この記事の概要
こんにちは。PharmaX でエンジニアをしている諸岡(@hakoten)です。
この記事では、YOJO事業部で使用しているバックエンドアプリケーション(Ruby on Rails)において、LLM(Large Language Models)のAPIをどのように取り扱っているのかについて、システム構成の観点から解説しています。
LLMを用いて実現している具体的な機能については詳しく触れていませんので、その点ご理解ください。
YOJOにおけるLLMを活用した機能の概要
まず、簡単ではありますが、YOJOというサービスの概要とYOJOにおけるLLMの立ち位置を説明します。
YOJOは、オンラインで薬剤師に相談し、医薬品を購入できるtoC(顧客向け)サービスです。
YOJOプロダクトでは、LLMを積極的にプロダクトの機能に活用しています。例えば、薬剤師が患者からの質問に答える際に、LLMで生成された文を含むチャットのサジェスト機能がその一つです。

例: 開発環境でチャットのサジェスト文を表示している図
チャットのサジェスト機能はフロントエンドの機能ですが、LLMはフロントエンドだけでなく、バックエンドでも活用しており、システムメッセージの送信条件の判定、会話の分類など、チャット文字列生成以外の機能としても使われています。
| 使用環境 | LLMの活用例 |
|---|---|
| 薬剤師向けアプリケーション | 患者へのメッセージサジェスト |
| バックエンドシステム | システムメッセージの送信条件判定 |
本記事は、このバックエンドにおけるLLMのAPIの取り扱いに焦点を当て記載しています。
システム概要
詳細は割愛しますが、簡単にYOJOのバックエンドの構成について説明します。
YOJOでは患者さんからの相談をLINEで受け、薬剤師が様々な相談にのるための薬剤師アプリケーションが存在します。これらを簡単にまとめると次のようになっています。(実際にはもう少し複雑な構成をしています)

図: システムの概要
※ YOJOのバックエンドシステムは、Google Cloudを使用して構築されており、アプリケーションは主にRuby on Railsで開発されています。
| アプリケーション | 機能説明 |
|---|---|
| LINEメッセージ受信 | LINEサーバーからのメッセージを受け取り、システムに登録する |
| LINEメッセージ処理 | 患者様からのLINEメッセージを受け取り、適切に処理する |
| 内部API | 薬剤師アプリケーションのための内部APIを処理する |
| 非同期ワーカー | 重い処理や非同期処理を行うためのアプリケーション |
主な処理フローとしては、「患者様から薬剤師へ」「薬剤師から患者様へ」の2つの業務フローが存在します。非同期処理については、Sidekiqのワーカーサーバーで対応しています。
LLMの環境
YOJOで使用しているLLMとその周辺ツールについてご紹介します。
モデル・API
現在、YOJOではOpenAIのChat APIを主要なリソースとして活用しており、状況に応じてGPT-3.5またはGPT-4のモデルを使用しています。
※具体的なモデルのバージョンについては省略します。
PromptLayerによる実験管理
また、LLMにおける開発ツールチェーンとして、PromptLayerというSaaSを導入し、プロンプトの実験管理を行っています。
開発ツールチェーンとして、PromptLayerというSaaSを導入し、プロンプトの実験管理を行っています。
実験管理の詳細については、当社の上野が書いた以下の記事をぜひご一読ください。
YOJOにおけるLLM APIの運用上の課題
YOJOのバックエンドでLLMをどのように扱っているかを説明する前に、まずLLM APIを扱う際に直面している主な課題について触れておきます。LLM自体の精度や性能に関する問題を除くと、現在の最大の課題は「APIの応答速度の遅さ」です。
OpenAIのGPT-4モデルを主に利用していることも一因ですが、2024年の現時点で、APIを介してLLMをプロダクトに採用している多くの企業は速度の問題を感じているのではないでしょうか。
具体的にYOJOの機能においては、GPT-3.5を使用した場合でも応答に数秒かかり、GPT-4を利用すると10秒近く待つことも珍しくありません。これは、数十ミリ秒から数百ミリ秒で応答する一般的なWebAPIと比較すると、非常に遅い処理といえます。
LLMが遅いということを前提に考えるべきこと
LLMの応答速度の遅さを考慮すると、前提として次のような点に注意する必要があります。
適切な非同期処理
LLMのように処理に数秒を要する場合、同期的なレスポンスを返すことは現実的ではありません。フロントエンドであれば、チャット生成のようにストリーミング処理を選択する方法もありますが、バックエンドにおいては、LLMの応答を直接ユーザーに返すことが主目的でない場合、処理を非同期にする必要があります。
他タスクとの隔離
LLM処理は数秒単位でかかるため、他のミリ秒単位で応答するタスクを担うワーカーとは隔離するか、適切な優先度制御が必要です。
割り込み処理の考慮
LLMをアプリケーション機能の一部として考える場合に、LLM処理に数秒を要することを前提とし、その間にユーザーが他の操作を行う可能性を考慮する必要があります。
例えば、ユーザーのアクションに基づくLLMによる判定処理中に、ユーザーが別の操作を行い前回の処理が無効になるといったケースが考えられます。
そのため最終的な結果処理の際に、割り込みが発生している可能性を考慮する必要があります。
バッチ処理のように扱う
これらの点は、アプリケーション開発では一般的な考慮事項ではあり、バッチ処理や時間が掛かる処理を行う際によく遭遇する課題です。結局のところ、時間がかかってしまうLLMの処理は現時点ではバッチ処理のような認識で扱うのが良さそうだと考えています。
課題を解決するための構成
ここまでの課題を踏まえ、YOJOのバックエンドでは、次のようなシステム構成を採用しています。
ワーカーサーバーの非同期処理
LINEや薬剤師向けアプリケーションからのリクエストは同期的に受け取るものの、LLMに関連する処理はSidekiqを利用して非同期に実行されるように設計しています。

LLM処理のトランザクション管理
ワーカーサーバーで実行されるLLM処理は、トランザクション単位で管理されます。これにより、各処理の状態管理を明確にし、処理の整合性を保つよう設計しています。
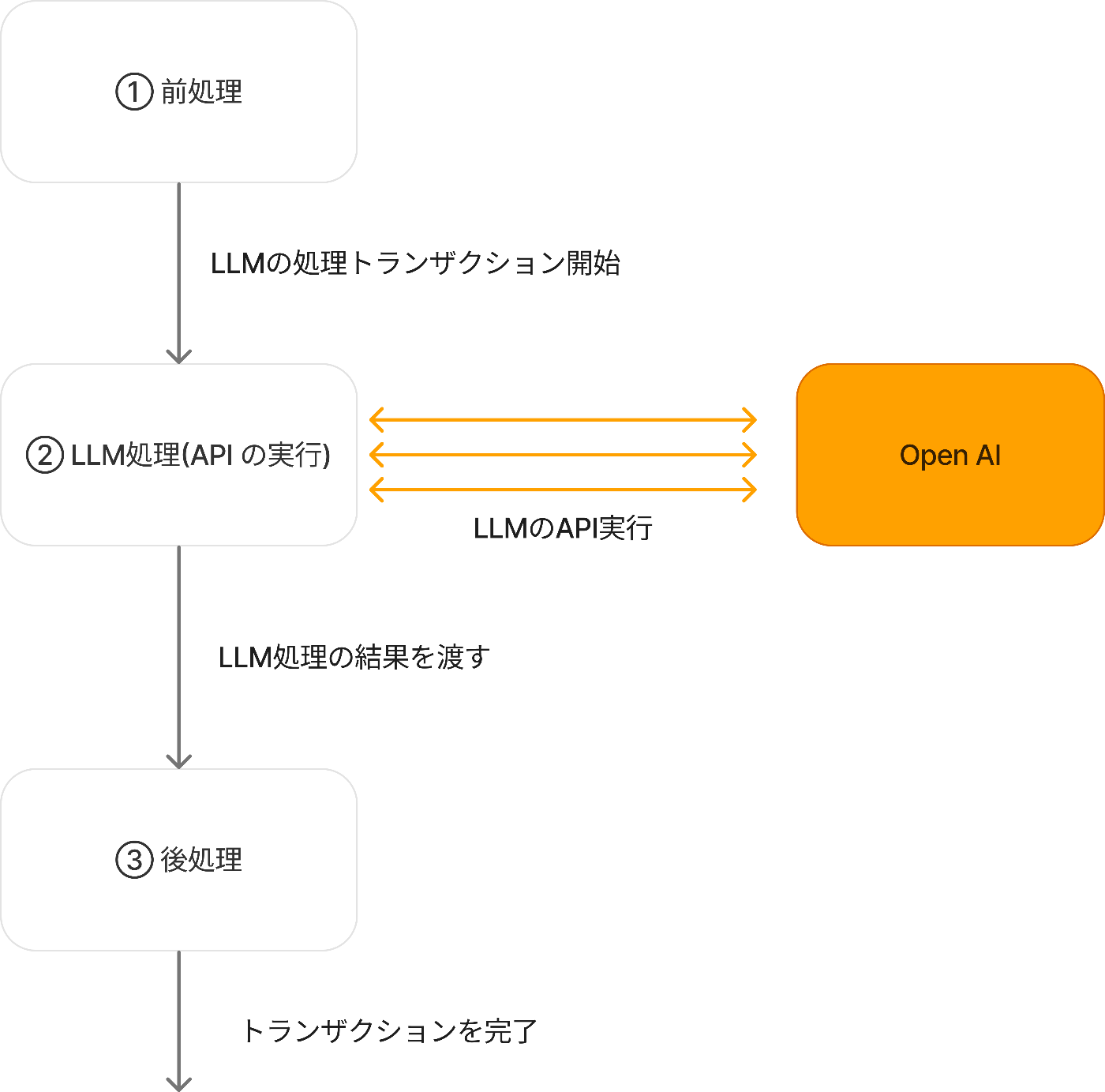
前処理
前処理では、患者さんとのやり取りやその他の状況を分析し、LLMジョブの実行が適切かを判断します。ジョブが実行されると、初めに現在の状態を確認し、それに基づいてLLMトランザクションを発行し、処理を開始します。
LLM処理
トランザクションが開始されると、LLMのAPIが実行されます。一つのユースケースに対して複数回のAPI呼び出しが発生する場合があり、一回の呼び出しには数秒掛かることが多いため、全体の処理時間は、場合によっては1分程度に及ぶこともあります。
LLMの実行結果はトランザクションに逐次記録され、進行状況を追跡できるようになっています。
後処理
LLMからのAPI応答を基に、最終的なアクションを決定します。例えば、特定のシステムメッセージを患者さんに送信する場合、LLM処理では送信の可否を判断する情報のみを取得し、実際の送信処理は後処理で行います。
完了時のアクションを後処理に分離する目的は「状態の不整合」を防ぐことです。
LLMの処理は非常に遅いため、状況によっては前回実行されているトランザクションが完了していない場合や、既に後続のトランザクションが実行されているケースが考えられます。後処理ではこのような現在のトランザクション状況も踏まえて、完了時のアクションを実行すべきかを判断しています。
トランザクションで管理される情報
トランザクションでは以下のような情報が管理され、これらはデータベースに保存されます。
| 情報 | 説明 |
|---|---|
| ユーザー情報 | 対象のユーザーを特定するための情報 |
| ユースケースの種類 | どのようなユースケースの処理か |
| 完了時のアクション | ジョブ完了時に実行されるアクション |
| ステータス | アクション実行後の結果(成功/失敗/キャンセル等) |
例えば、あるユーザーのためにシステムメッセージ送信を制御するジョブがある場合、次のようなレコードが作成されます。
| 情報 | 格納される値のイメージ |
|---|---|
| ユーザー情報 | User ID = 1 |
| ユースケースの種類 | 〇〇システムメッセージの送信制御 |
| 完了時のアクション | メッセージ送信(※メッセージ内容は別途管理されています) |
| ステータス | 成功 |
シーケンス例
簡単ではありますが、シーケンスの例を記載します。
まとめ
紹介したフローは、LLM特有のものではなく、一般的なジョブ処理における状態管理に近いと思います。
ポイントとしては「LLMは非常に遅いAPIである」ことを理解することで、状態管理を慎重に行うことが重要です。
将来的にLLMのインターフェースがWeb APIからローカルモデルへの移行や、処理速度が向上した場合はアーキテクチャの見直しが必要になるかもしれませんが、現時点では、OpenAIのLLMを主に使用しているYOJOにおいては、このようなアプローチを採用しています。
また、この記事ではLLMの結果の取り扱いについては詳しくは触れませんでした。基本的にはLLMから結果が正しく受け取れることを前提に書いています。
LLMの結果をシステムインタフェースにどのように組み込むかという観点も面白いトピックだと思いますので、また別の機会でご紹介できればと思います。
終わりに
PharmaX では、様々なバックグラウンドを持つエンジニアの採用をお待ちしております。
LLM関連の開発に興味がある方もぜひ気軽にお声がけください。
もし、興味をお持ちの場合は、私の X アカウント(@hakoten)や記事のコメントにお気軽にメッセージいただけますと幸いです。まずはカジュアルにお話できれば嬉しいです!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion