この記事の概要
こんにちは。PharmaX でエンジニアをしている諸岡(@hakoten)です。
本記事では、Google Cloud上で Cloud Storageへアップロードされたログファイルを「Dataflow」というサービスを使用してBigQueryへ転送する方法についてご紹介します。
データパイプラインの構築や、Dataflowのサービスに興味がある方は、ぜひご覧ください。
今回作成するデータパイプラインの説明
弊社サービスでは、アプリケーションログをBigQueryへ転送し、データ分析を行っています。そのためのデータパイプラインは大まかに以下のようになります。
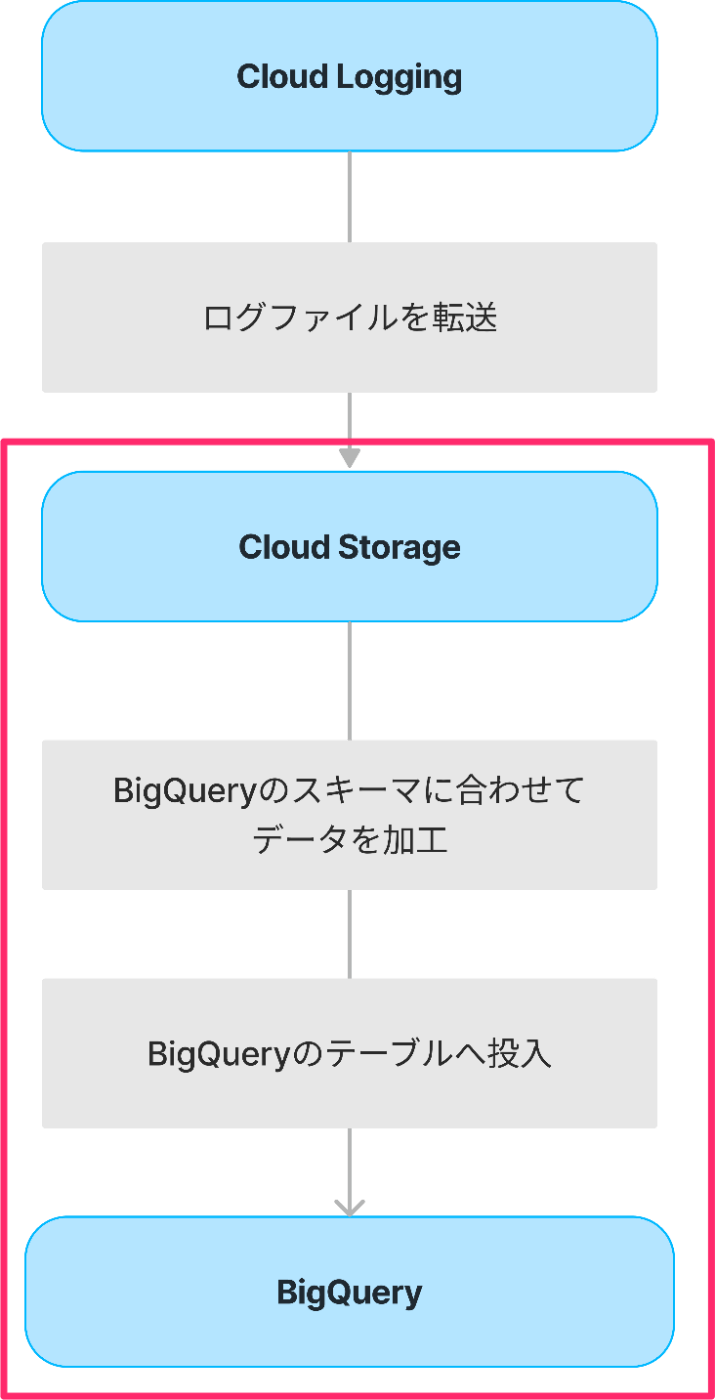
今回は、Cloud StorageへアップロードされたログファイルをDataflowを使ってBigQueryへ投入するフローについてご紹介します。
Cloud LoggingからCloud Storageへのデータ転送はシンクを使っていますが、今回の説明の範囲外のため割愛します。シンクを使ったログのルーティングについては、次の記事をご参照ください。
Dataflowの概要
Dataflowは、Google Cloudで提供されているデータパイプラインを構築するためのサービスです。基盤には、Apache Beamというストリーム処理やバッチ処理を行うためのフレームワークが使われています。Apache Beamを使用してパイプラインを構築することで、ストリームでデータを処理したり、BigQueryへデータを取り込むことが可能です。
詳細は公式ページをご確認ください。
テンプレート
Dataflowでは、テンプレートという機能を提供しており、一つのデータ処理をテンプレート化(パッケージ化)することで、デプロイや再利用が行いやすくなっています。
Flex テンプレートとクラシックテンプレート
テンプレートには大きく「Flexテンプレート」と「クラシックテンプレート」という2種類が存在しています。FlexテンプレートはDockerイメージとして起動するテンプレートで、基本的に新しいFlexテンプレートを使うことが推奨されています。
DataflowをAPIとして起動する場合、この「Flexテンプレート」と「クラシックテンプレート」で起動APIが異なり、パラメータも異なるため注意が必要です。
Google提供のテンプレート
Dataflowでは、Apache Beamでテンプレートを時前で構築しなくても、Googleが提供するテンプレートを使用することができます。
Googleが様々なユースケースに対して予めテンプレートを用意しているため、これらのテンプレートを使用するだけでDataflowによるデータ変換を実行することが可能です。
今回は、Google提供のテンプレートにある「Cloud Storage Text to BigQuery テンプレート」を使用します。
Cloud Functions v2の概要
Cloud Functionsは、Google Cloudが提供するFunctions as a Serviceで、現在第2世代までリリースされています。
Cloud Functionsを使うと、Google Storageへのオブジェクトアップロードイベントをトリガーすることができます。今回は、この機能を利用してDataflowを起動し、ログデータの変換処理を行います。
v1(第一世代)を使っても同様のことが可能ですが、新規で作成する場合は基本的にv2(第二世代)を使えば問題ありません。
v1とv2の比較については、こちらをご参照ください。
「Cloud Storage Text to BigQuery」テンプレートでDataflowを動かしてみる
まずは、「Cloud Storage Text to BigQuery」テンプレートを使用して、Dataflow単体で動作確認をしてみます。
事前準備
Dataflowを作成するにあたり、以下のリソースを事前に作成します。
| リソースの種類 | 説明 |
|---|---|
| 転送対象のログ(JSON) | BigQueryへデータを転送するログ |
| ログを格納するCloud Storage | ログを格納しておくCloud Storage |
| BigQueryのデータセット 及び テーブル | ログを転送する先のBigQueryのデータセットとテーブル |
| BigQueryのスキーマ定義JSON | BigQueryのスキーマを定義したJSONファイル |
| スキーマ定義JSONを格納するCloud Storage | スキーマ定義JSONを格納するCloud Storage |
| Dataflowの一次情報を格納するCloud Storage | 一次情報を格納するCloud Storage |
| UDF(user defined function)ファイル | ログからBigQueryへの変換処理を書くJavaScriptファイル |
| UDFを格納するCloud Storage | UDFを格納するCloud Storage |
転送対象のログ(JSON)
今回テストで用意するログは次のようになります。これは、実際にCloud RunからCloud Loggingに流れるログのダミーです。
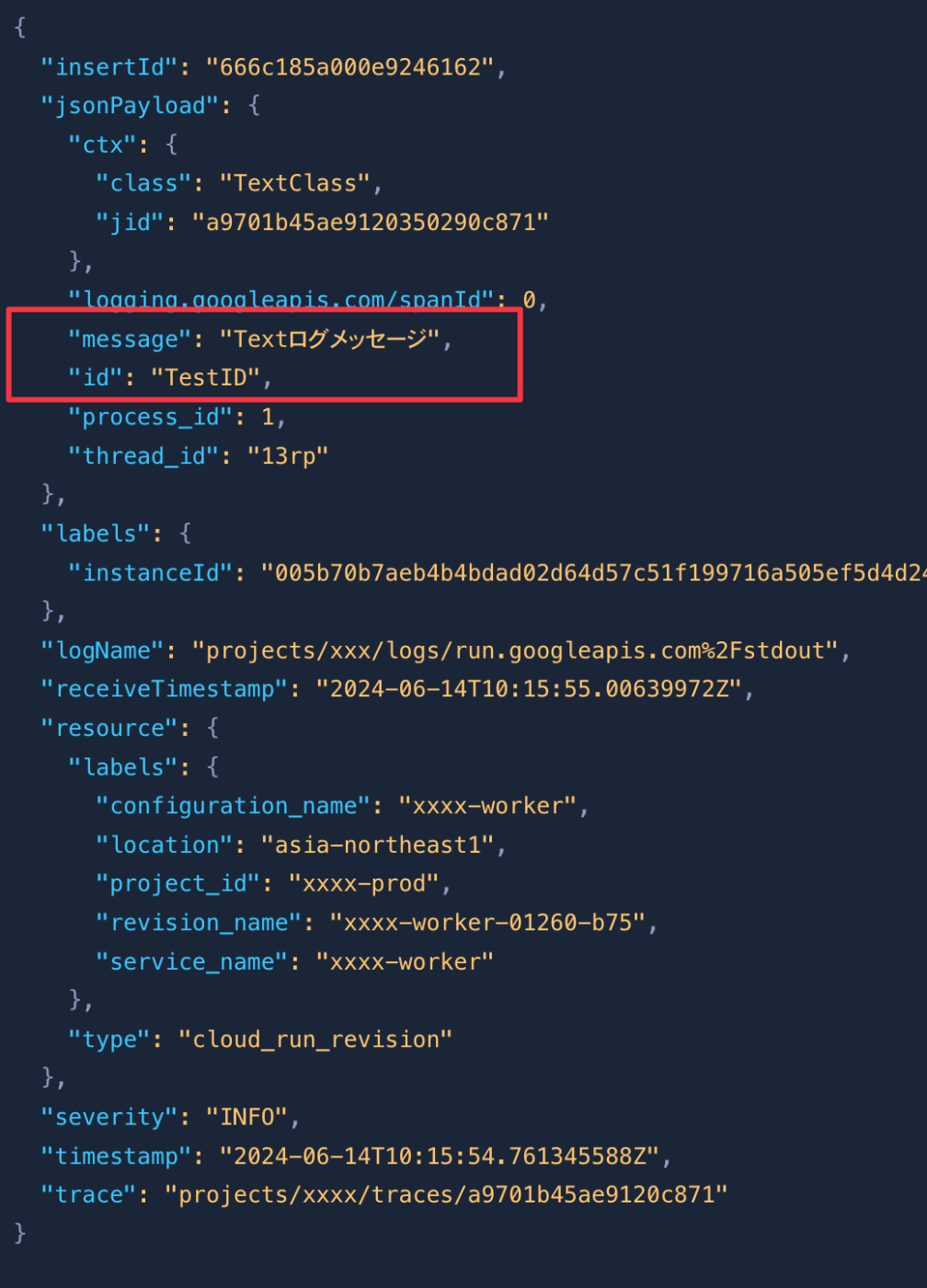
今回は、このログから
- id
- message
を抽出して、BigQueryのテーブルに格納するDataflowを作成します。
test-log.txt
{"insertId":"666c185a000b9cc3e9246162","jsonPayload":{"ctx":{"class":"TextClass","jid":"a9701b45ae9120350290c871"},"logging.googleapis.com/spanId":0,"message":"Textログメッセージ1","id":"TestID1","process_id":1,"thread_id":"13rp"},"labels":{"instanceId":"005b7087702050e4fc9249569ffcbb7aeb4b4bdad02d64d57c51552d5727c7f199716a505ef5d4d243c1f4721a56a7a89c7ebc5ab43527a3cfe34900345fc7e2dd2406"},"logName":"projects/xxx/logs/run.googleapis.com%2Fstdout","receiveTimestamp":"2024-06-14T10:15:55.00639972Z","resource":{"labels":{"configuration_name":"xxxx-worker","location":"asia-northeast1","project_id":"xxxx-prod","revision_name":"xxxx-worker-01260-b75","service_name":"xxxx-worker"},"type":"cloud_run_revision"},"severity":"INFO","timestamp":"2024-06-14T10:15:54.761345588Z","trace":"projects/xxxx/traces/a9701b45ae9120350290c871"}
{"insertId":"666c185a000b9cc3e9246162","jsonPayload":{"ctx":{"class":"TextClass","jid":"a9701b45ae9120350290c871"},"logging.googleapis.com/spanId":0,"message":"Textログメッセージ2","id":"TestID2","process_id":1,"thread_id":"13rp"},"labels":{"instanceId":"005b7087702050e4fc9249569ffcbb7aeb4b4bdad02d64d57c51552d5727c7f199716a505ef5d4d243c1f4721a56a7a89c7ebc5ab43527a3cfe34900345fc7e2dd2406"},"logName":"projects/xxx/logs/run.googleapis.com%2Fstdout","receiveTimestamp":"2024-06-14T10:15:55.00639972Z","resource":{"labels":{"configuration_name":"xxxx-worker","location":"asia-northeast1","project_id":"xxxx-prod","revision_name":"xxxx-worker-01260-b75","service_name":"xxxx-worker"},"type":"cloud_run_revision"},"severity":"INFO","timestamp":"2024-06-14T10:15:54.761345588Z","trace":"projects/xxxx/traces/a9701b45ae9120350290c871"}
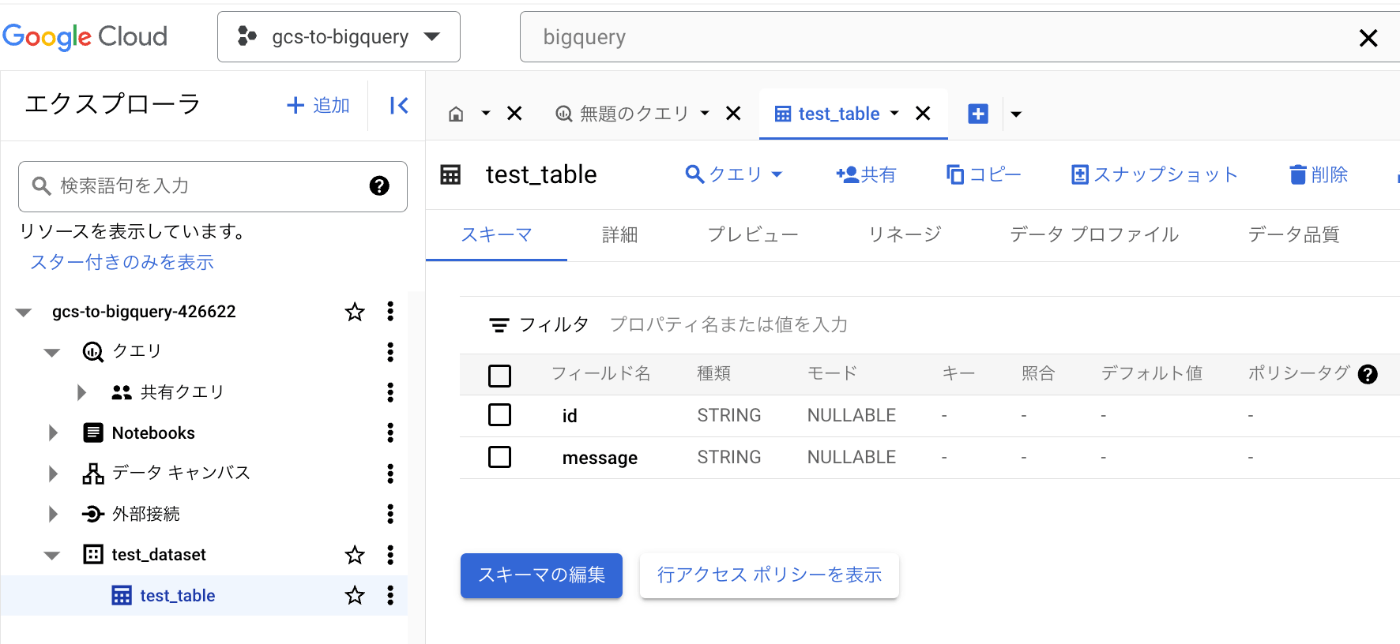
BigQueryのテーブル
転送先のBigQueryには、
- id
- message
のスキーマを持つシンプルなテーブルを用意します。
BigQueryのスキーマ定義JSON
「Cloud Storage Text to BigQuery」テンプレートでは、BigQueryのスキーマを定義したJSONファイルが必要です。
JSONのフォーマットは次のように BigQuery Schema というキーでスキーマを指定します。
{
"BigQuery Schema": [
{
"name": "id",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "message",
"type": "STRING",
"mode": "NULLABLE"
}
]
}
UDF
JSON構造のログをBigQueryのスキーマへ変換するためにJavaScriptの変換関数を使うことができます。前述のログ構造から「id」と「message」を抽出して、BigQueryのスキーマに対応したJSONを返すUDFは次のようになります。
function transform(data) {
// JSON文字列をオブジェクトにパース
const record = JSON.parse(data);
// 新しいJSONオブジェクトを作成
const transformedRecord = {
id: record.jsonPayload.id,
message: record.jsonPayload.message
};
// 変換後のJSONオブジェクトを文字列にして返す
return JSON.stringify(transformedRecord);
}
Dataflowの作成
事前準備で用意した内容を元に、コンソールからDataflowを作成してみます。
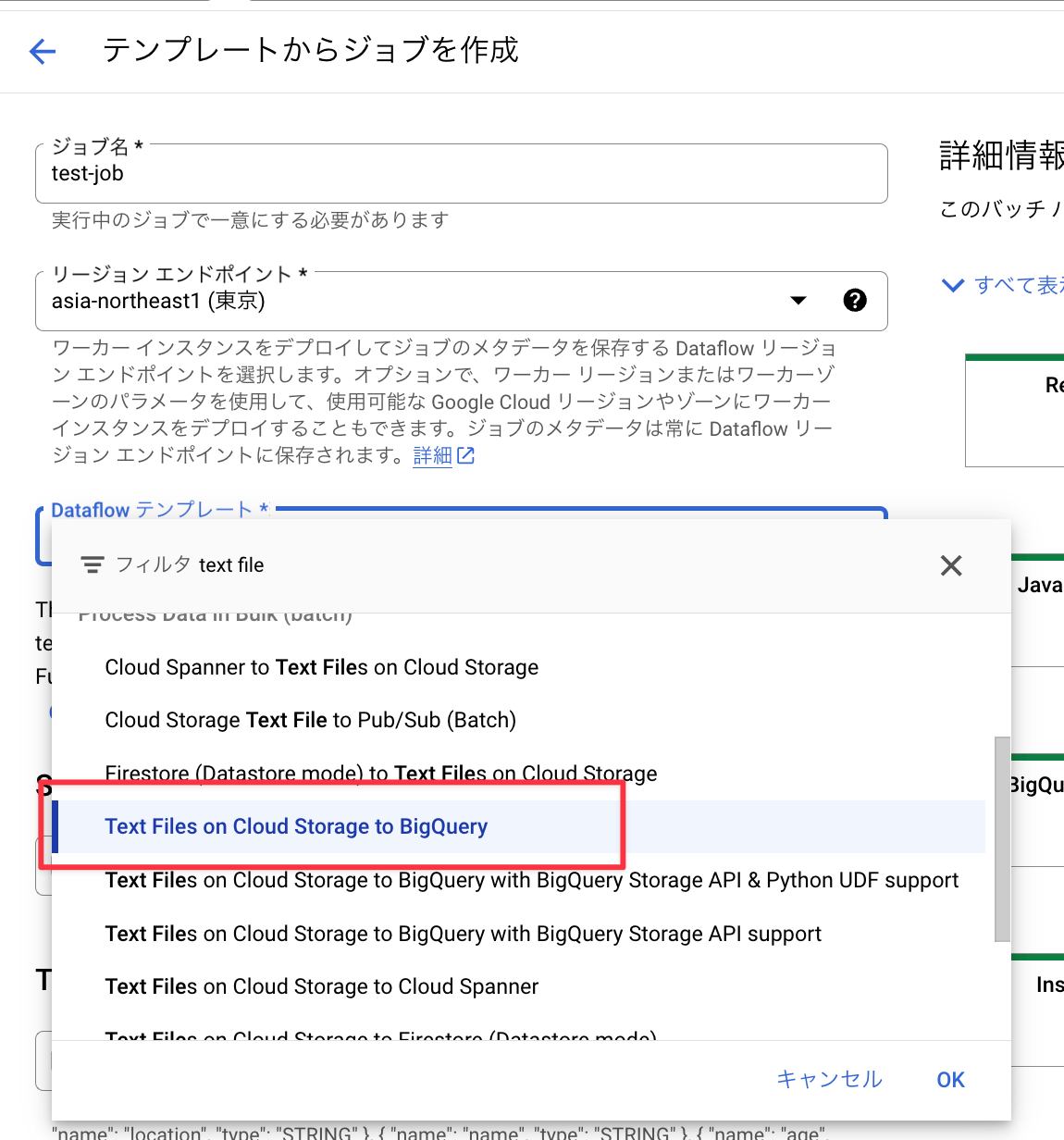
①「テンプレートからジョブを作成」を選択
②テンプレートは、「Text Files on Cloud Storage to BigQuery」を選択
③事前準備のCloud Storage/BigQuery/UDFを設定

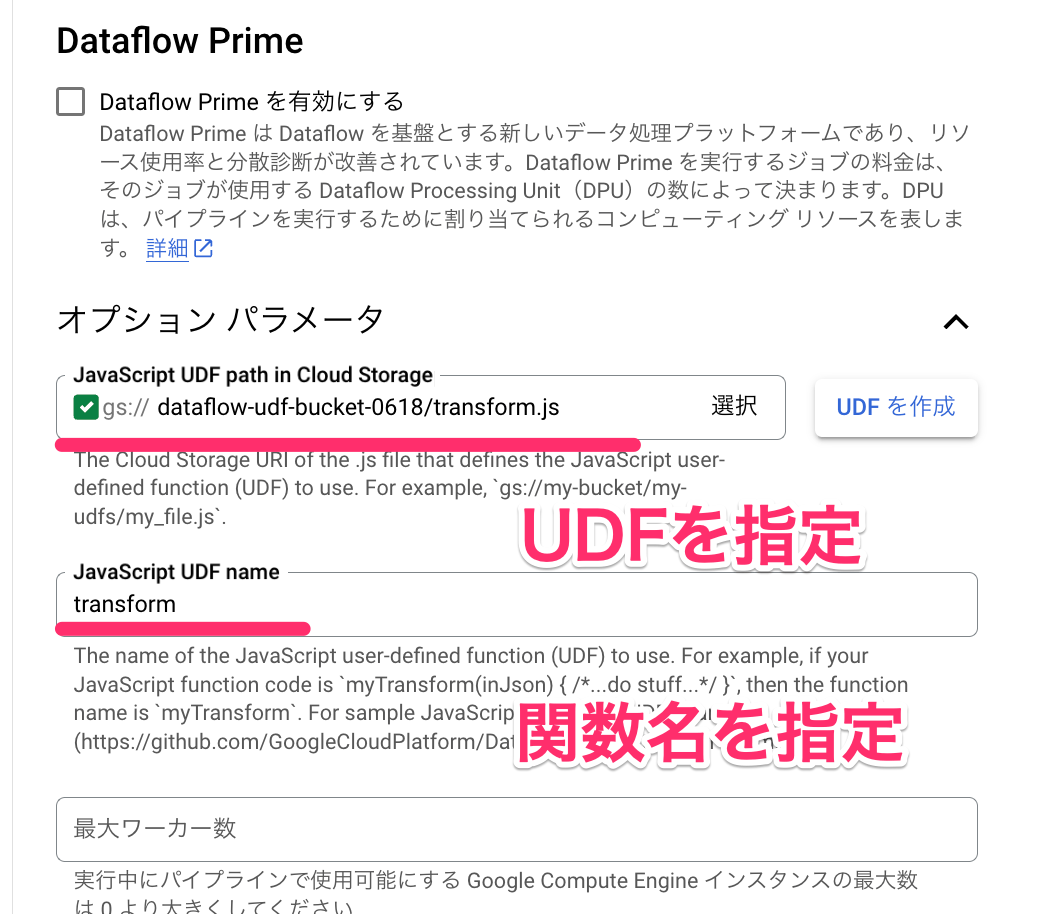
- 事前準備で用意した、ログJSON、BigQuery、UDFおよびそれに関するCloud Storageを設定し、Dataflowを実行します。
④動作確認
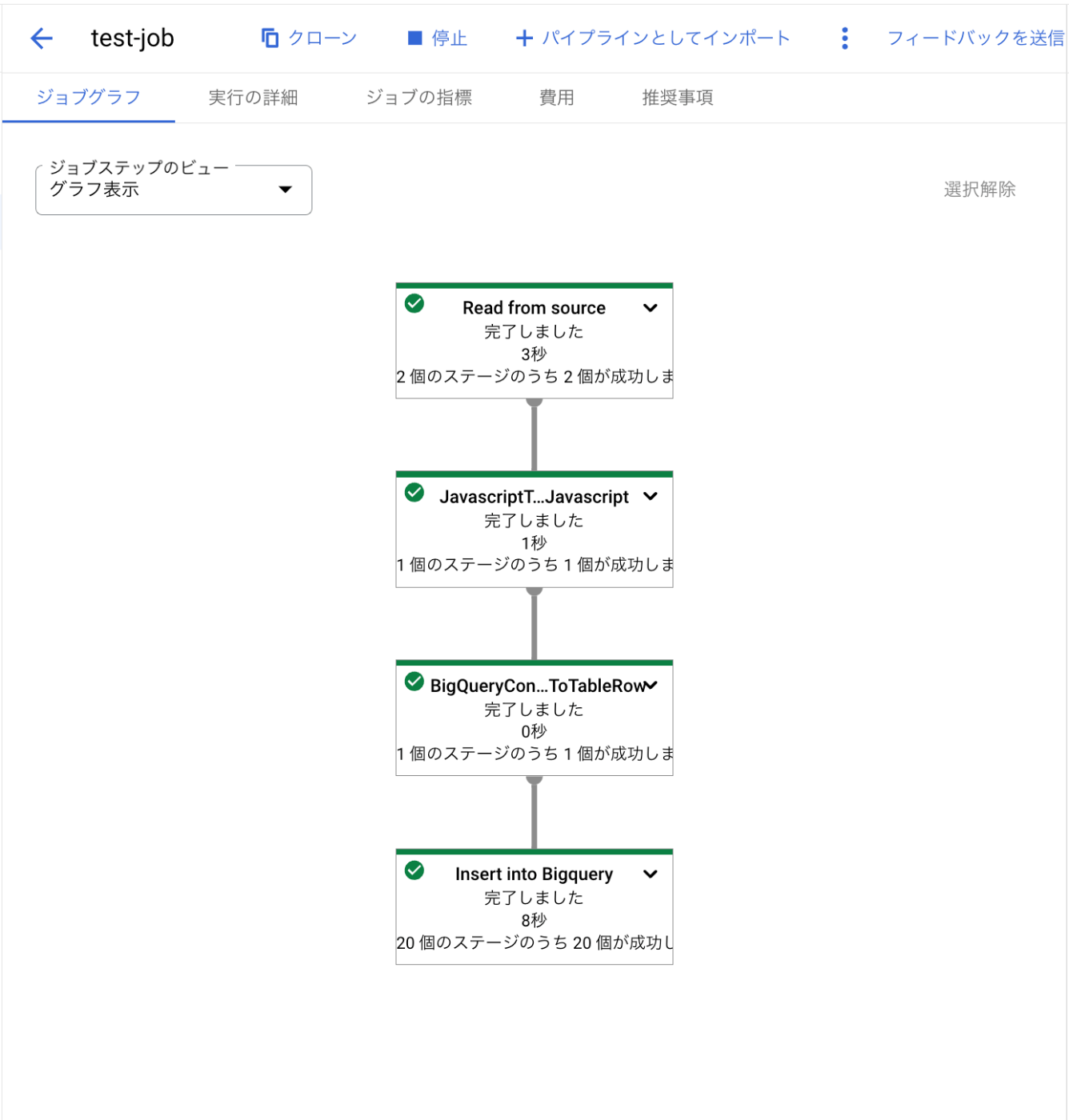
- ジョブが最後まで完了していれば成功です。
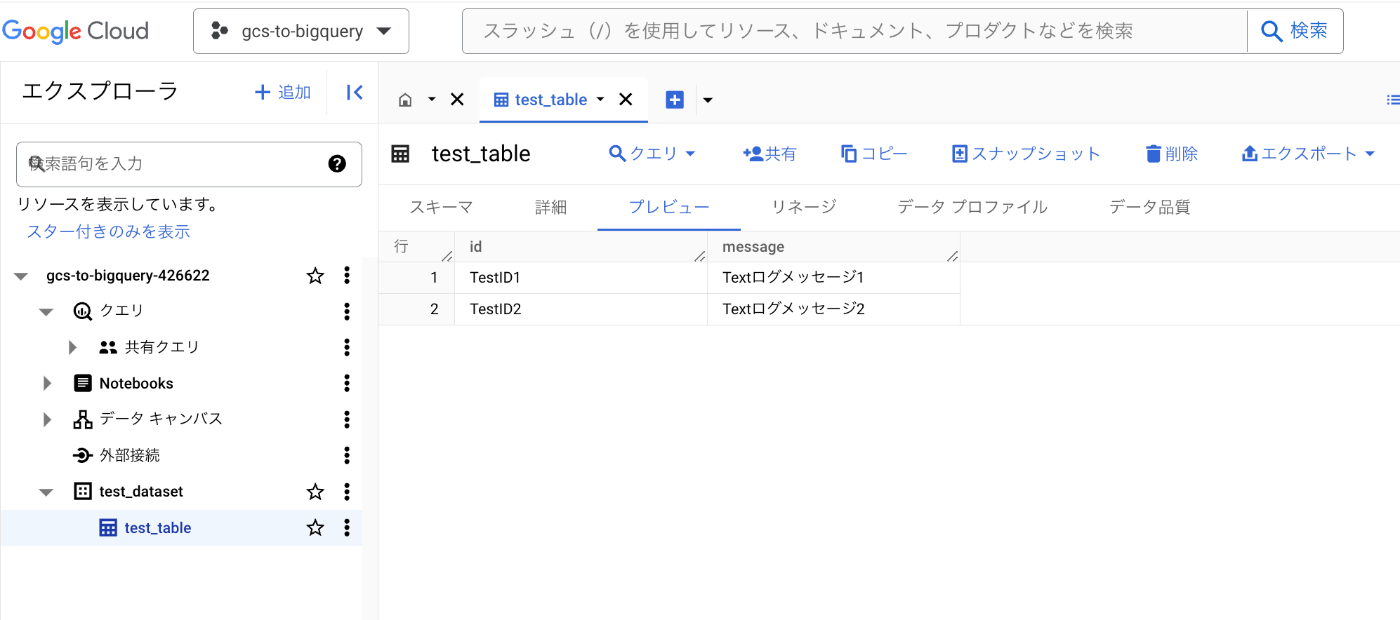
- BigQueryにデータが変換された状態で格納されています。
Cloud Function v2からDataflowを起動する
Dataflowが正しく動作することが確認できたので、次はCloud StorageへのログファイルのアップロードからCloud Functionを起動します。
Dataflowを起動するためのPythonスクリプト
前述の動作確認ではDataflowをコンソールから起動しましたが、Cloud Storageのファイルアップロードをトリガーとした場合は、アップロードを契機にDataflowを作成する処理が必要となります。
今回はPythonのGoogle API Clientライブラリを使用して、Dataflowを起動します。実際のコードは次の通りです。
from google.auth import default
from googleapiclient.discovery import build
import functions_framework
import datetime
@functions_framework.cloud_event
def trigger_dataflow(cloud_event):
# アップロードされたオブジェクトをDataflowのインプットに渡す
bucket = cloud_event.data['bucket']
object = cloud_event.data['name']
print("start dataflow job")
print(f"File path: gs://{bucket}/{object}")
# GCS_Text_to_BigQuery_FlexのGCSパスを指定する
template_gcs_path = f"gs://dataflow-templates-{dataflow_location}/latest/flex/GCS_Text_to_BigQuery_Flex"
# Dataflowの実行パラメータ
javascript_text_transform_gcs_path = 'gs://dataflow-udf-bucket-0618/transform.js'
javascript_text_transform_function_name = 'transform'
json_path = 'gs://bigquery-schema-bucket-0618/schema.json'
output_table = 'gcs-to-bigquery-426622.test_dataset.test_table'
big_query_loading_temporary_directory = 'gs://dataflow-temp-bucket-0618/temp'
dataflow_location = 'asia-northeast1'
project_id = 'gcs-to-bigquery-426622'
service_account_email = '686181112796-compute@developer.gserviceaccount.com'
parameters = {
'javascriptTextTransformGcsPath': javascript_text_transform_gcs_path,
'javascriptTextTransformFunctionName': javascript_text_transform_function_name,
'JSONPath': json_path,
'inputFilePattern': f"gs://{bucket}/{object}",
'outputTable': output_table,
'bigQueryLoadingTemporaryDirectory': big_query_loading_temporary_directory
}
credentials, _ = default()
dataflow = build('dataflow', 'v1b3', credentials=credentials)
# 同名のジョブがトリガーされると後発が失敗するためジョブ名にタイムスタンプを付与する
job_name = 'dataflow-job'
unique_job_name = f"{job_name}-{datetime.datetime.now().strftime('%Y%m%d%H%M%S')}"
request = dataflow.projects().locations().flexTemplates().launch(
projectId=project_id,
location=dataflow_location,
body={
'launch_parameter': {
'jobName': unique_job_name,
'parameters': parameters,
'containerSpecGcsPath': template_gcs_path,
'environment': {
'serviceAccountEmail': service_account_email
}
}
}
)
response = request.execute()
print(f"Job launched: {response}")
print("end dataflow job")
google-api-python-client==2.33.0
google-auth==2.6.2
functions-framework==3.*
Dataflowのジョブは同名のジョブが起動している場合、後発のジョブを起動できないため、タイムスタンプを付与してジョブ名が重複しないようにしています。
job_name = 'dataflow-job'
unique_job_name = f"{job_name}-{datetime.datetime.now().strftime('%Y%m%d%H%M%S')}"
ファンクションを作成
前述のPythonコードを使ってファンクションを作成します。
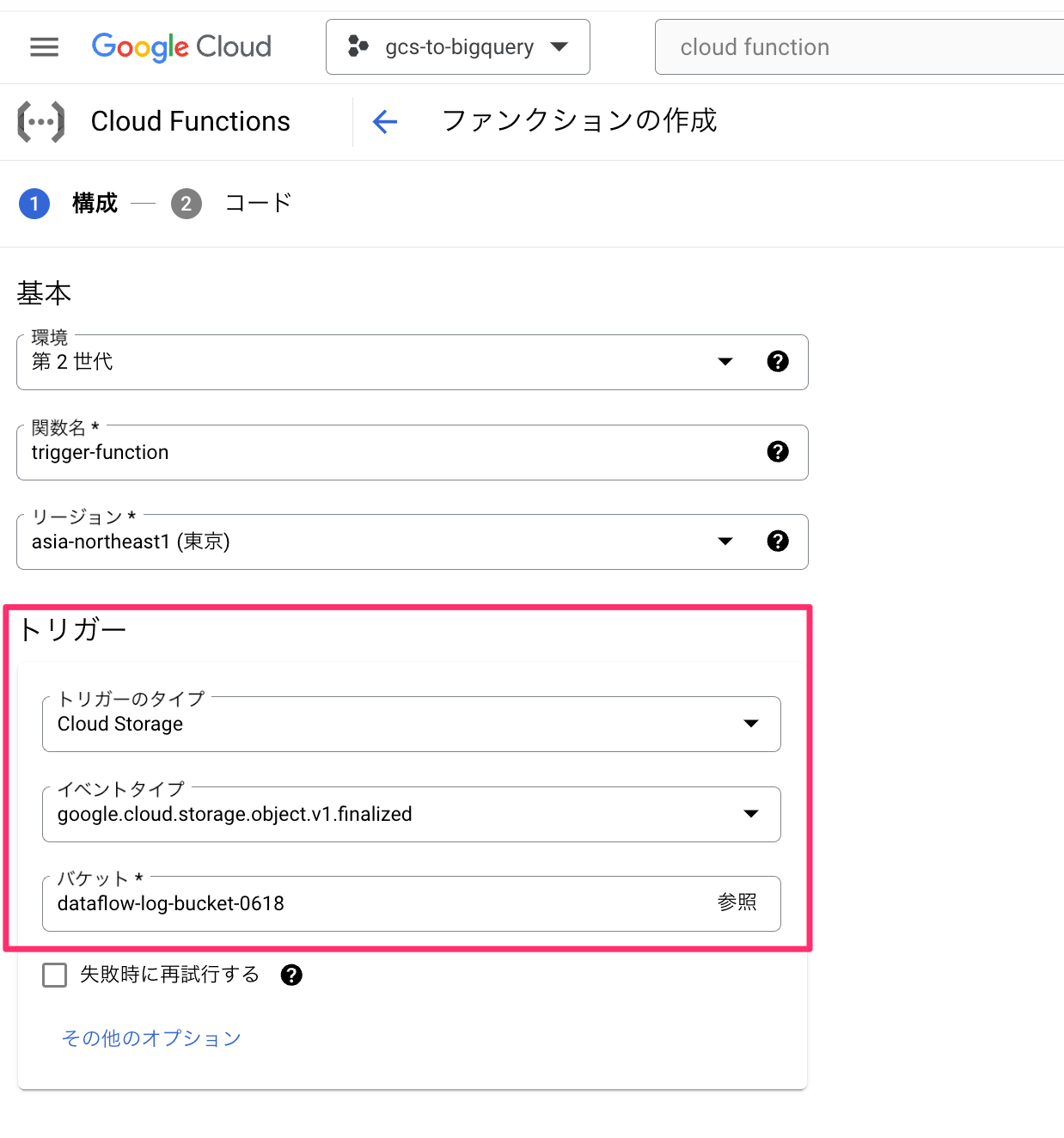
- ファンクションのトリガータイプには「Cloud Storage」を選択
- イベントタイプには「google.cloud.storage.object.v1.finalized」を選択
- バケットには、Dataflowの動作確認で使用したCloud Storageのバケットを指定
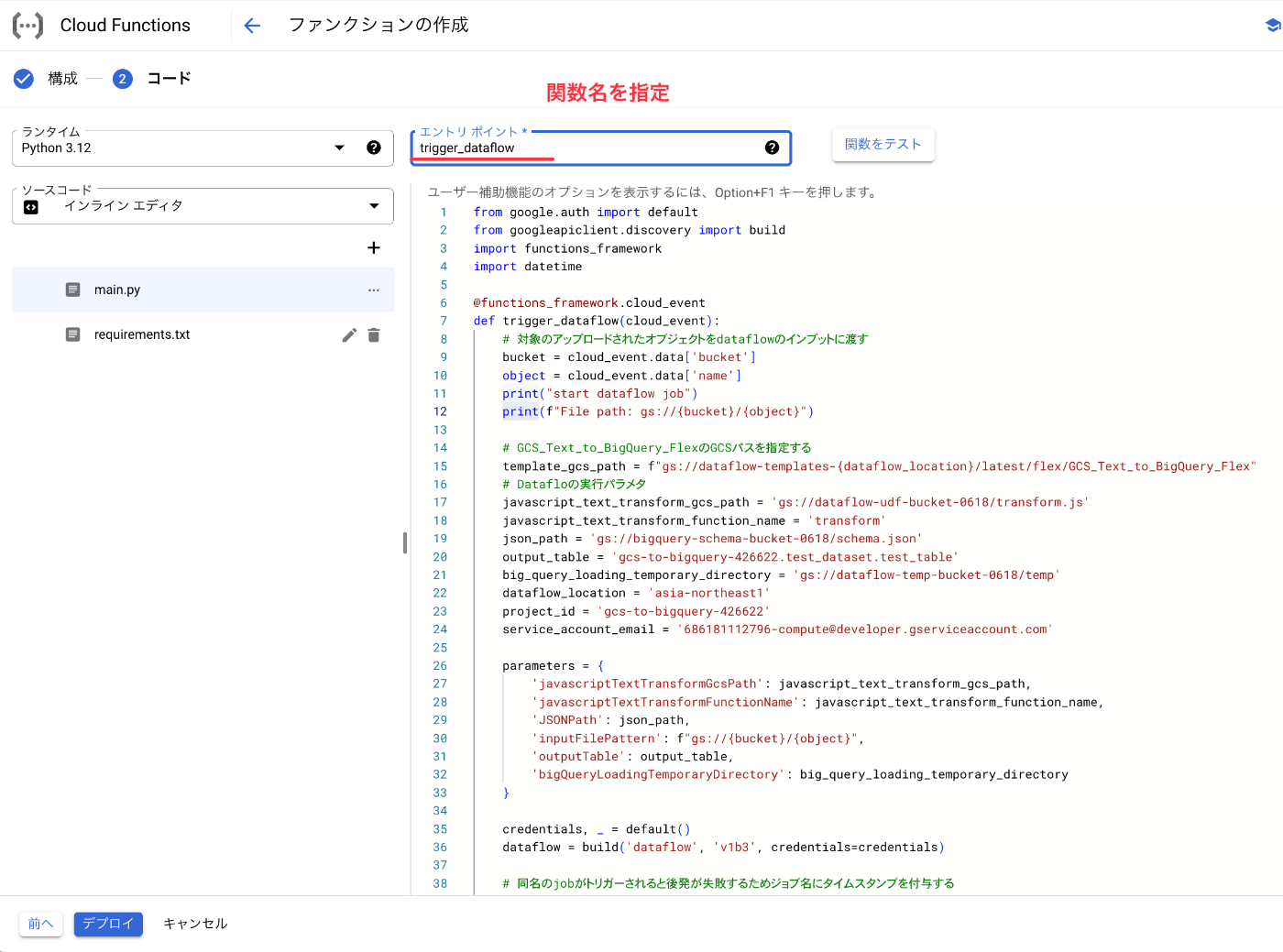
- コードには先ほどのPythonコードを添付
- エントリポイントには、関数名(今回は「trigger_dataflow」)を指定
動作確認
動作確認として、Cloud Storageの対象バケットに、想定されるログファイルを手動でアップロードします。今回は、次の構造のログファイルをアップロードしてみます。
test-log.txt
{"insertId":"666c185a000b9cc3e9246162","jsonPayload":{"ctx":{"class":"TextClass","jid":"a9701b45ae9120350290c871"},"logging.googleapis.com/spanId":0,"message":"Textログメッセージ1","id":"TestID1","process_id":1,"thread_id":"13rp"},"labels":{"instanceId":"005b7087702050e4fc9249569ffcbb7aeb4b4bdad02d64d57c51552d5727c7f199716a505ef5d4d243c1f4721a56a7a89c7ebc5ab43527a3cfe34900345fc7e2dd2406"},"logName":"projects/xxx/logs/run.googleapis.com%2Fstdout","receiveTimestamp":"2024-06-14T10:15:55.00639972Z","resource":{"labels":{"configuration_name":"xxxx-worker","location":"asia-northeast1","project_id":"xxxx-prod","revision_name":"xxxx-worker-01260-b75","service_name":"xxxx-worker"},"type":"cloud_run_revision"},"severity":"INFO","timestamp":"2024-06-14T10:15:54.761345588Z","trace":"projects/xxxx/traces/a9701b45ae9120350290c871"}
{"insertId":"666c185a000b9cc3e9246162","jsonPayload":{"ctx":{"class":"TextClass","jid":"a9701b45ae9120350290c871"},"logging.googleapis.com/spanId":0,"message":"Textログメッセージ2","id":"TestID2","process_id":1,"thread_id":"13rp"},"labels":{"instanceId":"005b7087702050e4fc9249569ffcbb7aeb4b4bdad02d64d57c51552d5727c7f199716a505ef5d4d243c1f4721a56a7a89c7ebc5ab43527a3cfe34900345fc7e2dd2406"},"logName":"projects/xxx/logs/run.googleapis.com%2Fstdout","receiveTimestamp":"2024-06-14T10:15:55.00639972Z","resource":{"labels":{"configuration_name":"xxxx-worker","location":"asia-northeast1","project_id":"xxxx-prod","revision_name":"xxxx-worker-01260-b75","service_name":"xxxx-worker"},"type":"cloud_run_revision"},"severity":"INFO","timestamp":"2024-06-14T10:15:54.761345588Z","trace":"projects/xxxx/traces/a9701b45ae9120350290c871"}
正しく動作していれば、Dataflowが起動し、BigQueryへのデータ転送が行われているはずです。

- 新しいDataflowが作成されている
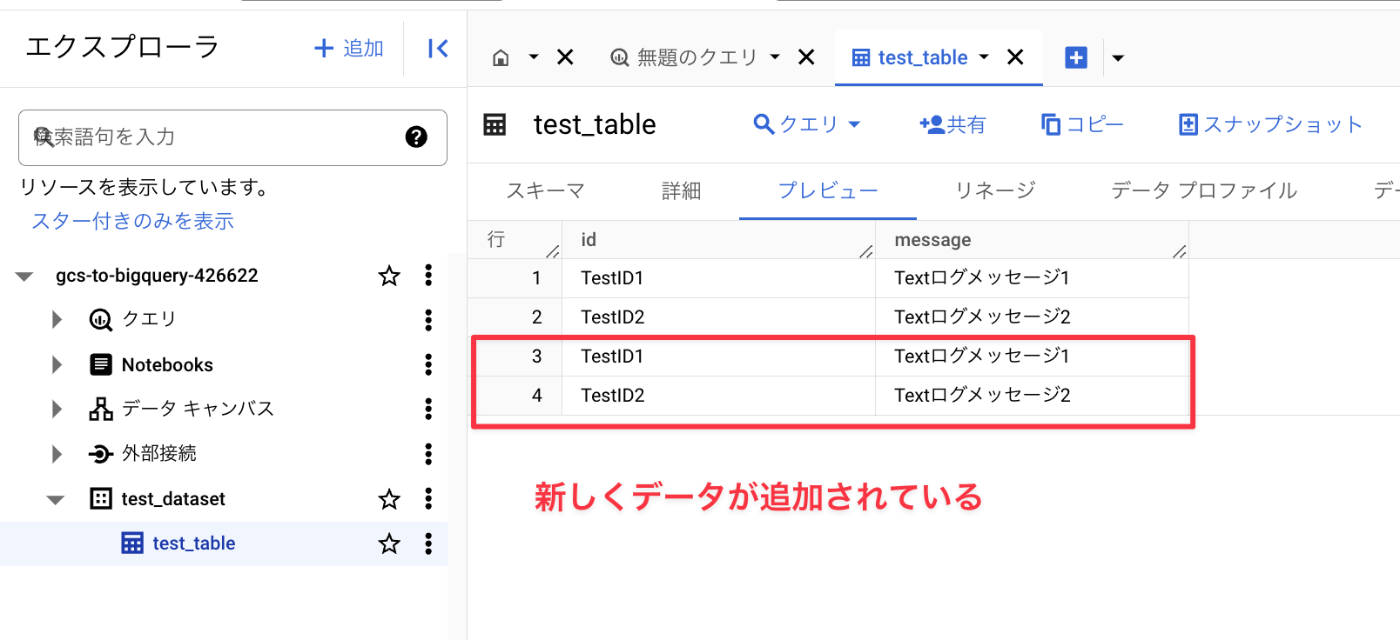
- BigQueryへデータが追加されている
終わりに
以上、Dataflowを使ったデータ転送のご紹介でした。データパイプラインの方法は様々ありますが、チームに合った方法を選ぶ際の参考にしていただけたら幸いです。
PharmaXでは、様々なバックグラウンドを持つエンジニアの採用をお待ちしております。弊社はAI活用にも力を入れていますので、LLM関連の開発に興味がある方もぜひ気軽にお声がけください。
もし興味をお持ちの場合は、私のXアカウント(@hakoten)や記事のコメントにお気軽にメッセージいただければと思います。まずはカジュアルにお話できれば嬉しいです!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion