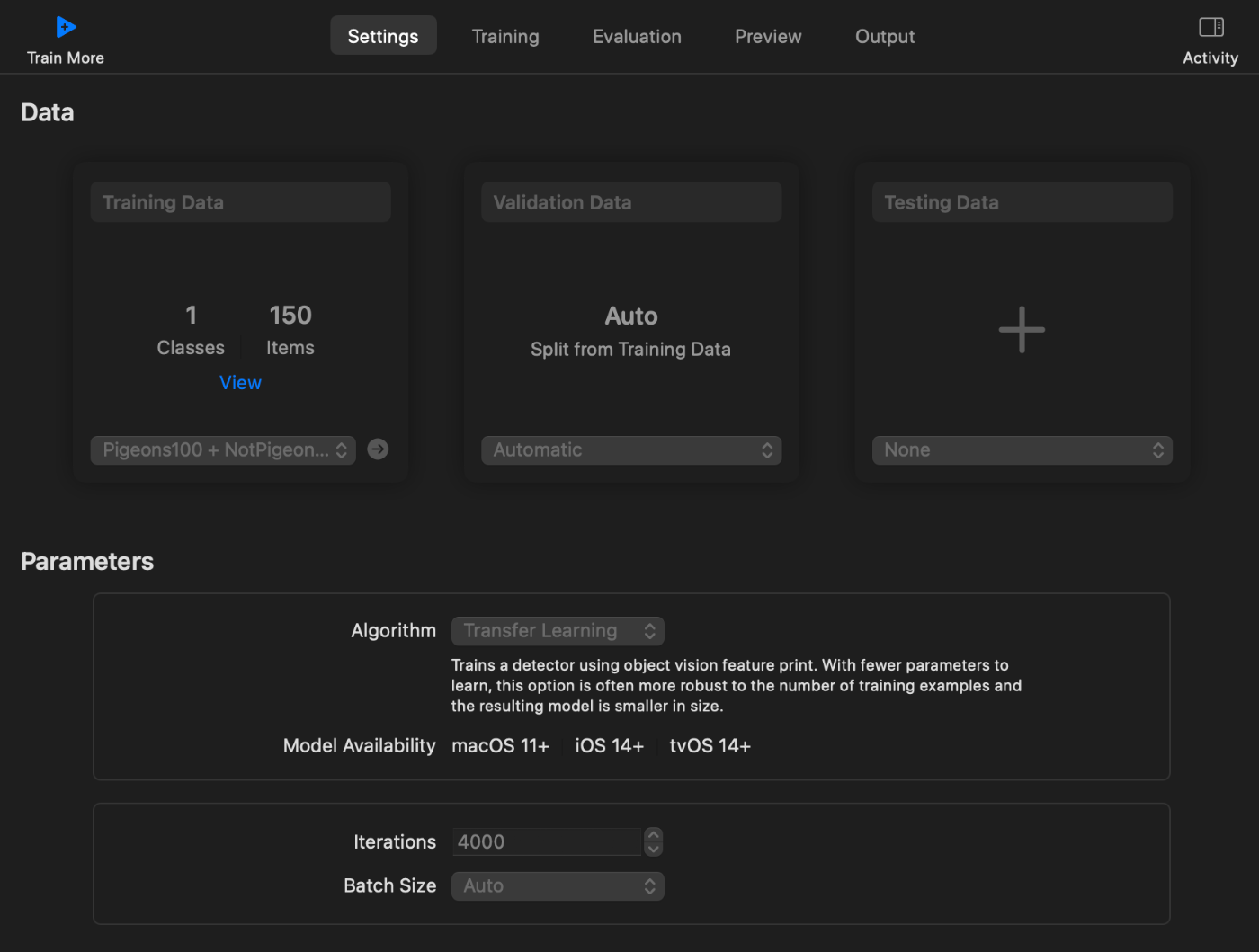
アルゴリズムの欄で、Full NetworkとTransfer Learningが選択できるが、
今回はTransfer Learningにしてみた。
IterationsとBatch Sizeもいじることが出来るようだけれど、
とりあえずデフォルトのままにしておいた。
Validation Dataは特に作らないでおく。
TraningDataのみにお手製データを突っ込むことにした。
例として
・ ドバトの写っている写真100枚 + 写っていない写真50枚のTraningData
の時のSettingsの画面は以下のようになった。
4. 結果と考えたこと
4-1. 数値で見てみよう
1.で述べた、計11種類のデータセットをそれぞれCreateMLに突っ込んで学習させてみた結果は
以下のようになった。
| ドバト写真 (+notドバト写真) |
traning I/U 50% | traning Varied I/U | validation I/U 50% | validation Varied I/U |
|---|---|---|---|---|
| 20枚 | 100% | 100% | - | - |
| 30枚 | 100% | 100% | - | - |
| 40枚 | 98% | 98% | - | - |
| 50枚 | 96% | 96% | 88% | 29% |
| 60枚 | 95% | 95% | 41% | 20% |
| 70枚 | 96% | 96% | 66% | 31% |
| 80枚 | 96% | 96% | 91% | 38% |
| 90枚 | 97% | 97% | 37% | 14% |
| 100枚 | 96% | 96% | 67% | 23% |
| 100 + 20枚 | 96% | 96% | 76% | 31% |
| 100 + 50枚 | 96% | 96% | 57% | 24% |
I/Uについては、IOUとかIoUとかとも表されるらしく、個人的には以下がわかりやすかった。
考えたこと
上の表から言えそうなことは、
数字だけ見ると一番ましに仕上がったのは80枚の時か???−−とも最初は思ったけど、
イヤ、違うな、数字が良いのはTraningDataにドバトではない物の写真がなかったから
ではないかと思うようになった。
「ドバトではない物」の情報が少なかったのかも知れない。
以下の4-2.で認識させている時の写真を載せているが、
TraningDataにドバトではない物の写真が入っていない場合
どのような写真をモデルに見せてもどこかしらに「ドバトがいるよ!」と
表示するようになってしまった。
このことを踏まえて考えると、一番うまく学習できたのは100+20枚の時なのかもしれない。
また、特に20枚と30枚のところは過学習の傾向がある。
さらに、20枚から40枚のTraningDataでは、CreateMLの仕様なのか
ValidationDataが作られなかった👀
自分でValidationDataを作らない場合は、
TraningDataを最低でも50枚は用意した方が良さそうだ。
ところで以下
を読んでみると、
You can expect to need at least 30 samples (bounding boxes) per object class, but even that will be too few for many challenging tasks. For high quality results, plan to have closer to 200 samples per class.
と書いてあった。。。
20枚では精度が出ないのはわかるけど、今回は少なくともドバトの写真は100枚はあるのに
これでもまだ写真数が足りないのか??うーん????
CreateML上で、もうちょっとハイパーパラメータを調整することができたなら
結果はもっと良い方向に変わっていたのかなあ?(調整する場所が見つからなかった)
4-2. 画像で見てみよう
CreateMLのPreview機能にいろいろな写真を突っ込んでみたものもUpしておく。
上から順に
- ドバトの写っている写真30枚のTraningDataで作ったモデル
- ドバトの写っている写真100枚のTraningDataで作ったモデル
- ドバトの写っている写真100枚 + 写っていない写真50枚のTraningDataで作ったモデル
でのPreview機能に突っ込んでみた結果である。(見づらい)

写真左から、
- TraningDataに含まれていたドバト
- TraningDataに含まれていないドバト2羽
- TraningDataに含まれていないドバト
- TraningDataに含まれていない僕のお手製オムライス
- TraningDataに含まれていないキジバト
である。
考えたこと
4-1.でも書いたが、
TraningDataにドバトではない物の写真が入っていない場合は
どのような写真をモデルに見せてもどこかしらに「ドバトがいるよ!」と
表示するようになってしまった。
オムライスにドバトを入れた覚えはない。。
そして、写真が見にくいのは承知しているが、画像認識により四角で囲われているところが全て
Pigeon 100% と表示されているのがなんだかおかしい。。
本来は96%とか、さまざまな値が入っているはずだ。
4-3. 学習曲線を見てみよう
以下は
- ドバトの写っている写真100枚のTraningDataで作ったモデル
の学習曲線である。
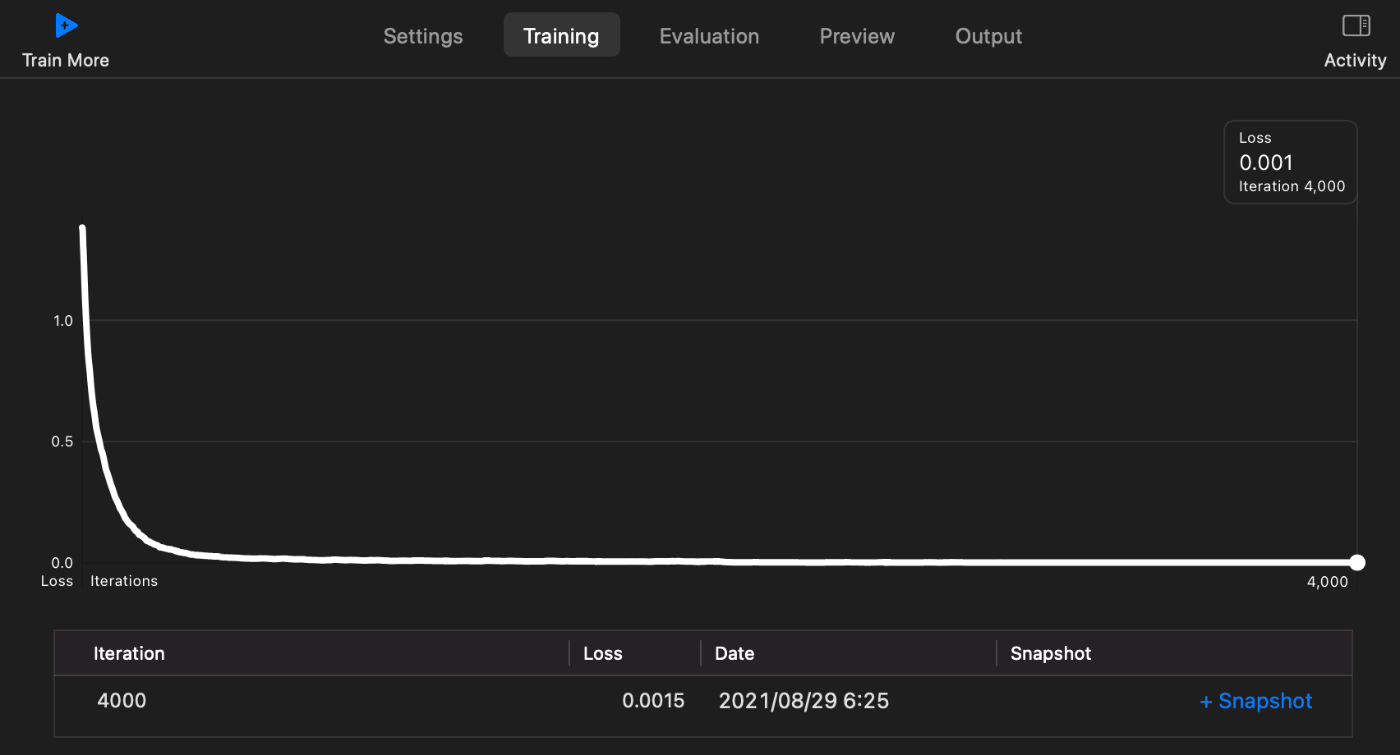
ほかの枚数のモデルも、同じような"ストン!"と落下する曲線を描いていた。
考えたこと
こんなに"ストン!"なグラフになるものなのか??
以下のAppleのデモ動画では、もっとグラフはギザギザしている👀
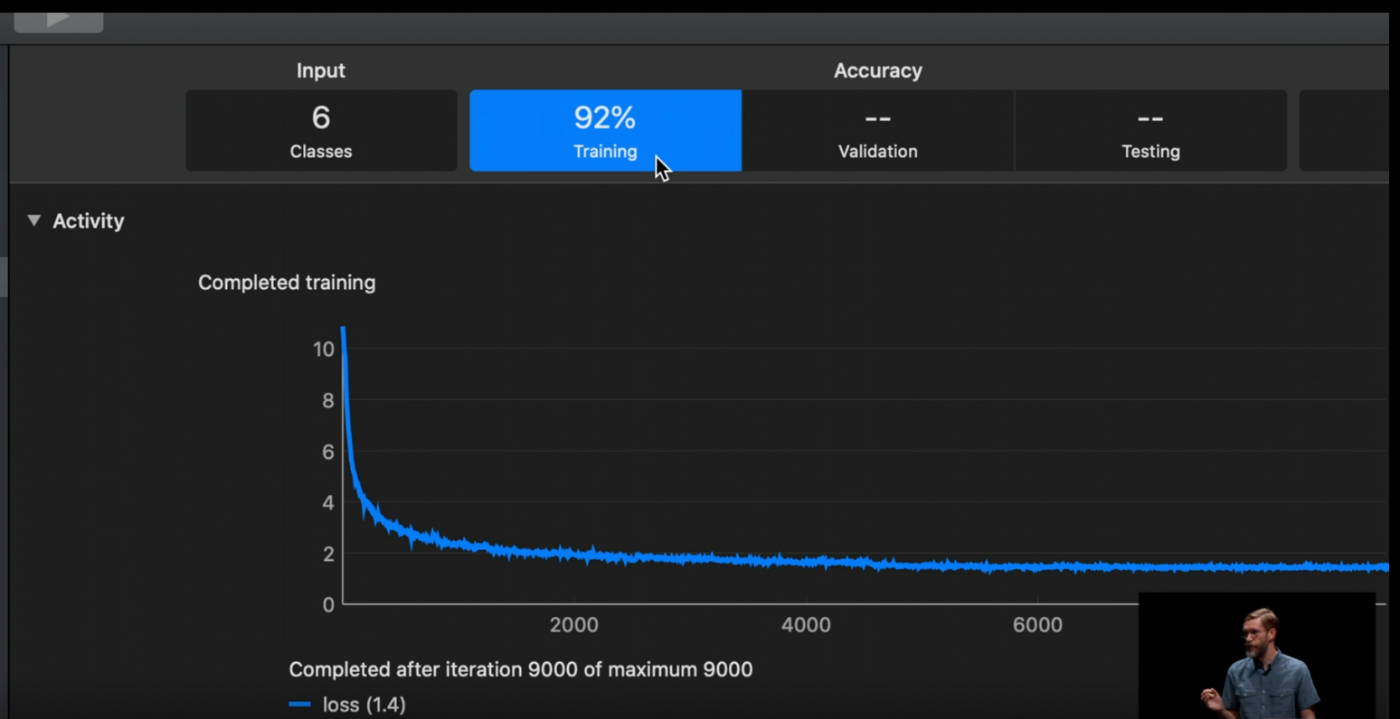
さらに、動画ではlossの値が1.4なのに対し、僕の曲線ではlossが0.001になっている。。。
何かがおかしい。。。
5. モデルをサンプルアプリに入れてみる
5-1. サンプルアプリをビルドする
ほんとはもっとうまく学習に成功したモデルをアプリに入れる予定だったが、
せっかくなので今回出来たモデルをアプリ上で試してみることにした。
CreateMLで作ったモデルは、Outputタブの右上のGetから入手できる。
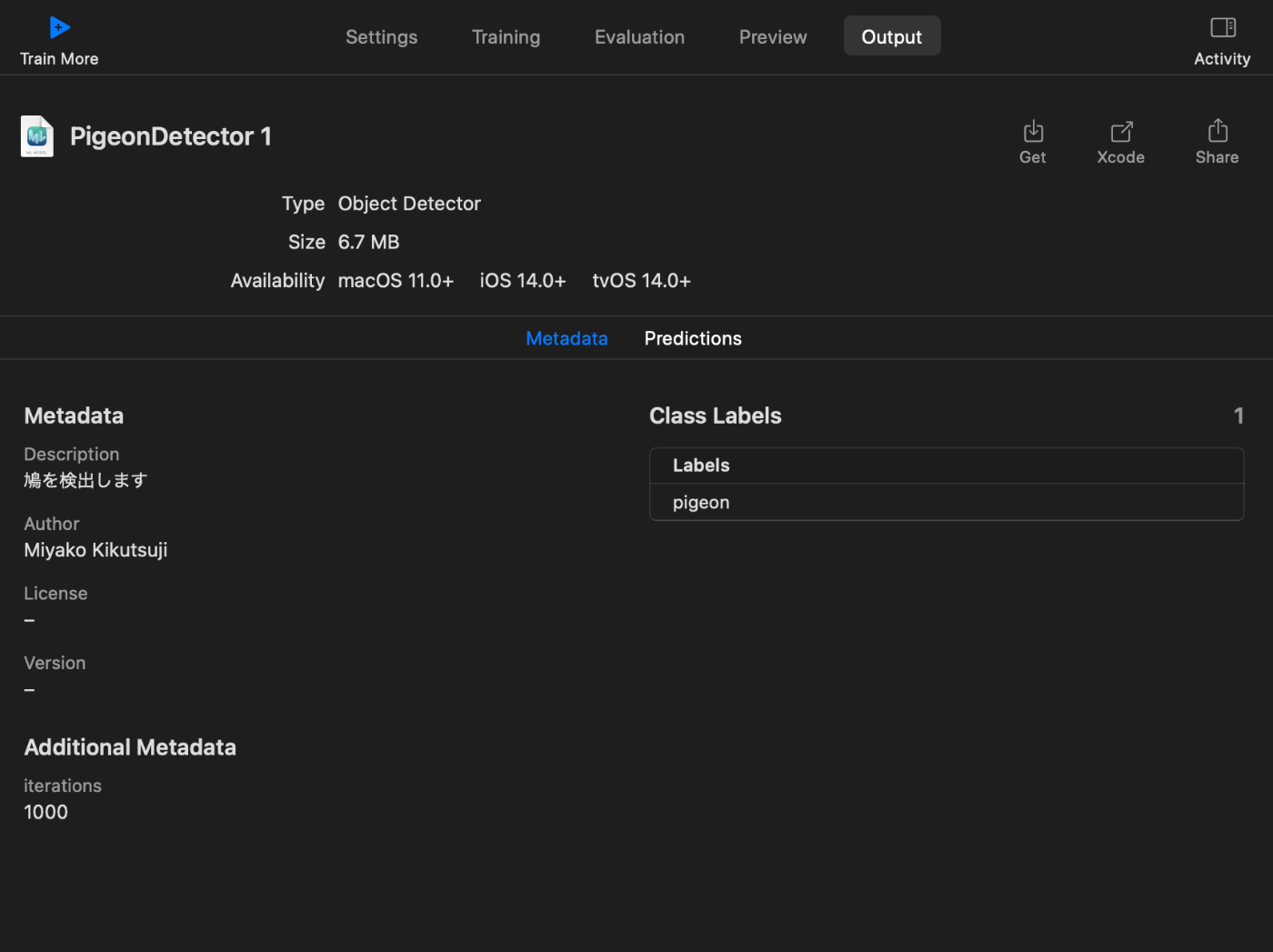
モデルを突っ込む先のアプリだが、今回は
モデルを試すだけなので以下のAppleのサンプルアプリのモデルを入れ替えることにした。
どうやら朝食に出てくる系の食べ物や飲み物を認識するアプリのようだ。
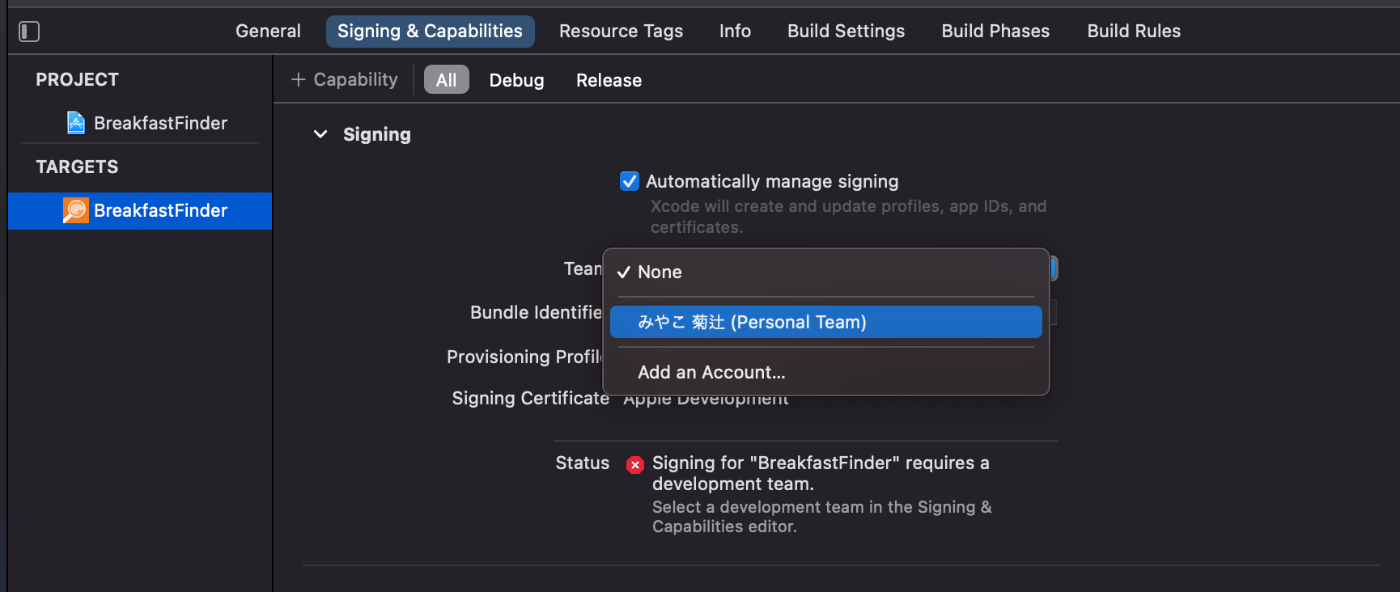
まずはサンプルアプリの動作確認をしたいが、
そのままじゃ動かないのでSigningを変更する。
さて自分のiPhoneにビルドして、冷蔵庫の中から卵パックを取り出して認識させてみた。

うん、正しくEggが認識できている。
Confidenceが表示されているが、この値は認識の確信度により常に変化している(※重要)。
5-1. サンプルアプリのモデルを変更する
このアプリの朝食認識モデルを、自分のドバト認識モデルに変更する。
まずは自分のモデル(PigeonDetector)を追加して
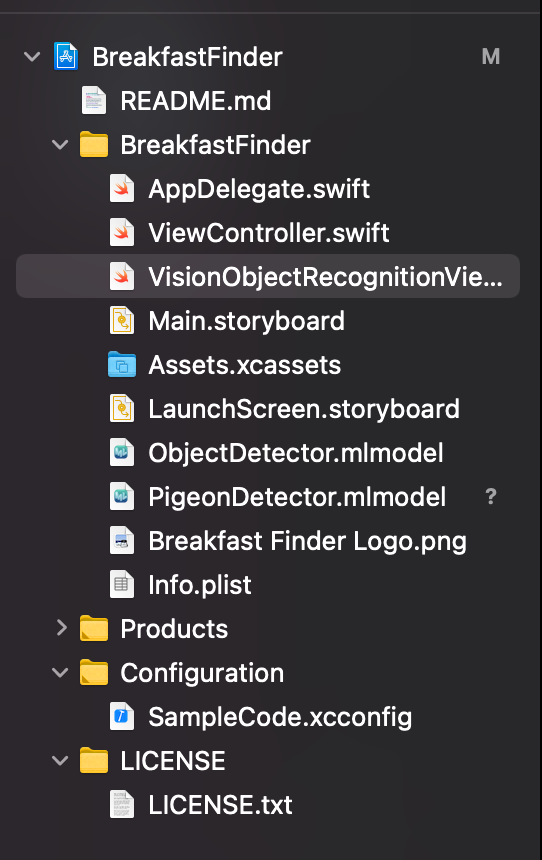
VisionObjectRecognitionViewController.swift の24行目を25行目のように書き換える。

さあビルドしてみよう。
今回突っ込んだのは、
- ドバトの写っている写真100枚 + 写っていない写真50枚のTraningDataで作ったモデル

・・・うーん。この亀さん写真はTraningDataに含まれていない写真だが、
写真内にpigeonがいることになっている。。
さらに Confidenceは1.00以外の値が表示されない。。(想定通りだが)。。
6. おわりに
今回は失敗だった。
Transfer Learningじゃなくて、Full networkで学習させたらうまくいくのかな。。。
CreateMLではハイパーパラメータの調整があまりできなかったのが原因な気もしているので、
次はPyTorchとかを試してみようかな👀
なんでこんなにうまくいかないのか解る方、よかったら教えてください😭🙏
おしまい🤗
Discussion