この記事はnoteから移行しました。
こんにちは!PharmaX共同創業者の上野(@ueeeeniki)です!この記事は、PharmaXの2023年アドベントカレンダー前夜祭と題してフライングで発信します。
今回は、2023年11月6日に行われたOpenAI DevDeyで発表されたGPT-4 Turboを使用する上での注意点をまとめたいと思います。特にGPT-4 Turbo周りは混乱を招くところだと思うので、自分も理解に苦労しました。
今回は、特に自分が騙されたところを中心に、一人でも勘違いする人が減ることを目指して書いていきたいと思います。
サービスが爆速でリリースされていく企業のサービス名や使い分けがややこしくなっていくのは世の常ですが、OpenAIも例に漏れずと言ったところでしょうか 笑
特に今回、一番覚えて帰っていただきたいのは、GPT-4 Turbo(モデル名はgpt-4-1106-preview)とGPT-4 Turbo with vision(モデル名はgpt-4-vision-preview)は別物ということです。
このため、GPT-4 Turbo with visionでは、JSONモードが使えないなどの不便な点がいくつかあります。
それでは早速注意点をまとめていきます。
はじめに:GPT-4 Turboとは?
GPT-4 Turboは、2023/11/6のDevDayでpreview版が発表されたOpenAIの新モデルです。最大トークン数が128,000トークンに拡大され、APIの値段も従来よりも大幅に安くなるなど、世界中を驚愕させました。
また、GPT-4Vという機能で、2023年9月25日からChatGPT内で使えるようになった画像認識機能が、GPT-4 Turbo with visionというAPIでも使えるようになったということでも大きな話題を呼んでいました。
このGPT-4 Turbo関連のAPIは非常にややこしいため、特に注意して頂きたいポイントを中心に解説していきたいと思います。
大前提:GPT-4 TurboとGPT-4 Turbo with visionは別物
まず大前提ですが、
-
GPT-4 Turbo:モデル名はgpt-4-1106-preview
-
GPT-4 Turbo with vision:モデル名はgpt-4-vision-preview
は、現時点では全くの別物です。当然、APIでモデルを指定するときのモデル名も異なるので注意が必要です。GPT-4 Turboの公式ドキュメントから引用した画像を以下に示します。

GPT-4 TurboとGPT-4 Turbo with visionは別物
GPT-4 TurboとGPT-4 Turbo with visionではAPIの形式も全く異なる
GPT-4 TurboはJSONモードなどの新機能が追加されたものの、APIの形式はこれまでと大きくは異なりません。
一方、当たり前ですが、GPT-4 Turbo with visionのAPIには画像を与えることができます。下記のようにtypeでimage_urlを指定して与えるなど、APIの形がこれまでと大きく異なります。(今後コードの引用は画像と文字列の両方を展開します)
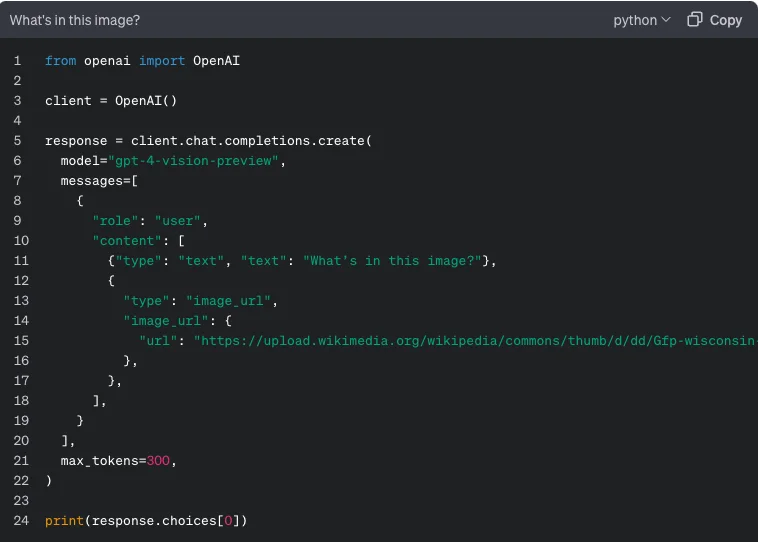
公式ドキュメントから引用
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
このようにあくまでChatCompletionの形式でありながら、contentに配列を指定できるようになり、typeでtextかimage_urlのどちらかを指定できるようになりました。image_urlには、OpenAIがアクセスできる公開URLを指定する必要があります。
試しにただのGPT-4 Turboの方にwith visionと同じようにcontentを配列にしてimage_urlを与えると、下記のようなエラーが返ってきました。
openai.BadRequestError: Error code: 400 - {'error': {'message': 'Invalid content type. image_url is only supported by certain models.', 'type': 'invalid_request_error', 'param': 'messages.[0].content.[1].type', 'code': None}}
(モデルをgpt-4-1106-previewにしてvision用のリクエストをすると返却されるエラーメッセージ)
ちなみに、base64形式で画像を与えたい人のために下記のようにurlにbase64の文字列を与えることも可能です。
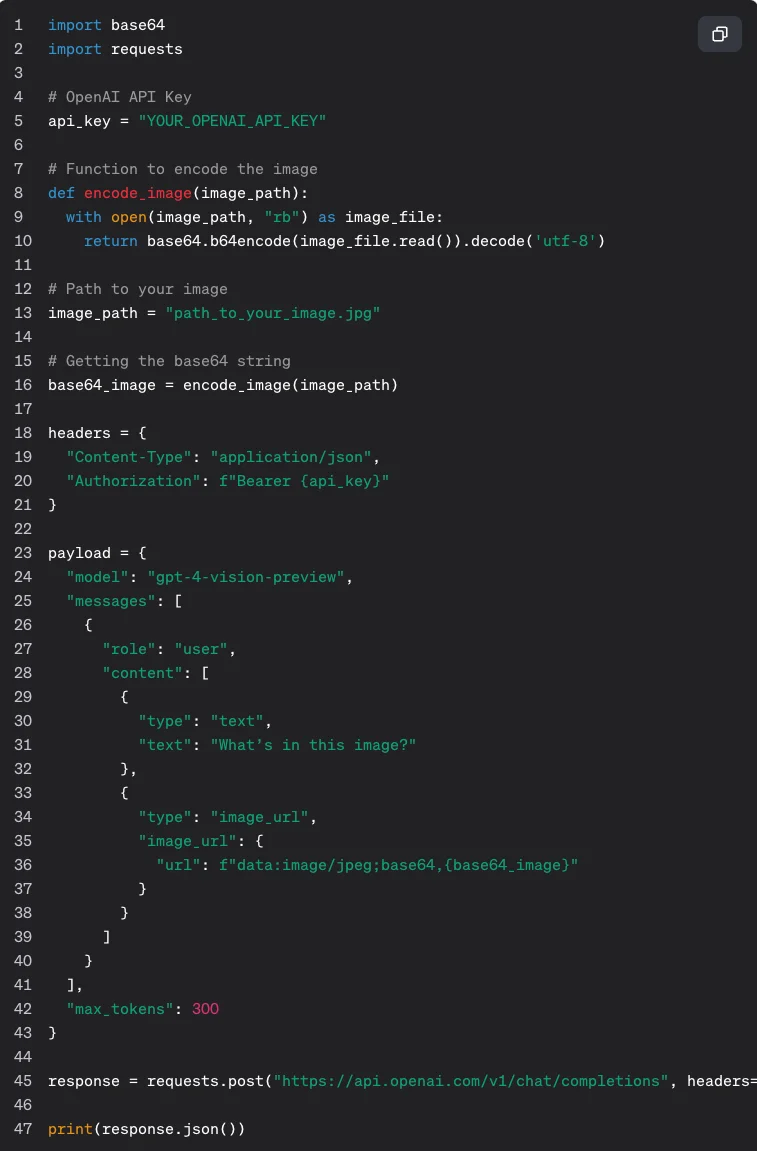
import base64
import requests
# OpenAI API Key
api_key = "YOUR_OPENAI_API_KEY"
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
image_path = "path_to_your_image.jpg"
# Getting the base64 string
base64_image = encode_image(image_path)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What’s in this image?"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 300
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
print(response.json())
GPT-4 TurboとGPT-4 Turbo with visionはいずれ統合される
OpenAIは、GPT-4 TurboとGPT-4 Turbo with visionは、GPT-4 Turboの正式版リリースと共に統合されるとしています。現状プレビュー版だからAPIは別れているけれども、本来のGPT-4 Turboそのものは、マルチモーダルを指向していると言いたいのでしょう。しかし、直近のOpenAIのゴタゴタから正式版のリリースは遅れるのではないかと思っています(あくまで個人的な予測です)。
GPT-4 Turbo with visionの使用上の注意点まとめ
これまでの説明でなんとなく予想できたかもしれませんが、GPT-4 Turbo with visionの方に特に注意が多いので、ここでまとめていきたいと思います。
①:function-callingやJSONモードは使えない
GPT-4 Turbo with visionの公式ドキュメントをよく見ると、GPT-4 TurboやChatGPTでは使える一部の機能が使えないという衝撃の事実が目に飛び込んできます。個人的にはこれがかなりのショックでした。GPT-4 Turbo with visionは、せっかくのマルチモーダルAPIなのに、できることが限られてしまうということです。特に、JSONモードが使えないのが一番悲しかったです。
Currently, GPT-4 Turbo with vision does not support the message.name parameter, functions/tools, response_format parameter, and we currently set a low max_tokens default which you can override.
PharmaXでは、過去の記事(『[LLM PoC]LLMによる疑義照会の半自動化PoC』)でも、画像からOCRでテキスト情報を抽出して、GPTでJSON化するという使い方を紹介していてきました。GPTそのものがマルチモーダル化してくれれば、OCR用の処理を一度挟まなくとも、①GPTで画像から文字の抽出→②文字から必要な情報をJSON化して抽出というステップを1つのAPIにまとめられるのではと期待したので非常に残念でした。
また、GPT-4 Turbo with visionは、デフォルトでは、max_tokensが300トークンとかなり制限されているため注意が必要です。日本語だと非常に短い文章なので使い物になりません。これまでGPTのAPIの開発をしてきた方には馴染みがあるかと思いますが、max_tokesという変数を指定して上書きする必要があります。
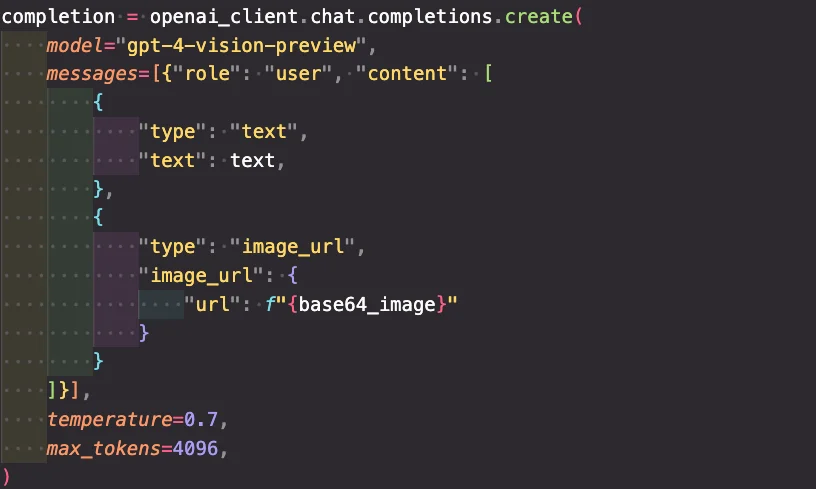
max_tokensを指定すれば上書き可能
②:ChatGPTでは対応しているファイル形式のほとんど(PDFなど)にAPIは対応していない
こちらも衝撃の事実だったのですが、なんとAPIでは、PNG、JPEG、WEBP、GIFの形式のファイルしか使用することができません。公式ドキュメントのFAQからの引用を下記に示します。PDFなどのメジャーなファイル形式すらサポートしていません。
We currently support PNG (.png), JPEG (.jpeg and .jpg), WEBP (.webp), and non-animated GIF (.gif).
(PNG、JPEG、WEBP、GIFの形式のファイルしか使用できない)
ChatGPTでは、PDFも問題なく使えていたので、個人的にはこれが非常にショックでした。
(PharmaXでは、泣く泣くPDFを一度PNGかJPEGに変換して使用しており、Rustで画像フォーマットを変換する方法を下記の記事で紹介しています。)
③:日本語は苦手
悲しいことに、日本語の文字が書かれた画像は苦手のようです。
Non-English: The model may not perform optimally when handling images with text of non-Latin alphabets, such as Japanese or Korean.
(非英語について:日本語や韓国語など、ラテン文字以外のテキストを含む画像を処理する場合、モデルが最適に動作しない可能性があります。)
ただ、個人的に試してみている範囲内では、そこまで大きな問題はなさそうです。手書き文字とかを試しているわけではないですが、日本語でも画質が高ければある程度は使えそうな気がしています。
④:その他の注意点
その他、個人的に注目したいGPT-4 Turbo with visionの注意点を羅列したいと思います。
-
アップロードできる画像は20MBまで
-
イメージは生成出来ない、生成したいならDALLE-3を使え
-
画像にメタデータは付与できない(メタデータは解釈できない)
(これらは公式ドキュメントのFAQに記載されています。)
これ以上多くは語りませんが、特に上記の3つに注意いただければ、これ以上大きな混乱は招かないと思います。
最後に
今回は、2023/11/6のDevDay以降の開発で特に困ったポイントであるGPT-4 TurboとGPT-4 Turbo with visionの違いについて解説しました。
そもそもGPT-4 TurboとGPT-4 Turbo with visionが違うものだあると認識するのも一苦労だったので、同じように勘違いしている&困っている人がいるのではないかと考え、筆を執りました。
DevDayでの発表内容によって、変更を迫られて点や困ったポイント、逆に嬉しかったポイントなどは下記の勉強会でも取り上げました。
今後もLLMについて一人でも多くの方の参考になる内容を発信していきたいと思います。今回の記事でも、みなさんのLLMライフがより快適なものになれば嬉しいです。

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion