※この記事は、noteから移行しました。
こんにちは。PharmaXの共同創業者の上野(@ueeeeniki)です。この記事はPharmaXアドベントカレンダー2023の11日目の記事です。
今回は、近年注目度が高まっているRustのSQLライブラリであるSQLxの使い方について説明したいと思います。SQLxは非同期対応していて、非常にシンプルなので、かなり使い勝手のいいSQLライブラリです。一方で、ORMではないため、実装者がSQLを書かければならないというデメリット(?)もあります。
SQLxの記事は徐々に増えてきてはいますが、まだまだ全体数は少ない印象なので、今回網羅的に解説する記事を執筆することとしました。
- Rustで自分にあったSQLライブラリを探している
- RustのいくつかのSQLライブラリを比較したい
- 人気のSQLライブラリSqlxの使い方を知りたい
という方の参考になれば嬉しいです!
はじめに
SQLxの特徴
SQLxの一番の特長は、非同期対応しており、tokioなどの非同期ランタイムを選択可能な点です。当然、PostgresSQL、MySQL、SQLite、SQLServerなどの多数のRDBMSをサポートしています。
また、公式ドキュメントにもデカデカとアピールされているようにSQLxは、ORMではありません。また、クエリビルダーの機能も持たないため、実装者がSQLを書く必要があります。
例えば、下記のように書きます(公式ドキュメントから引用)。
let user = sqlx::query_as::<_, User>("SELECT * FROM users WHERE id = $1")
.bind(id)
.fetch_one(&pool) // -> User
.await?;
このようなSQLを入力として受け取り、接続先のデータベースに対してSQLが有効であることを保証してくれるという非常に強力なマクロも備えています。SQLxがコンパイル時に開発用DBに接続し、データベース自身にSQLクエリを検証させます。SQLxはSQL文字列自体は解析しておらず、開発用DBが受け付ける構文であれば、大文字、小文字、改行の有無などは気にせずある程度柔軟に使うことができます。ただし、データベースによってクエリに関して取得できる情報の量が異なるため、クエリマクロから得られるSQL検証の程度はデータベースに依存してしまうことに注意は必要です。
DieselやSeaORMとの比較
Dieselは、RustのSQLライブラリとして一番の老舗ORMと言っていいでしょう。機能も非常に豊富ですが、asyncに非対応というデメリットを抱えているため、SQLxやSeaORMに追い上げられつつあるようです。
SeaORMは、内部的にSQLxを使うことで非同期に対応したORMです。書籍『パーフェクトRust』の下記の図が分かりやすかったので参考にしてください。シンプルでありながら、ORMとしては十分な機能を持っているので、近年注目度が高まっているようです。
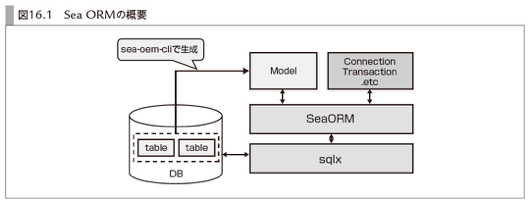
『パーフェクトRust』から引用
詳しくは扱いませんが、ormxも内部的にSQLxを使ったORMのようです。
今回解説の題材とするデータベースの解説
今回サンプルとして使用するデータベースは、以下のクエリで作成します。公式ドキュメントでも使われているusersテーブルの構造を推測して作成しました。
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(255),
name VARCHAR(255),
country VARCHAR(50)
);
SQLx CLIでできること
準備
SQLxのCLIツールであるSQLx CLI(crateはsqlx-cli)では、データベースの作成・削除やマイグレーションが可能です。
cargo install sqlx-cli
上記でcliツールをインストールすることができます。SQLxは、DATABASE_URLという環境変数でデータベースの接続先を自動で認識します。
# Postgresの場合
DATABASE_URL=postgres://postgres:password@localhost:5432/my_database
# MySQLの場合
DATABASE_URL=mysql://mysql:password@localhost:3306/my_database
-database-urlコマンドラインオプションを使うことも可能ですが、環境変数DATABASE_URLで扱うのがシンプルでしょう。
データベースの作成と削除
データベースの作成
dbの作成と削除は非常に単純です。DATABASE_URLで指定した、データベース名(上記の例ではmy_database)が勝手に作成されます。
# データベースの作成
sqlx database create
データベースの削除
削除は下記のようにdropするだけです。
# データベースの削除
sqlx database drop
migrationの仕方
では、migrationもしていきましょう。sqlx migrate add <name>とするだけで、マイグレーションファイルが作成されます。
リバート用のマイグレーションファイルも同時に作成したい場合、-rオプションを付けます。このあたりはチームのポリシーに拠るところでしょうが、テーブルを一括で削除したい場合には、downファイルを作成しておくと便利です。
# revert可能なマイグレーションファイルの作成
$ sqlx migrate add -r <name>
Creating migrations/20211001154420_<name>.up.sql
Creating migrations/20211001154420_<name>.down.sql
upの方に今回のサンプルデータベースを作成するSQLを記述します。
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(255),
name VARCHAR(255),
country VARCHAR(50)
);
downの方にDROP用のSQLを記述しておきます。
DROP TABLE users;
準備ができたら、マイグレーションを実行します。
migrationの実行
下記のように簡単に実行することができます。
# migrationの実行
$ sqlx migrate run
Applied migrations/20211001154420 <name> (32.517835ms)
同様にリバートしたければ、下記のようにするだけです。
# リバートの実行
$ sqlx migrate revert
Applied 20211001154420/revert <name>
SQLxの書き方
コネクションプールの作成
実際にSQLxを書いてデータベース操作を行う前に下記のようにコネクションプールを作成する必要があります。コネクションの確立も非同期処理なので、awaitする必要があります。
use sqlx::postgres::PgPoolOptions;
// 省略
let pool = PgPoolOptions::new()
.max_connections(5)
.connect("postgres://postgres:password@localhost/test").await?;
それを下記のようにquery実行時に与える必要があります。
sqlx::query("DELETE FROM users").execute(&pool).await?;
queryやquery_asを使った基本的なデータベース操作
これまでの例でも出てきてはいますが基本的なデータベース操作には、queryとquery_as関数を使用します。先に結論を言うと、queryかquery_asは下記のように使い分けることがオススメです。
- 取得系(SELECT):query_as
- 更新系(INSERT、UPDATE、DELETE):query
ただし、PostgresのRETURNINGを使用して更新した行を返す場合はquery_asを使用すると良い
queryは、fetchしたときにRow<'conn>を返すため、データ取得時には扱いづらいです。取得した値の要素にアクセスするには、get()関数を使う必要があります。
struct User { name: String, email: String, country: String }
let row = sqlx::query("SELECT * FROM users WHERE id = $1")
.bind(id)
.fetch_one(&pool) // -> { name: String, email: String, country: String }
.await?;
let email = user.try_get("email")?
このため、queryは、更新系でデータ取得する必要のない際に使用するのがオススメです。
sqlx::query("DELETE * FROM users WHERE id = $1")
.bind(id)
.execute
.await?;
一方、query_asは、ジェネリクスの第二引数で受けとった構造体にSQLの実行結果をバインドすることができます。バインドするには、戻り値の型に指定する構造体にsqlx::FromRowをderiveしておくことと、カラム名と同等のフィールドを宣言しておく必要があります。Rustで扱いやすくするためには、構造体にバインドするのが一番なので、データ取得する際には、基本的にquery_asを使うのがオススメです。
#[derive(sqlx::FromRow)]
struct User { name: String, email: String, country: String }
let user = sqlx::query_as::<_, User>("SELECT * FROM users WHERE id = $1")
.bind(id)
.fetch_one(&pool) // -> User
.await?;
Postgresの更新系でRETURNING句を使うときにも、更新した値を取得したいはずなので、query_asを使うのがオススメでしょう。
let label = sqlx::query_as::<_, Label>(
"
INSERT INTO users ( name, email, country )
values ( $1, $2, $3 )
returning *
"#,
)
.bind(name)
.fetch_one(pool)
.await?;
fetch, fetch_xxx, executeの違い
executeは、主に更新系のクエリを実行するときに使います。つまりqueryとセットで使うことが多いです。更新した行数を取得することはできますが、データ自体は取得できません。
sqlx::query("DELETE FROM users").execute(&pool).await?;
データを取得するときは、fetch系を使用します。fetchは、取得したレコードをStreamで返すため、下記のようにレコードごとにループを回して処理を行う必要があります。
use futures::TryStreamExt;
let mut rows = sqlx::query("SELECT * FROM users WHERE name = ?")
.bind(name)
.fetch(&pool);
while let Some(row) = rows.try_next().await? {
let email: &str = row.try_get("email")?;
}
これだけでは、実際には使いづらいため(私はfetchをほとんど使ったことがありません)、fetch_xxxというメソッドが用意されています。
fetch_oneは、該当するレコードを1つだけ取得するので、queryであればRow<'conn>、query_asであれば渡したジェネリクス型を返します。
let user = sqlx::query_as::<_, User>("SELECT * FROM users WHERE id = $1")
.bind(id)
.fetch_one(&pool) // -> User
.await?;
fetch_allは、取得したすべてのレコードをVecとして返します。
let users = sqlx::query_as::<_, User>("SELECT * FROM users WHERE name = $1")
.bind(name)
.fetch_all(&pool) // -> Vec<User>
.await?;
query!やquery_as!マクロを使ったコンパイル時の検証
query!やquery_as!マクロを使用することで、コンパイル時にSQL文の構文とセマンティックを検証します。そのため、コンパイル時にデータベースに接続できる必要があります。環境変数DATABASE_URLを設定しましょう。
書き方もqueryやquery_asとは微妙に異なり、下記のように書きます。
struct User { name: String, email: String, country: String }
let users = sqlx::query!("SELECT * FROM users WHERE country = $1",
country
)
.fetch_all(&pool) // -> Vec<{ name: String, email: String, country: String }>
.await?;
struct User { name: String, email: String, country: String }
let users = sqlx::query_as!(
User,
"SELECT * FROM users WHERE country = $1",
country
)
.fetch_all(&pool) // -> Vec<User>
.await?;
特に、query_as!では、query_asで利用されていた
let users = sqlx::query_as::<_, User>("SELECT * FROM users WHERE country = $1",)
.bind(country)
.fetch_all(&pool) // -> Vec<User>
.await?;
というような書き方の代わりに、構造体を引数に取るような書き方をしているので注意が必要です。また、変数をbindではなく、マクロの引数に取ります。ここは、bindで明示的に変数の値を穴埋めをしていくquery_asの書き方の方が多少見やすいかもしれませんね。
下記の記事も詳細に解説してくれているので、是非参考にしてみてください。
SQLxを使用する上での注意
Cloud RunでプライベートIPのCloud SQLをVPCコネクタを利用して接続する場合、SQLxを使用する上では、native-tls系のfeatureを使用しなければ接続できないようです。PharmaXでは、ランタイムにtokioを使用しているので、runtime-tokio-native-tlsを使っています。
下記のようにcargo addするタイミングでfeatureに指定することができます。
cargo add sqlx --features "mysql runtime-tokio-native-tls chrono"
下記の記事も是非参考にしてみていただけると。
PharmaXでは、まさにこの構成を利用していたのですが、上記の記事を見ていたことで問題なく使用することができました。
AWSでも同じようなサービスで同じ問題が起こるのかは正直分かっていません。もし引っかかることがあればこちらもご参照ください。
最後に
今回は、Rustの非同期対応SQLライブラリとして注目のSQLxの使い方を解説してきました。非常にシンプルなので、すぐに使い始めることができるでしょう。個人的にも、無理にORMを使うよりは、SQLxを使う方が気に入っています。同じようにシンプルな使い心地を求める方にはピッタリなのではないでしょうか。
別の記事では、ORMとして人気急上昇中のSeaORMの使い方も扱いたいと思います。是非引き続き注目していただければ嬉しいです。
PhramaXでは、積極的な発信が文化となっていて、下記のような勉強会も行います。ご興味のある方は是非ご参加ください!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion