Databricks Serverless Compute 完全ガイド - Notebook
Databricks Serverless Compute for Notebook 完全ガイド:開発とコスト管理のベストプラクティス
はじめに
データエンジニアリングの世界で、「クラスター起動の待ち時間」は誰もが一度は経験したことのある悩みではないでしょうか?急いで分析を始めたいのに、数分から十数分のクラスター起動を待つ必要があり、その間に集中力が途切れてしまった経験は多くの方にあるはずです。
Databricks の Serverless compute for notebook は、まさにそうした課題を解決する革新的な機能です。従来のClassic computeとは異なり、接続から数秒で利用可能になる高速性と、インフラ管理が完全に不要な利便性を提供します。
本記事では、2025年8月時点での最新情報をもとに、Serverless compute for notebookの導入から運用まで、開発者が知っておくべきすべてのポイントを詳しく解説します。
注意事項
本記事では一般的なServerless compute for notebookを扱い、Serverless GPU computeは対象外とします。また、仕様変更により記載内容と実際の機能が異なる場合がありますので、最新の公式情報もあわせてご確認ください。
Serverless compute for notebookとは?
従来の課題と解決策
従来のClassic computeでは、以下のような課題がありました:
- 起動時間の長さ: クラスター起動に数分〜十数分が必要
- インフラ管理の複雑さ: インスタンスタイプやスケーリング設定の管理
- コスト予測の困難さ: クラウドサービスとDatabricksで分かれた請求体系
- リソースの無駄: 使わない時間でもクラスターが起動していることによる課金
Serverless compute for notebookは、これらすべての課題を根本から解決します。

主要な特徴とメリット
即座の利用開始
接続ボタンを押してから数秒で利用可能。午前中のMTGが終わってすぐに分析を始めたい、といったアドホックなニーズに最適です。
ゼロインフラ管理
Databricksが管理するServerless compute plane上で動作するため、インフラ設定は不要。開発者はデータ分析とコードに集中できます。
統一された課金体系
VMのインフラ費用がDatabricksの利用料に含まれるため、複雑な請求書の解析から解放されます。
最適化されたワークロード対応
アドホックな分析や実験的な開発タスクに特化した設計で、データサイエンティストや分析者の日常業務にマッチします。
導入準備:要件と初期設定
利用要件チェックリスト
Serverless compute for notebookを使い始める前に、以下の要件を確認しましょう:
Unity Catalogの有効化
- WorkspaceでUnity Catalogが有効になっている必要があります
- まだ有効化していない場合は、Workspace管理者に確認してください
サポートリージョン
日本のユーザーは以下のリージョンで利用可能です:
- AWS: ap-northeast-1 (東京)
- Azure: japaneast (東日本)
- GCP: asia-northeast1 (東京)
Serverless computeの有効化
多くのアカウントで自動的に有効になっていますが、念のため確認してください。有効化は公式ドキュメントを参照してください。
セットアップ手順
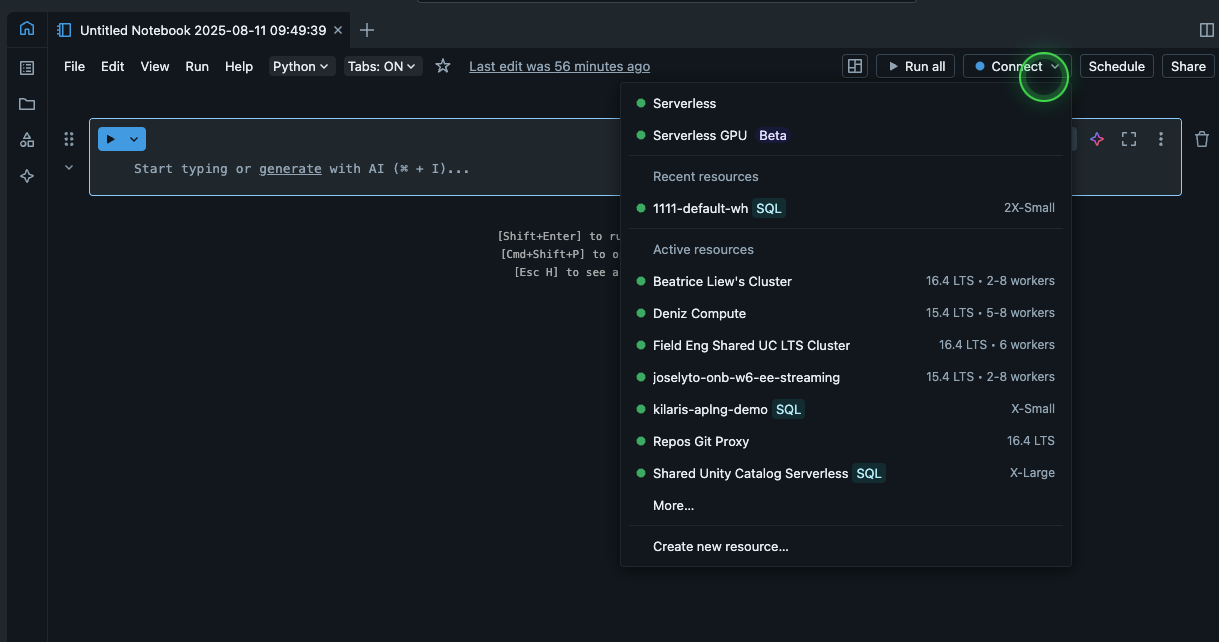
Step 1: Notebookでの接続設定
- Workspaceから新しいNotebookを作成
- 右上の「Connect」(日本語UIでは「接続」)をクリック
- 「Serverless」を選択
Step 2: Environment設定の詳細解説
「Environment」メニューから、用途に応じて以下の設定を調整できます:

Memory
REPL VM(SparkクラスターやGPUへの接続クライアントVM)のメモリサイズを指定します。分析するデータサイズに応じて調整しましょう。
Serverless budget policy
後述するコスト管理の要となる設定です。部署やプロジェクト別の予算管理に必須です。
Base environment
Python依存関係を定義するYAMLファイルのパスを指定。チーム全体で統一した環境を使いたい場合に活用します。
Environment version
Spark Connect APIのバージョンや環境依存関係を統一するためのバージョン指定。詳細はリリースノートを参照してください。
Dependencies
Base Environmentに加えて、ノートブック固有の追加Pythonパッケージをインストールできます。個人の実験的な分析に便利です。
実際の使用方法と開発Tips
基本的な使い方
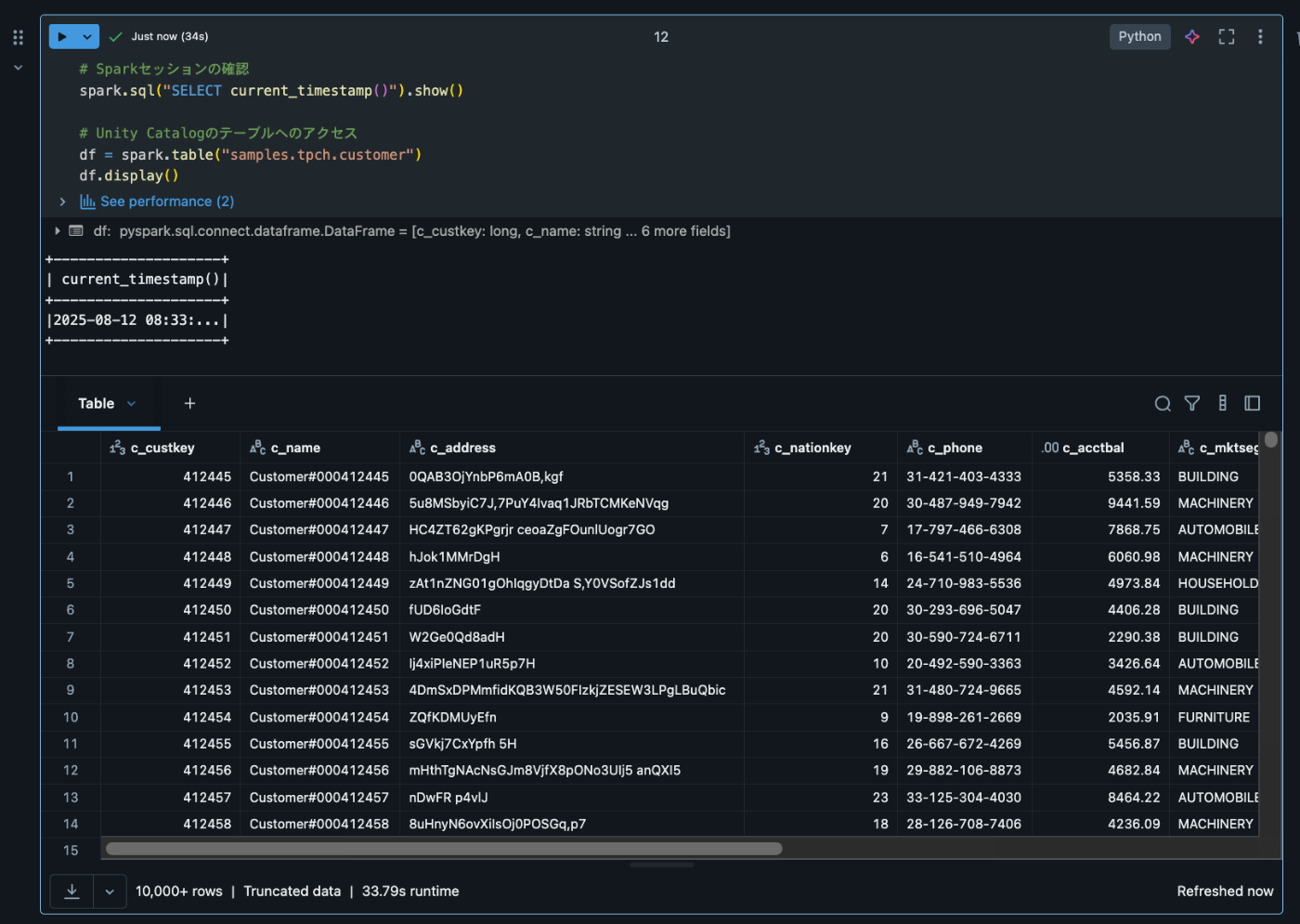
Classic computeと同様に、NotebookでSQLやPythonの操作が行えます。以下は簡単な使用例です:
# Sparkセッションの確認
spark.sql("SELECT current_timestamp()").show()
# Unity Catalogのテーブルへのアクセス
df = spark.table("catalog.schema.table_name")
df.display()
開発者向けのTips
Webターミナルの活用
従来通りWebターミナルの起動やログ取得が可能です。ただし、従来のSpark UIでのデバッグはできないため、パフォーマンス分析にはクエリプロファイルを用いた別のアプローチが必要です。
タイムアウト設定の管理
デフォルトで2.5時間の実行タイムアウトが設定されています。長時間実行が予想される処理では、以下のように設定を調整できます:
spark.conf.set("spark.databricks.execution.timeout", "4h")
コスト管理:賢く使うための戦略
Serverless computeの最大の利点の一つが、統一されたコスト管理です。しかし、適切な設定を行わないと思わぬコスト増加につながる可能性もあります。
コストの見積もりアプローチ
従来との違い
- Classic compute: クラウドサービス + Databricks の分離した請求
- Serverless compute: VMインフラ費用込みの統一請求
見積もりの実践的アプローチ
Serverless computeでは、バックエンドのSparkクラスターが完全にマネージドされているため、正確な見積もりには実測が最も重要です。
# 代表的なワークロードでの時間測定例
import time
start_time = time.time()
# 実際のワークロードを実行
result = spark.sql("""
SELECT department, AVG(salary)
FROM employee_data
GROUP BY department
""")
result.count() # アクションを実行してDBUを消費
end_time = time.time()
print(f"実行時間: {end_time - start_time:.2f}秒")
実測結果をもとに、月次・日次のDBU消費量を推定し、予算計画を立てることをお勧めします。
Serverless Budget Policyによるコスト制御
Policy作成の戦略的アプローチ
Serverless budget policyは単なるコスト制限ツールではなく、組織的なデータガバナンスの要です。
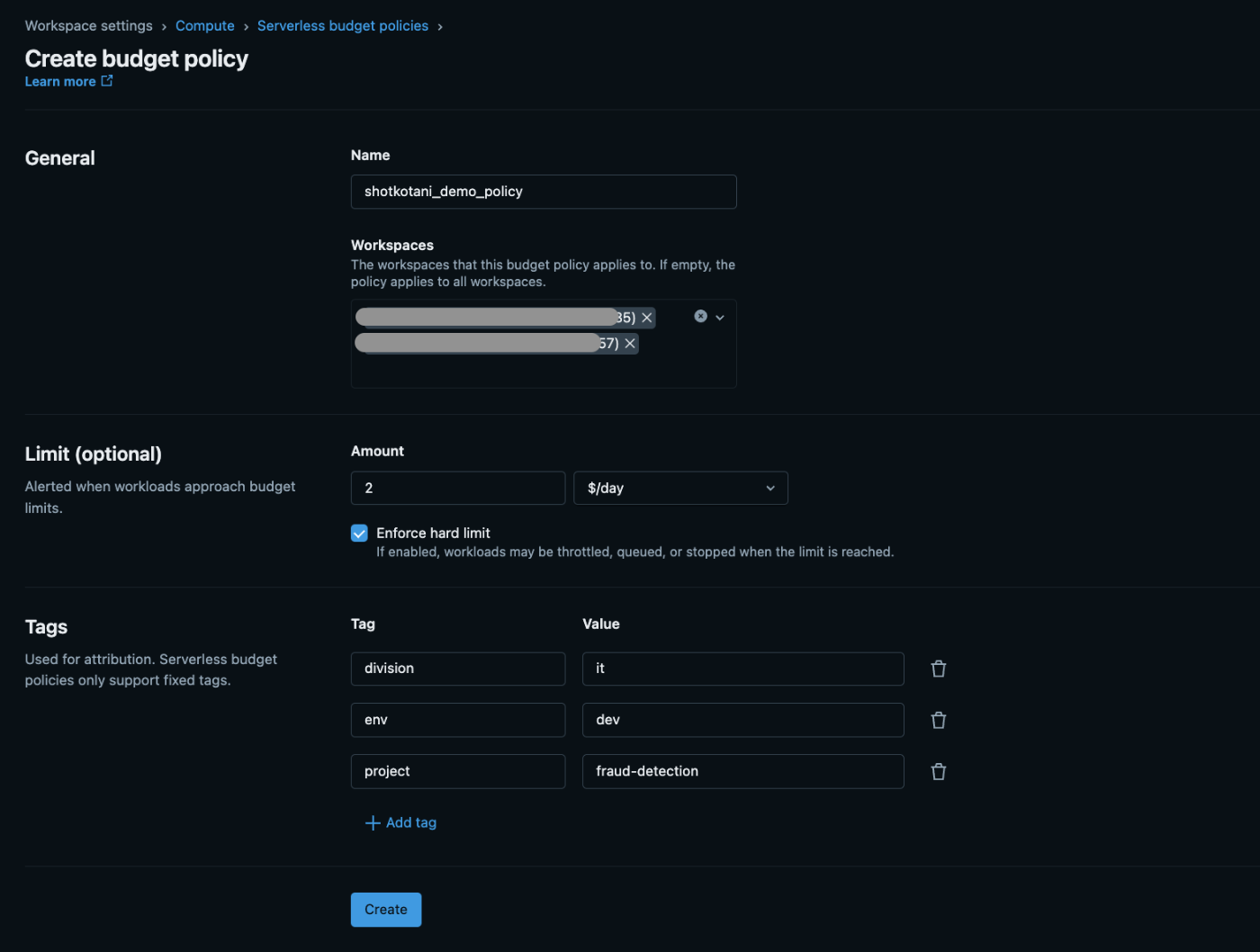
設定項目の詳細解説
General設定
-
Name: 部署やプロジェクトが分かりやすい命名(例:
data-team-q4-analysis) - Workspaces: 適用するワークスペースの選択
Limit設定(重要)
- Amount: $/dayでの使用限度額指定
-
Enforce hard limit:
- ✅ 有効: 制限到達時にワークロードが停止(本番運用推奨)
- ❌ 無効: 制限到達時にメール通知のみ(開発段階推奨)

Tag設定
コスト配賦とトラッキングの要となる設定です:
-- system.billing.usageでの検索例
SELECT
usage_date,
SUM(usage_quantity) as total_dbu,
custom_tags
FROM system.billing.usage
WHERE custom_tags['project'] = 'customer-analytics'
GROUP BY usage_date, custom_tags
ORDER BY usage_date DESC
実際の運用戦略
チーム別予算管理
例:データサイエンスチーム
- Policy名: ds-team-monthly-budget
- 日次限度額: $100
- Hard limit: 無効(実験的分析のため)
- Tag: {"team": "data-science", "cost-center": "analytics"}
プロジェクト別予算管理
例:四半期分析プロジェクト
- Policy名: q4-financial-analysis
- 日次限度額: $50
- Hard limit: 有効(明確な予算制約があるため)
- Tag: {"project": "q4-analysis", "department": "finance"}
Policy Usage Monitoring
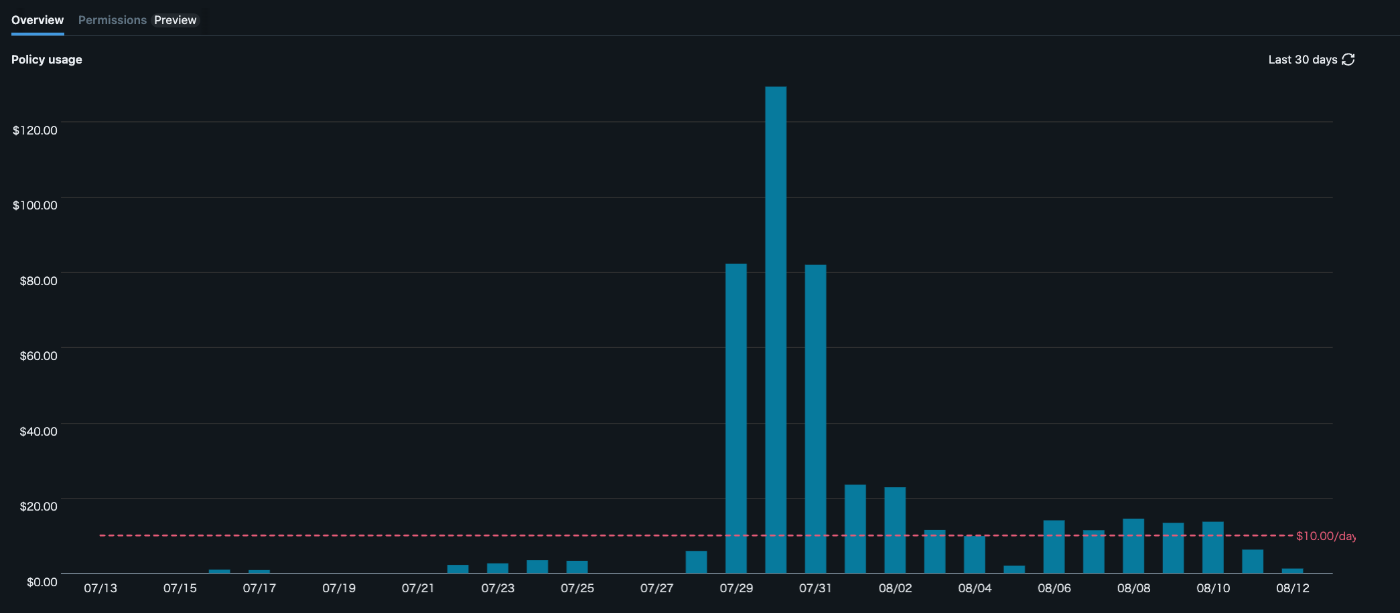
時系列グラフでPolicy Usageを確認できます。このデータを使って:
- 日次/週次の使用パターンの把握
- 予算超過リスクの早期発見
- チーム間でのリソース使用量比較
アクセス権限の戦略的管理
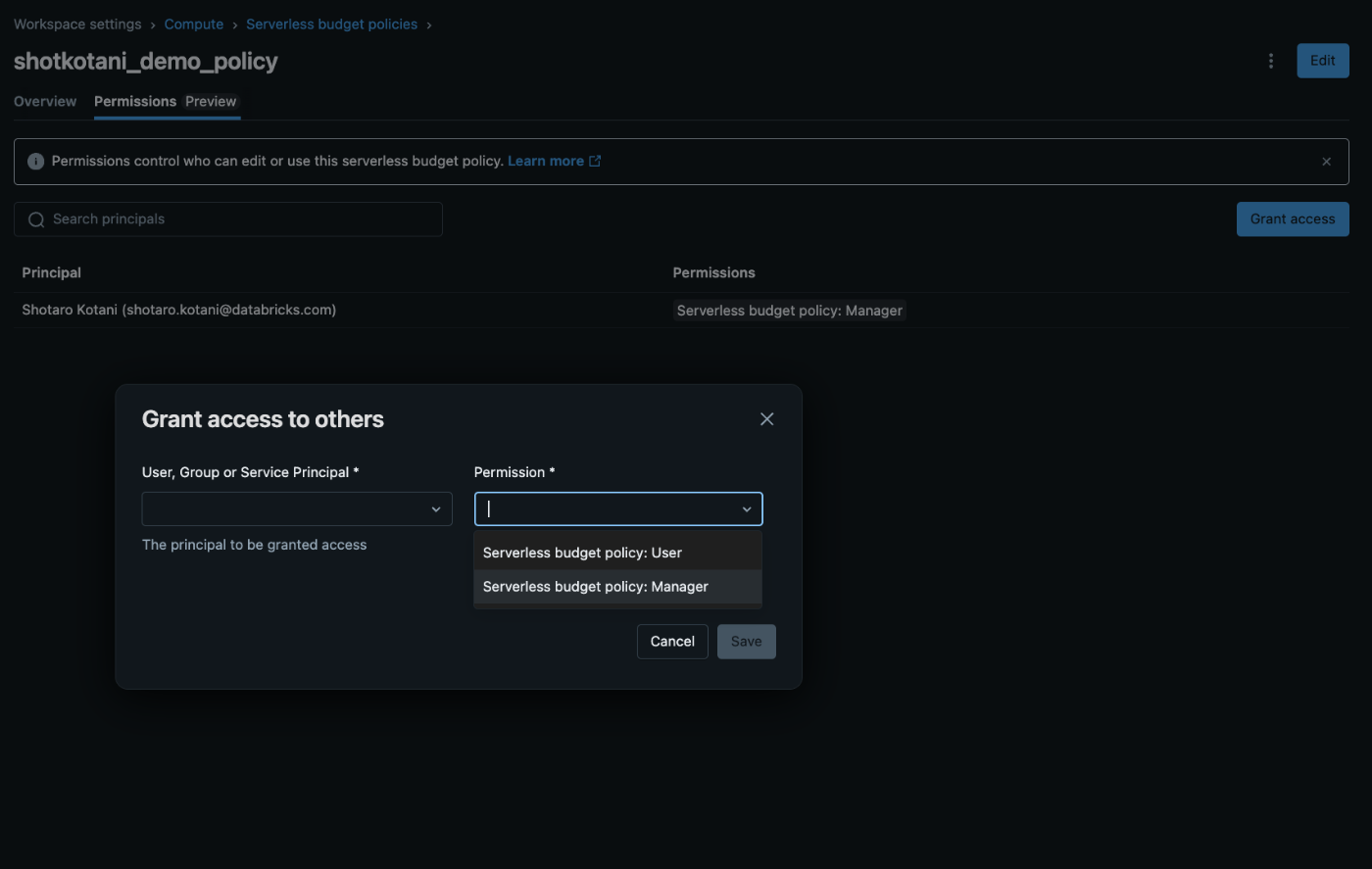
重要な注意点: 現在Serverless computeはデフォルトで「すべてのワークスペースユーザー」が利用可能です。コスト管理のためには、Policyを「Grant Access to others」でユーザーへ適切に割り当てることで、新規のNotebookでPolicyが自動適用されます。
権限設定のベストプラクティス
- 段階的権限付与: 新入社員は制限の厳しいPolicyから開始
- プロジェクトベース: プロジェクト期間に応じた一時的な権限付与
- 定期的な見直し: 四半期ごとの権限とコスト使用状況の確認
モニタリングとアラート設定
System Tables活用法
PolicyがNotebookに適用されると、system.billing.usageのcustom_tags列にTagが記録されます:
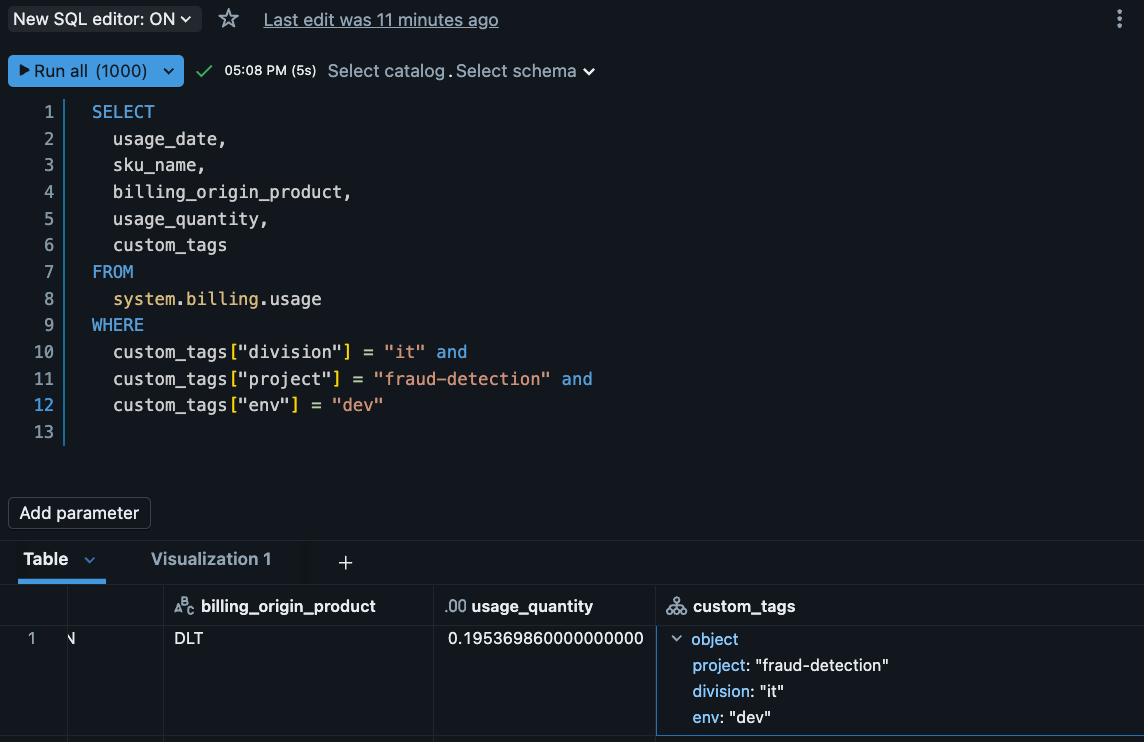
実践的なモニタリングクエリ
-- 日次コスト使用量の監視
SELECT
usage_date,
workspace_name,
SUM(usage_quantity) as daily_dbu,
custom_tags['team'] as team_name
FROM system.billing.usage
WHERE usage_date >= CURRENT_DATE() - INTERVAL 7 DAYS
AND sku_name LIKE '%SERVERLESS%'
GROUP BY usage_date, workspace_name, custom_tags['team']
ORDER BY usage_date DESC, daily_dbu DESC
-- 予算超過アラート用クエリ
SELECT
custom_tags['project'] as project_name,
SUM(usage_quantity) as current_usage,
CASE
WHEN SUM(usage_quantity) > 100 THEN 'WARNING'
WHEN SUM(usage_quantity) > 150 THEN 'CRITICAL'
ELSE 'OK'
END as status
FROM system.billing.usage
WHERE usage_date = CURRENT_DATE()
AND sku_name LIKE '%SERVERLESS%'
GROUP BY custom_tags['project']
HAVING SUM(usage_quantity) > 80 -- 80%閾値でアラート
アラート設定の実装
Databricks SQLを使って、上記クエリをベースとしたアラートを設定できます:
- 日次予算監視アラート: 予算の80%使用でWarning、100%で Critical
- 異常使用検知: 前日比200%以上の使用量増加を検知
- 週次レポート: チーム別の使用状況サマリー
Jobとの組み合わせ時の重要な仕様
重要: ノートブックがJobの一部として実行される場合、使用状況レコードにはJobsのServerless budget policyのみが適用されます。
この仕様により、開発時(ノートブック直接実行)と本番時(Job実行)で異なるコスト配賦が可能になります:
開発フェーズ: development-budget-policy → 開発部門に配賦
本番フェーズ: production-job-policy → 運用部門に配賦
開発環境の構築と最適化
Serverless compute for notebookでの開発を成功させるには、環境の安定性とチーム全体での一貫性が重要です。ここでは、実際の開発現場で活用できる具体的な手法を詳しく解説します。
開発環境の安定化戦略
Environment Versionによる環境統一
開発チームでの「動作環境の違い」による問題は、多くのデータプロジェクトで発生する課題です。Serverless computeでは、Environment Versionという仕組みで、この問題を根本的に解決できます。
各Environment Versionは、特定のPythonバージョンと厳密にバージョン固定されたPythonパッケージ群がセットになっています。つまり、チーム全体で同じEnvironment Versionを選択するだけで、「私の環境では動くのに...」という問題から完全に解放されます。

現在利用可能なEnvironment Version
| Environment Version | Python バージョン | OS | サポート終了 | Databricks Connect |
|---|---|---|---|---|
| 3 | 3.12.3 | Ubuntu 24 | 2028/6/13 | 16.3.2 |
| 2 | 3.11.10 | Ubuntu 22 | 2027/11/21 | 15.4.5 |
| 1 | 3.10.12 | Ubuntu 20 | 2027/3/12 | 14.3.0 |
推奨: 新規プロジェクトでは Environment Version 3 の使用をお勧めします。最新のPython 3.12.3と最長のサポート期間が魅力です。
Databricksは、Sparkサーバー側を独立してアップグレードしつつ、各Environment Versionとのユーザーワークロードにおける互換性を完全に維持します。これにより、「システムアップデートで急に動かなくなった」といった運用リスクを大幅に削減できます。
ローカル環境での再現方法
サーバーレス環境を自分のPCで再現したい場合は、以下の手順で実現できます:
# requirements-env-3.txtファイルをダウンロード
wget https://docs.databricks.com/en/_static/files/serverless/requirements-env-3.txt
# ローカル環境にインストール
pip install -r requirements-env-3.txt
Base Environmentによるチーム標準環境
さらに高度な環境管理として、Base Environmentの活用があります。これは、チーム固有の標準ライブラリや内製ツールを全員の環境に自動で組み込める機能です。

Base Environmentで使用するYAMLファイルは、MLflow Projectsの開発標準に基づいており、Databricks内でのMLOpsワークロードとシームレスに統合されます。
実際の設定例
# team-standard-environment.yaml
# データサイエンスチーム標準環境設定ファイル
environment_version: '3'
dependencies:
- --index-url https://pypi.org/simple
# チーム共通の要件ファイル
- -r "/Workspace/Shared/ds-team/requirements.txt"
# 特定バージョンのライブラリ指定
- pandas==2.1.4
- scikit-learn==1.3.2
# 内製ライブラリのwheel
- /Workspace/Shared/libs/company-analytics-1.2.0-py3-none-any.whl
# GitHubからの直接インストール
- git+https://github.com/company/internal-ml-tools
活用シーン
- 企業内の標準ライブラリ: 内製の分析ツールやユーティリティ
- プロジェクト固有の依存関係: 特定のMLモデルで必要な専門ライブラリ
- セキュリティ承認済みパッケージ: IT部門で検証されたライブラリのみの使用
パフォーマンス最適化の新しいアプローチ
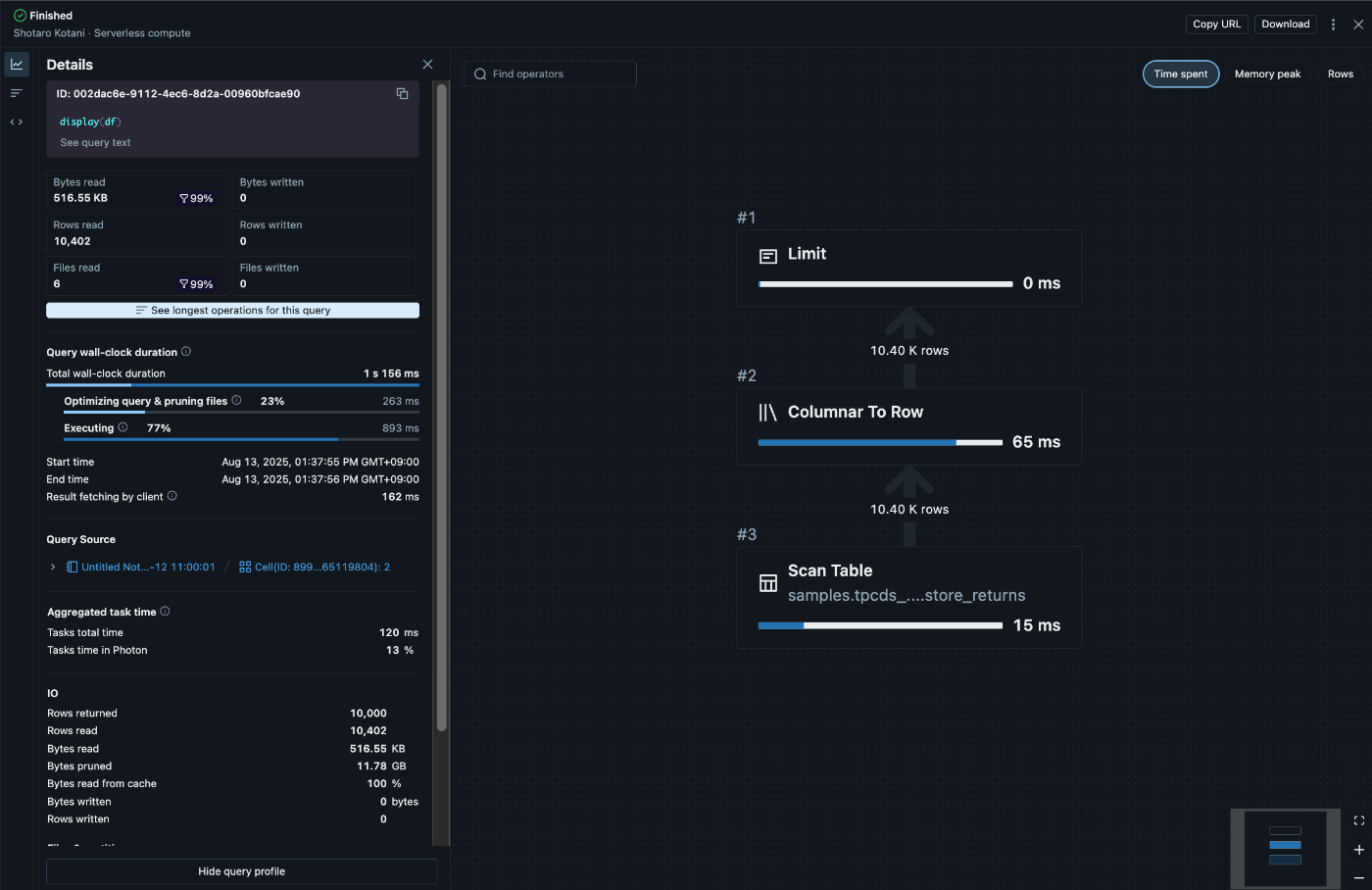
クエリプロファイルを活用したパフォーマンス分析
従来のServerless computeのもどかしさの一つに、「Spark UIやGangliaが使えない」ことがありました。多くのSpark開発者にとって、これらのツールはパフォーマンスチューニングの必須アイテムでした。
しかし、Serverless computeでは、クエリプロファイルという新しいアプローチでパフォーマンス分析が可能です。これは従来SQL Warehouse限定の機能でしたが、Notebook開発でPySparkを使用する際にも利用できるようになりました。

クエリプロファイルで確認できる項目
- 実行時間の詳細分析: クエリの各段階での時間消費
- メモリ使用パターン: データのスピル発生状況
- シャッフル操作の効率性: パーティション間のデータ移動
- 並列度の最適性: タスク分散の状況
データエンジニアリングのベストプラクティス
外部データソース接続の戦略的アプローチ
Serverless computeには一つの重要な制約があります:JARファイルのインストールがサポートされていないことです。これは、従来のJDBCドライバーやODBCドライバーを使用した外部データソースとの接続ができないことを意味します。
しかし、この制約を理解した上で、より効率的なデータ取り込み戦略を採用することで、むしろ運用負荷を削減できます。
推奨されるデータ取り込み手法
COPY INTOによるバルクロード
-- COPY INTOを使用したバルクデータ取り込み
COPY INTO target_table
FROM '/mnt/data-lake/sales-data/'
FILEFORMAT = PARQUET
FORMAT_OPTIONS ('mergeSchema' = 'true')
COPY_OPTIONS ('mergeSchema' = 'true');
-- ストリーミングテーブルによるリアルタイム取り込み
CREATE OR REFRESH STREAMING TABLE live_sales_data
AS SELECT
*,
current_timestamp() as ingestion_time
FROM STREAM('/mnt/streaming/sales-events/');
Auto Loaderによる増分処理
Auto Loaderは、クラウドストレージに新しいデータファイルが到着した際に、段階的かつ効率的に処理できる画期的な機能です。
# Auto Loaderの設定例
def setup_autoloader_stream():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.schemaLocation", "/mnt/schemas/events/")
.option("cloudFiles.inferColumnTypes", "true")
.load("/mnt/incoming/event-data/")
.writeStream
.option("checkpointLocation", "/mnt/checkpoints/events/")
.option("mergeSchema", "true")
.table("bronze.raw_events"))
# ストリーミング開始
stream = setup_autoloader_stream()
Auto Loaderの利点
- 自動スキーマ推論: 新しいカラムの自動検出と追加
- 増分処理: 新規ファイルのみを効率的に処理
- エラー処理: 不正なファイルの自動隔離と再処理
データ取り込みパートナーソリューション
企業レベルでのデータ統合には、Databricksの認定パートナーソリューションの活用も有効です:
- Trocco
- Fivetran
- CData
IDEからのリモート開発環境
Databricks Connectによる快適な開発体験
多くのデータエンジニアやデータサイエンティストにとって、使い慣れたIDEでの開発は生産性に大きく影響します。Databricks Connectを使用することで、PyCharmやVS CodeなどのローカルIDEから、Serverless notebook computeに対話的に接続し、コードの一行ずつ実行・デバッグが可能になります。

設定手順
# 1. Databricks Connectのインストール
pip install databricks-connect
# 2. 接続設定の初期化
databricks-connect configure
# 3. 接続テスト
databricks-connect test
実際の開発フロー
# VS Codeでの開発例
from databricks.connect import DatabricksSession
# Serverless computeへの接続
spark = DatabricksSession.builder.getOrCreate()
# ローカルIDEでのインタラクティブ開発
df = spark.table("sales_data")
df.show(5) # 結果はローカルIDE上に表示
# デバッグポイントの設定も可能
breakpoint() # ここでデバッガが起動
開発効率化のメリット
- フルデバッガサポート: ブレークポイント、変数監視、ステップ実行
- インテリセンス: IDE固有のコード補完と構文チェック
- Gitワークフロー: ローカルでのバージョン管理とCI/CD統合
- 高速イテレーション: ノートブックの再読み込み不要
詳細な設定手順については、Databricks公式チュートリアルをご参照ください。
既存ワークロードからの移行
ユーザコードの分離を保護するために、サーバレス コンピュート Databricks セキュア標準アクセスモード (以前の共有アクセスモード) を利用しています。 このため、一部のワークロードでは、サーバレス コンピュートで作業を続けるためにコードの変更が必要になります。 サポートされていない機能のリストについては、 サーバレス コンピュートの制限事項を参照してください。
本記事の内容についてご質問や追加情報のご要望がございましたら、コメント欄でお気軽にお聞かせください。Databricksの最新情報については、公式ドキュメントも併せてご確認ください。
Discussion