Pacemaker:概要理解
Pacemakerを現場で使用するため、RedHat社の「高可用性クラスターの設定および管理」という製品マニュアルをベースに概要を理解します。
構成
通常であれば2ノード以上でクラスタを構成しますが、1ノードで検証をします。私が調べた限りだと、本構成が最小構成であり、Pacemakerを理解する上で一番とっつきやすいと感じました。
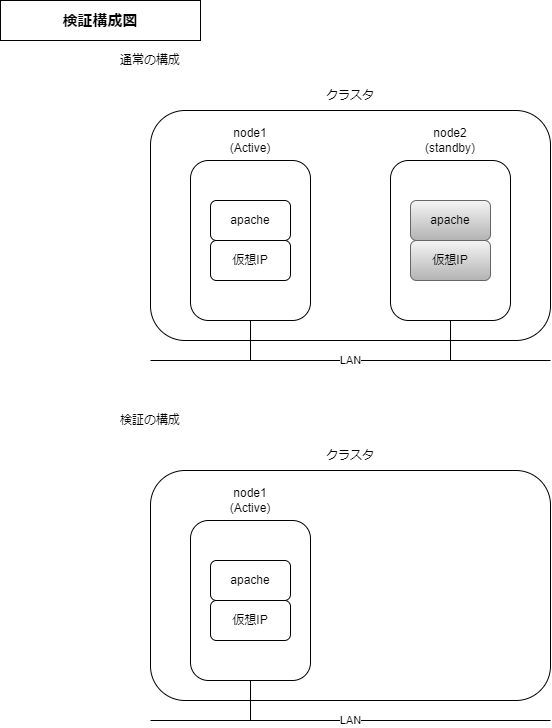
クラスタ検証
リンク先では、以下の方法を教えてくれます。
・クラスタ設定
・ステータスの表示
・サービス設定
Apache HTTP Serverをクラスタリソースとして登録後、異常時のクラスタ状態を知るためにリソース故障を起こします。
0.事前準備
①前提条件を満たすため、hostsを追加します。
[root@node1 ~]# cp -ip /etc/hosts /etc/hosts_`date +%Y%m%d`
[root@node1 ~]#
[root@node1 ~]# vi /etc/hosts
[root@node1 ~]#
[root@node1 ~]# diff /etc/hosts /etc/hosts_`date +%Y%m%d`
3d2
< 192.168.122.119 z1.example.com
[root@node1 ~]#
②システム登録、サブスクリプションの有効化
#システム登録
[root@node1 ~]# subscription-manager register --username ユーザ名
登録中: subscription.rhsm.redhat.com:443/subscription
パスワード:
このシステムは、次の ID で登録されました: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
登録したシステム名: node1
[root@node1 ~]#
#サブスクリプションの割当
[root@node1 ~]# subscription-manager list --available | grep "プール"
プール ID: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
[root@node1 ~]#
[root@node1 ~]# subscription-manager attach --pool=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
サブスクリプションが正しく割り当てられました: Red Hat Developer Subscription for Individuals
[root@node1 ~]#
#RHEL 8 Server HA リポジトリ有効化
[root@node1 ~]# subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms
リポジトリー 'rhel-8-for-x86_64-highavailability-rpms' は、このシステムに対して有効になりました。
[root@node1 ~]#
1.サービスの有効化
クラスタサービスを有効にする。
# インストール
[root@node1 ~]# dnf install pcs pacemaker fence-agents-all
## 「pcs」クラスタの表示、変更、作成
## 「pacemaker」 ノードクラスターをサポート(16ノード迄)
## 「fence-agents-all」クラスタから任意ノードを切断できる(フェンシング)ファイル群
# pcs有効化
[root@node1 ~]# systemctl start pcsd.service
[root@node1 ~]#
[root@node1 ~]# systemctl enable pcsd.service
Created symlink /etc/systemd/system/multi-user.target.wants/pcsd.service → /usr/lib/systemd/system/pcsd.service.
[root@node1 ~]#
# FW 穴あけ
[root@node1 ~]# firewall-cmd --permanent --add-service=high-availability
success
[root@node1 ~]#
[root@node1 ~]# firewall-cmd --reload
success
[root@node1 ~]# firewall-cmd --list-services --zone=public
cockpit dhcpv6-client high-availability ssh
[root@node1 ~]#
[root@node1 ~]# cat /usr/lib/firewalld/services/high-availability.xml
<?xml version="1.0" encoding="utf-8"?>
<service>
<short>Red Hat High Availability</short>
<description>This allows you to use the Red Hat High Availability (previously named Red Hat Cluster Suite). Ports are opened for corosync, pcsd, pacemaker_remote, dlm and corosync-qnetd.</description>
<port protocol="tcp" port="2224"/>
<port protocol="tcp" port="3121"/>
<port protocol="tcp" port="5403"/>
<port protocol="udp" port="5404"/>
<port protocol="udp" port="5405-5412"/>
<port protocol="tcp" port="9929"/>
<port protocol="udp" port="9929"/>
<port protocol="tcp" port="21064"/>
</service>
[root@node1 ~]#
## 「corosync、pcsd、pacemaker_remote、dlm、corosync-qnetd」のポートが空いている
[root@node1 ~]# rpm -ql pacemaker-2.1.2-4.el8.x86_64
/etc/sysconfig/pacemaker
/usr/lib/.build-id
/usr/lib/.build-id/1c
/usr/lib/.build-id/1c/df97dc2476cadb6af9f7bf873924070795c8df
/usr/lib/.build-id/43
/usr/lib/.build-id/43/dad811c5d7d2cd90c1e6ab6c4b77c1404b1337
/usr/lib/.build-id/5d
/usr/lib/.build-id/5d/0494ac97b7275415de5b2d6aa62f8ef232508a
/usr/lib/.build-id/6d
/usr/lib/.build-id/6d/f8a6e1a9722f28a9660596427d9490da2d0f0c
/usr/lib/.build-id/8a
/usr/lib/.build-id/8a/53ff41aef5840db32c811b81ffbc0bcdf65d76
/usr/lib/.build-id/8b
/usr/lib/.build-id/8b/20f2d008c722ad18c4e33dee9ee3fe27bab2a7
/usr/lib/.build-id/b4
/usr/lib/.build-id/b4/4da7388a321169fb7f57acf4642a38c8da15c3
/usr/lib/.build-id/bf
/usr/lib/.build-id/bf/176957fa4dd9c1e8dc1f339000c03f6c529d5c
/usr/lib/.build-id/cd
/usr/lib/.build-id/cd/f34d4f78b9c404f303f72fe871f400e5f064b3
/usr/lib/.build-id/da
/usr/lib/.build-id/da/c78f58e7b8dc84c3edc4290a78588ca1a23b1b
/usr/lib/.build-id/e9
/usr/lib/.build-id/e9/41f050da5e1a700a69ea9e7c662f39f25fe148
/usr/lib/ocf/resource.d/pacemaker/controld
/usr/lib/ocf/resource.d/pacemaker/remote
/usr/lib/systemd/system/pacemaker.service
/usr/libexec/pacemaker/attrd
/usr/libexec/pacemaker/cib
/usr/libexec/pacemaker/crmd
/usr/libexec/pacemaker/cts-exec-helper
/usr/libexec/pacemaker/cts-fence-helper
/usr/libexec/pacemaker/lrmd
/usr/libexec/pacemaker/pacemaker-attrd
/usr/libexec/pacemaker/pacemaker-based
/usr/libexec/pacemaker/pacemaker-controld
/usr/libexec/pacemaker/pacemaker-execd
/usr/libexec/pacemaker/pacemaker-fenced
/usr/libexec/pacemaker/pacemaker-schedulerd
/usr/libexec/pacemaker/pengine
/usr/libexec/pacemaker/stonithd
/usr/sbin/crm_attribute
/usr/sbin/crm_master
/usr/sbin/fence_watchdog
/usr/sbin/pacemakerd
/usr/share/doc/pacemaker
/usr/share/doc/pacemaker/COPYING
/usr/share/doc/pacemaker/ChangeLog
/usr/share/licenses/pacemaker
/usr/share/licenses/pacemaker/GPLv2
/usr/share/man/man7/ocf_pacemaker_controld.7.gz
/usr/share/man/man7/ocf_pacemaker_remote.7.gz
/usr/share/man/man7/pacemaker-controld.7.gz
/usr/share/man/man7/pacemaker-fenced.7.gz
/usr/share/man/man7/pacemaker-schedulerd.7.gz
/usr/share/man/man8/crm_attribute.8.gz
/usr/share/man/man8/crm_master.8.gz
/usr/share/man/man8/fence_watchdog.8.gz
/usr/share/man/man8/pacemakerd.8.gz
/usr/share/pacemaker/alerts
/usr/share/pacemaker/alerts/alert_file.sh.sample
/usr/share/pacemaker/alerts/alert_smtp.sh.sample
/usr/share/pacemaker/alerts/alert_snmp.sh.sample
/var/lib/pacemaker/cib
/var/lib/pacemaker/pengine
2.ユーザ設定
各ノードで hacluster ユーザの認証設定を行う。
今回は1ノードのみ(z1.example.com)。
# パスワード設定
[root@node1 ~]# passwd hacluster
ユーザー hacluster のパスワードを変更。
新しいパスワード:
新しいパスワードを再入力してください:
passwd: すべての認証トークンが正しく更新できました。
[root@node1 ~]#
# 認証設定
[root@node1 ~]# pcs host auth z1.example.com
Username: hacluster
Password:
z1.example.com: Authorized
[root@node1 ~]#
3.クラスタ構築
クラスタへのノード追加、及びクラスタの起動を行う。
[root@node1 ~]# pcs cluster setup my_cluster --start z1.example.com
No addresses specified for host 'z1.example.com', using 'z1.example.com'
Destroying cluster on hosts: 'z1.example.com'...
z1.example.com: Successfully destroyed cluster
Requesting remove 'pcsd settings' from 'z1.example.com'
z1.example.com: successful removal of the file 'pcsd settings'
Sending 'corosync authkey', 'pacemaker authkey' to 'z1.example.com'
z1.example.com: successful distribution of the file 'corosync authkey'
z1.example.com: successful distribution of the file 'pacemaker authkey'
Sending 'corosync.conf' to 'z1.example.com'
z1.example.com: successful distribution of the file 'corosync.conf'
Cluster has been successfully set up.
Starting cluster on hosts: 'z1.example.com'...
[root@node1 ~]#
[root@node1 ~]# pcs cluster status
Cluster Status:
Cluster Summary:
* Stack: corosync
* Current DC: z1.example.com (version 2.1.2-4.el8-ada5c3b36e2) - partition with quorum
* Last updated: Sat Jun 4 04:54:15 2022
* Last change: Sat Jun 4 04:54:13 2022 by hacluster via crmd on z1.example.com
* 1 node configured
* 0 resource instances configured
Node List:
* Online: [ z1.example.com ]
PCSD Status:
z1.example.com: Online
[root@node1 ~]#
4.フェンシング無効化
通常のクラスタであれば無効化をしないが、今回は検証目的の片系クラスタという特殊な要件のため、無効化を行う。
[root@node1 ~]# pcs property set stonith-enabled=false
[root@node1 ~]#
5.Apache設定
クラスタリソースとして登録するApacheの設定を行う。
# Apache設定
[root@node1 ~]# dnf install -y httpd wget
[root@node1 ~]# firewall-cmd --permanent --add-service=http
[root@node1 ~]# firewall-cmd --reload
[root@node1 ~]# cat <<-END >/var/www/html/index.html
> <html>
> <body>My Test Site - $(hostname)</body>
> </html>
> END
[root@node1 ~]#
# クラスタ監視設定
[root@node1 ~]# cat <<-END > /etc/httpd/conf.d/status.conf
> <Location /server-status>
> SetHandler server-status
> Order deny,allow
> Deny from all
> Allow from 127.0.0.1
> Allow from ::1
> </Location>
> END
[root@node1 ~]#
6.リソース登録
ノード間で共有するリソース(Apache,仮想IP)をクラスタに登録する。
# 利用できるリソース名の確認(Apache)
[root@node1 ~]# pcs resource describe apache
Assumed agent name 'ocf:heartbeat:apache' (deduced from 'apache')
ocf:heartbeat:apache - Manages an Apache Web server instance
This is the resource agent for the Apache Web server.
This resource agent operates both version 1.x and version 2.x Apache
servers.
The start operation ends with a loop in which monitor is
repeatedly called to make sure that the server started and that
it is operational. Hence, if the monitor operation does not
succeed within the start operation timeout, the apache resource
will end with an error status.
The monitor operation by default loads the server status page
which depends on the mod_status module and the corresponding
configuration file (usually /etc/apache2/mod_status.conf).
Make sure that the server status page works and that the access
is allowed *only* from localhost (address 127.0.0.1).
See the statusurl and testregex attributes for more details.
See also http://httpd.apache.org/
Resource options:
configfile (unique): The full pathname of the Apache configuration file. This file is parsed to provide defaults for various other resource agent parameters.
httpd: The full pathname of the httpd binary (optional).
port: A port number that we can probe for status information using the statusurl. This will default to the port number found in the configuration file, or 80, if none can be found in the configuration file.
statusurl: The URL to monitor (the apache server status page by default). If left unspecified, it will be inferred from the apache configuration file. If you set this, make sure that it succeeds *only* from the localhost (127.0.0.1).
Otherwise, it may happen that the cluster complains about the resource being active on multiple nodes.
testregex: Regular expression to match in the output of statusurl. Case insensitive.
client: Client to use to query to Apache. If not specified, the RA will try to find one on the system. Currently, wget and curl are supported. For example, you can set this parameter to "curl" if you prefer that to wget.
testurl: URL to test. If it does not start with "http", then it's considered to be relative to the Listen address.
testregex10: Regular expression to match in the output of testurl. Case insensitive.
testconffile: A file which contains test configuration. Could be useful if you have to check more than one web application or in case sensitive info should be passed as arguments (passwords). Furthermore, using a config file is the
only way to specify certain parameters. Please see README.webapps for examples and file description.
testname: Name of the test within the test configuration file.
options: Extra options to apply when starting apache. See man httpd(8).
envfiles: Files (one or more) which contain extra environment variables. If you want to prevent script from reading the default file, set this parameter to empty string.
use_ipv6: We will try to detect if the URL (for monitor) is IPv6, but if that doesn't work set this to true to enforce IPv6.
Default operations:
start: interval=0s timeout=40s
stop: interval=0s timeout=60s
monitor: interval=10s timeout=20s
[root@node1 ~]#
# 利用できるリソース名の確認(仮想IP)
[root@node1 ~]# pcs resource list | grep IPaddr2
ocf:heartbeat:IPaddr2 - Manages virtual IPv4 and IPv6 addresses (Linux specific
[root@node1 ~]#
# リソース登録(仮想IP)
[root@node1 ~]# pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.122.120 --group apachegroup
[root@node1 ~]#
# リソース登録(Apache)
[root@node1 ~]# pcs resource create WebSite ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://localhost/server-status" --group apachegroup
[root@node1 ~]#
# 状態確認
[root@node1 ~]# pcs status
Cluster name: my_cluster
Cluster Summary:
* Stack: corosync
* Current DC: z1.example.com (version 2.1.2-4.el8-ada5c3b36e2) - partition with quorum
* Last updated: Sat Jun 4 06:44:22 2022
* Last change: Sat Jun 4 06:43:56 2022 by root via cibadmin on z1.example.com
* 1 node configured
* 2 resource instances configured
Node List:
* Online: [ z1.example.com ]
Full List of Resources: ##追加されたセクション
* Resource Group: apachegroup:
* ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com
* WebSite (ocf::heartbeat:apache): Started z1.example.com
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
[root@node1 ~]#
7.Webサーバへのアクセス
ブラウザにて仮想IPからApacheへアクセスする。
「5.Apache設定」で設定した静的コンテンツが表示される。

8.リソース故障
apahce停止によりリソース故障を発生させて、故障時のクラスタ状態の確認をする。
# apahce停止
[root@node1 ~]# killall -9 httpd
[root@node1 ~]#
# 状態確認
[root@node1 ~]# pcs status
Cluster name: my_cluster
Cluster Summary:
* Stack: corosync
* Current DC: z1.example.com (version 2.1.2-4.el8-ada5c3b36e2) - partition with quorum
* Last updated: Sat Jun 4 06:56:33 2022
* Last change: Sat Jun 4 06:43:56 2022 by root via cibadmin on z1.example.com
* 1 node configured
* 2 resource instances configured
Node List:
* Online: [ z1.example.com ]
Full List of Resources:
* Resource Group: apachegroup:
* ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com
* WebSite (ocf::heartbeat:apache): Started z1.example.com
Failed Resource Actions: ##リソース異常が表示
* WebSite_monitor_10000 on z1.example.com 'not running' (7): call=13, status='complete', last-rc-change='Sat Jun 4 06:55:34 2022', queued=0ms, exec=0ms
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
[root@node1 ~]#
# 障害状態をリセット
[root@node1 ~]# pcs resource cleanup WebSite
Cleaned up ClusterIP on z1.example.com
Cleaned up WebSite on z1.example.com
Waiting for 1 reply from the controller
... got reply (done)
[root@node1 ~]#
# 状態確認
[root@node1 ~]# pcs status
Cluster name: my_cluster
Cluster Summary:
* Stack: corosync
* Current DC: z1.example.com (version 2.1.2-4.el8-ada5c3b36e2) - partition with quorum
* Last updated: Sat Jun 4 07:02:03 2022
* Last change: Sat Jun 4 07:01:00 2022 by hacluster via crmd on z1.example.com
* 1 node configured
* 2 resource instances configured
Node List:
* Online: [ z1.example.com ]
Full List of Resources:
* Resource Group: apachegroup:
* ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com
* WebSite (ocf::heartbeat:apache): Started z1.example.com
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
[root@node1 ~]
9.クラスタ停止
[root@node1 ~]# pcs cluster stop --all #片系クラスタの場合allはなくても問題ない
z1.example.com: Stopping Cluster (pacemaker)...
z1.example.com: Stopping Cluster (corosync)...
[root@node1 ~]#
[root@node1 ~]#
[root@node1 ~]# pcs status
Error: error running crm_mon, is pacemaker running?
crm_mon: Error: cluster is not available on this node
[root@node1 ~]#
参考
Discussion