Power Automate Desktop Webページからデータを抽出する 3
Web スクレイピング 3 回目
はじめに
みなさんはページング使いこなせていますか? 私は全然です。
使い方をわかっていないだけなのか、サイトが悪いのか。
手動で操作する分には気にならないナビゲーションでも、自動化しようとすると難しいです。
前回: Power Automate Desktop Web ページからデータを抽出する 2
前々回: Power Automate Desktop Web ページからデータを抽出する
レシピ
Reader Store の本棚を CSV に出力して保存します。
- 抽出する項目
- 本のタイトル
- 著者
- カテゴリー
- ジャンル
スクレイピングする
まず初めに、スクレイピングの部分から作っていきます。
- Reader Store の本棚を表示します。アカウントを持っているのが前提になります。→本棚
- 本をシリーズごとにまとめないで取得したい場合は、設定を変えておきます。
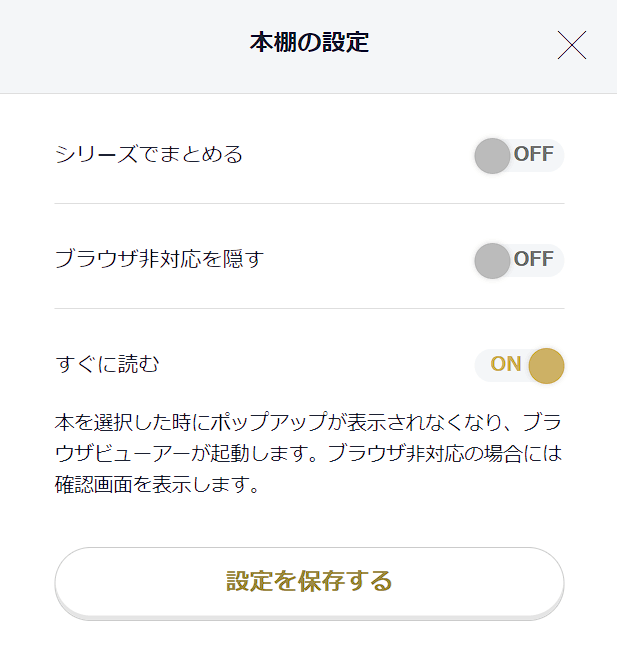
- Web ページからデータを抽出する設定を行うときは、グリッドビューからリストビューに変更して、タイトルや著者が見えるようにしておきます。実行時はグリッドビューのままで見えなくても取得されます。

- 抽出。
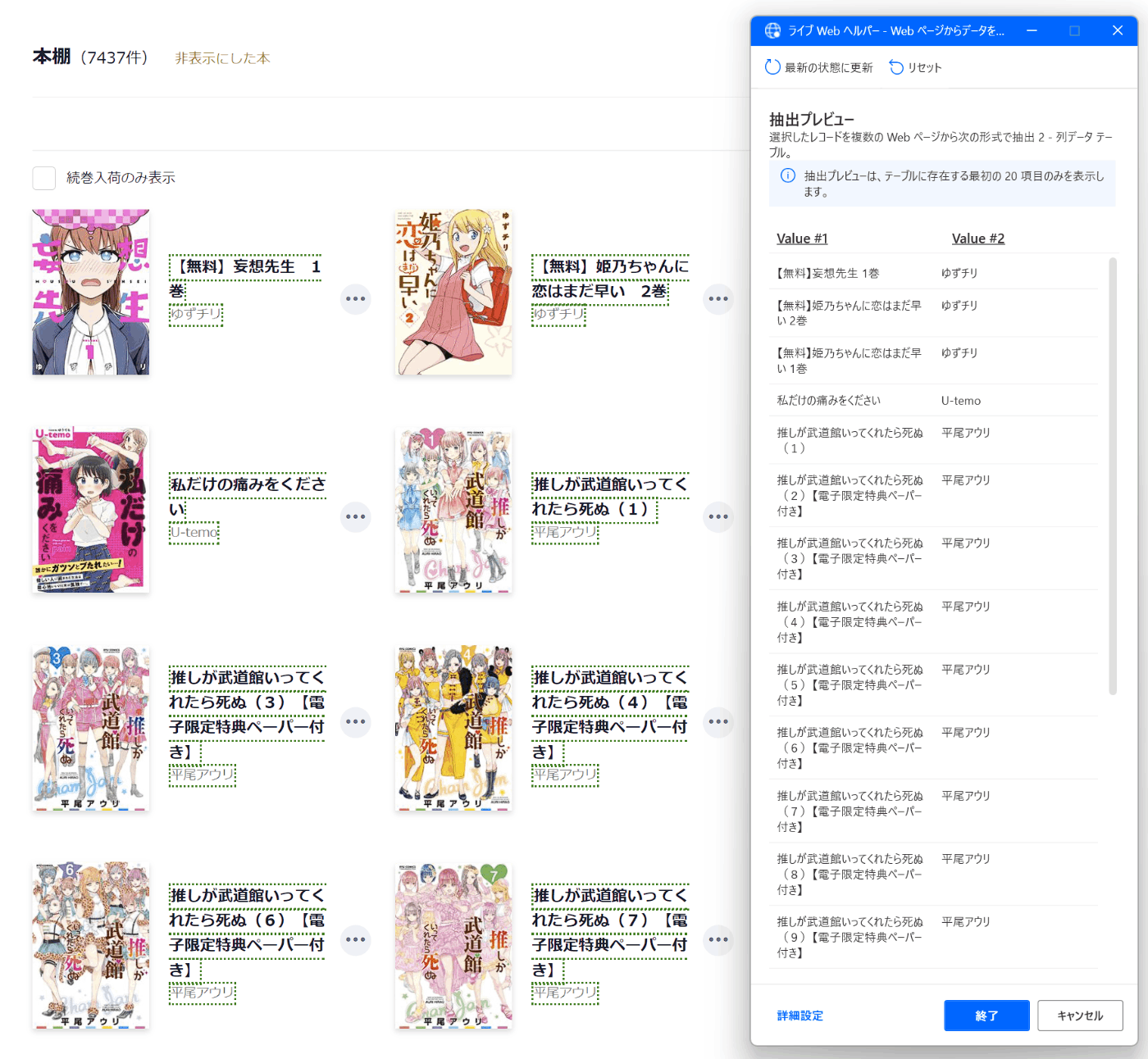
問題はここから
ページャーのナビゲーションですが、Reader Store はこうなっています。





常に同じボタンで次ページへ行けるわけではなく、次へのボタンが変わるやつです。
こういうパターンも。

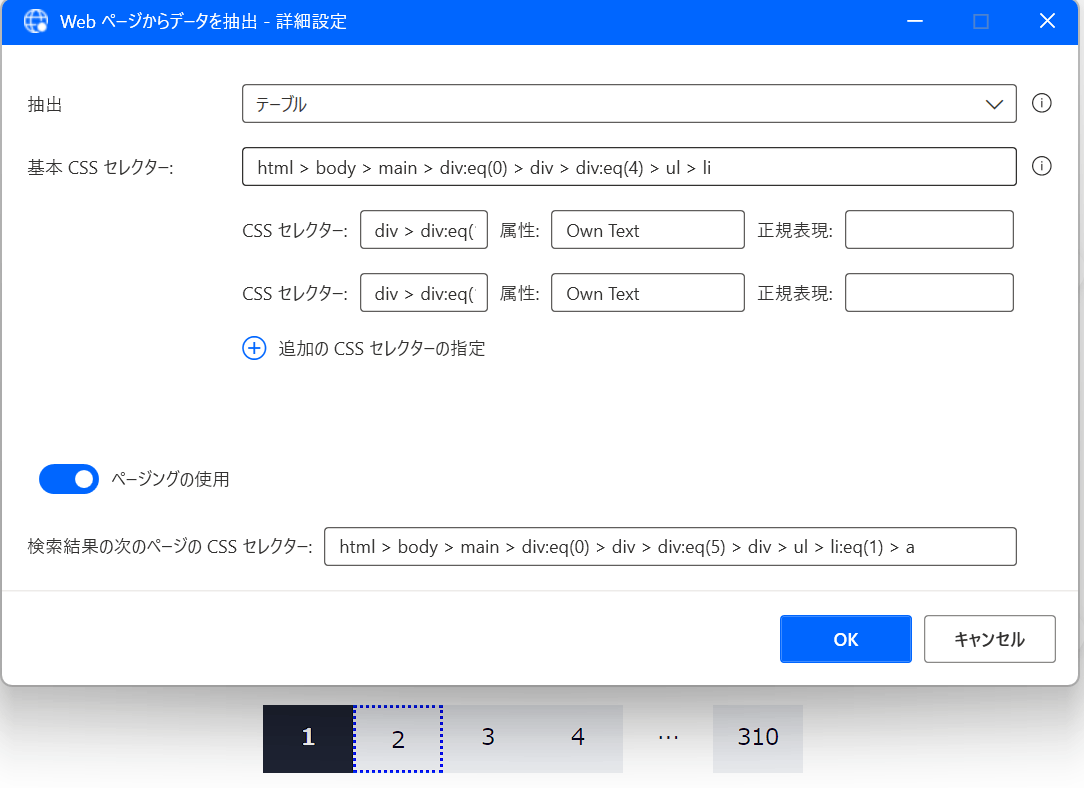
1→2
html > body > main > div:eq(0) > div > div:eq(5) > div > ul > li:eq(1) > a
2→3
html > body > main > div:eq(0) > div > div:eq(5) > div > ul > li:eq(2) > a
3→4
html > body > main > div:eq(0) > div > div:eq(5) > div > ul > li:eq(3) > a
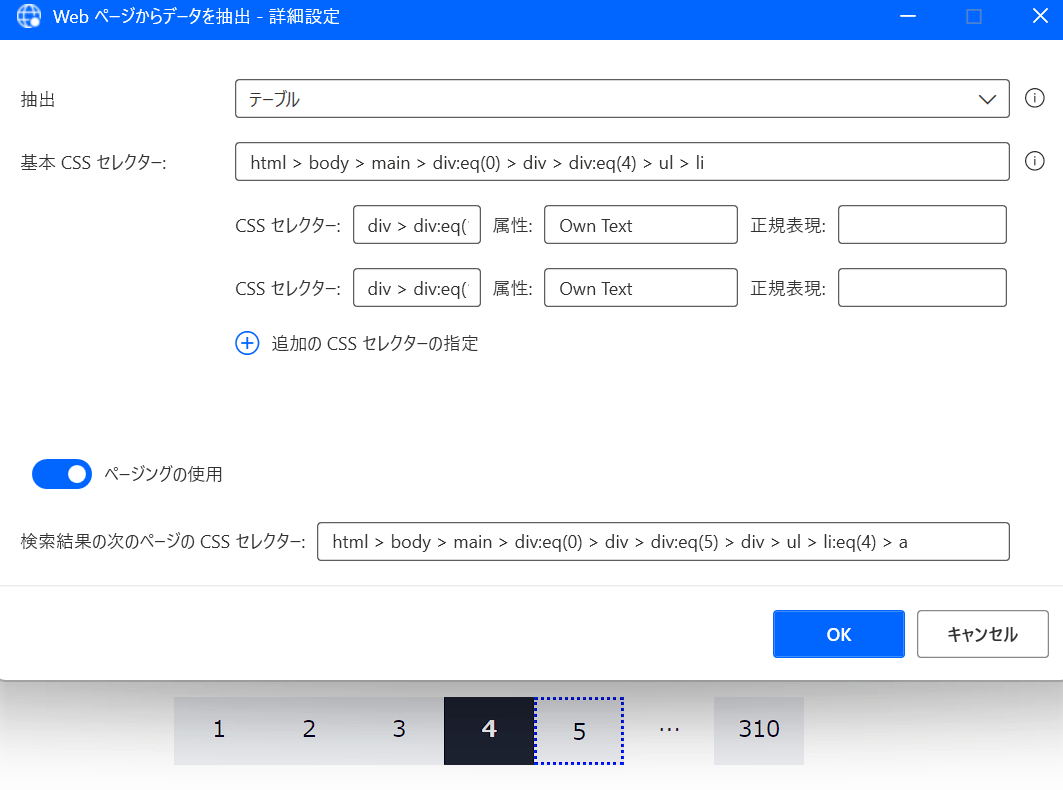
4→
html > body > main > div:eq(0) > div > div:eq(5) > div > ul > li:eq(4) > a
どうやってセレクターを指定したら良いのでしょうか???
諦めました。
1 ページずつ取得してマージする方法で試してみる
ページ移動
URI にpage=○○が付与されているので、ループでこの数値を 1 つずつ増やしながら[Web ページに移動]アクションで移動することで、ページングのかわりになりそう。
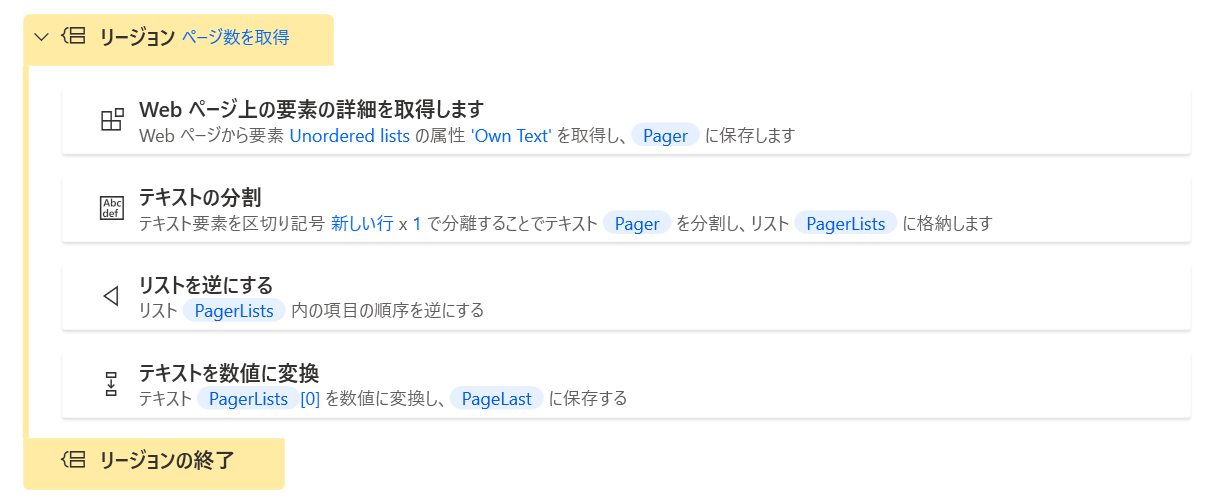
- 最大数を取得
ページャーの要素全体を取得して一番右の数値を取得します。
ページ数で配列が変わるので、リストを逆にしてからリストの[0]で取得。

沢山のページ、少数のページ、1 ページのみ、いずれも OK。
ループ
最大ページを取得したので、1 ページごとにスクレイピングしたデータを
テーブルにマージしていきます。
最後に CSV に出力。
イメージ

タイトルと著者のみのリストではなく、書籍・コミック・雑誌のカテゴリー別、さらにジャンル別に取得するように、上のループで URI にそれぞれの値を入れて回すようにしています。
設定は json で書きました。
まとめ
ページングで全ページのスクレイピングをするのが難しかったので
1 ページずつ取得したデータをマージして 1 つにした(力技)。
残りは省略
ページング出来た喜びで思わずまとめちゃいました。
そんなわけでここまでにします。おしまい。
おわりに
今の本棚

Discussion