💽
なが~~い会話でも、スマートAI!
話すこと
- 長い会話でスマートな回答を返すために、記憶とその検索を良くした
- In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue AgentsというGoogle等がだした論文
1. どんなもの?
LLMが過去の関連情報を保持・検索する力を良くする、Reflective Memory Management(RMM)を提案。RMMは、対話要約し、構造化された記憶を構築するProspective Reflection(見込みに基づく反映)と、LLMの応答生成における結果で検索をオンラインで洗練するRetrospective Reflection(回顧に基づく反映)で向上した。
RAG全般に使えるアイデアと思う。
- セッションが終わると、会話を分解、要約してトピックにし、既存記憶に統合するか新規に追加する。

- ユーザー入力があると、Retrieverが検索して、Rerankerが順位付し、LLMがM番目までの情報もつかい回答、すると同時に、各検索情報が引用されたかどうかもLLMが判断し、Rerankerの強化学習の報酬としてつかわれ、その場(オンライン)で学習される。

2. 先行研究と比べてどこがすごいの?
柔軟な記憶、検索機能な改善
3. 技術や手法の"キモ"はどこにある?
- Rerankerのオンライン学習
- 記憶を更新していくところ
4. どうやって有効だと検証した?
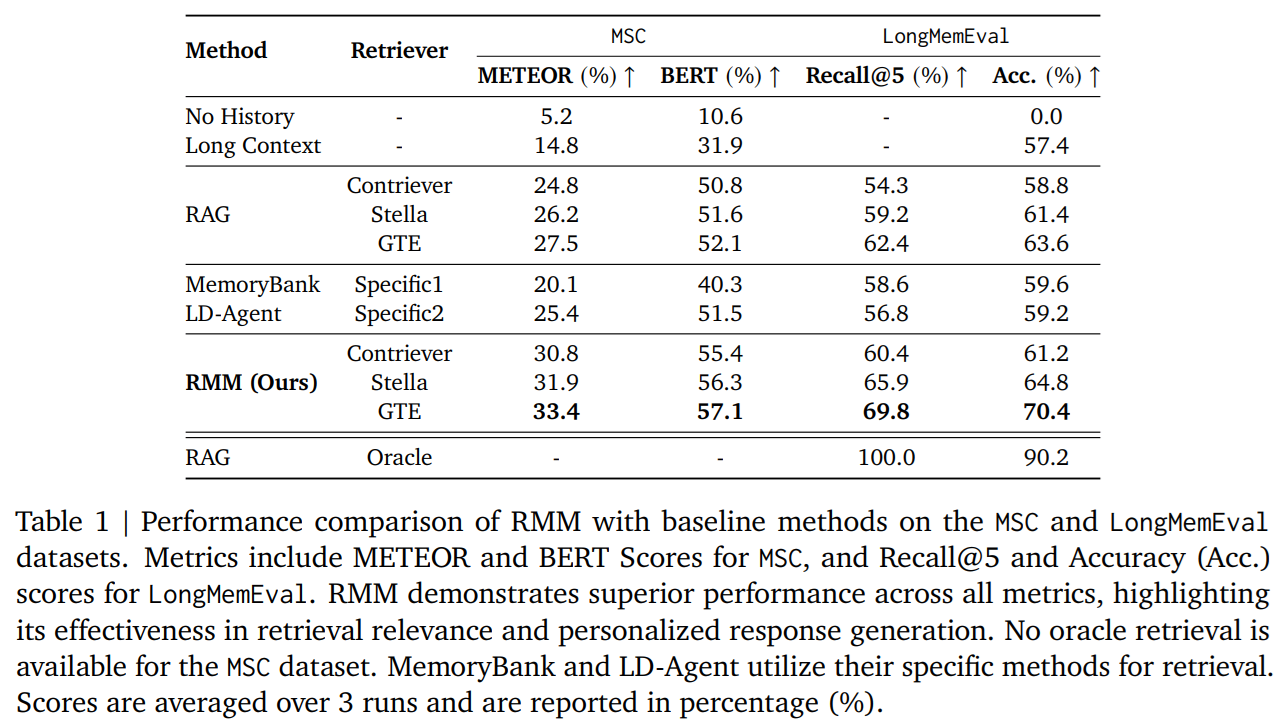
- MSC,LongMemEvalデータセットと他の方法と比べRMMが一番
- LongContextでは、コンテキスト長以上のデータはカット,Oracleでは、必要な情報は手動で渡す(検索は完全)
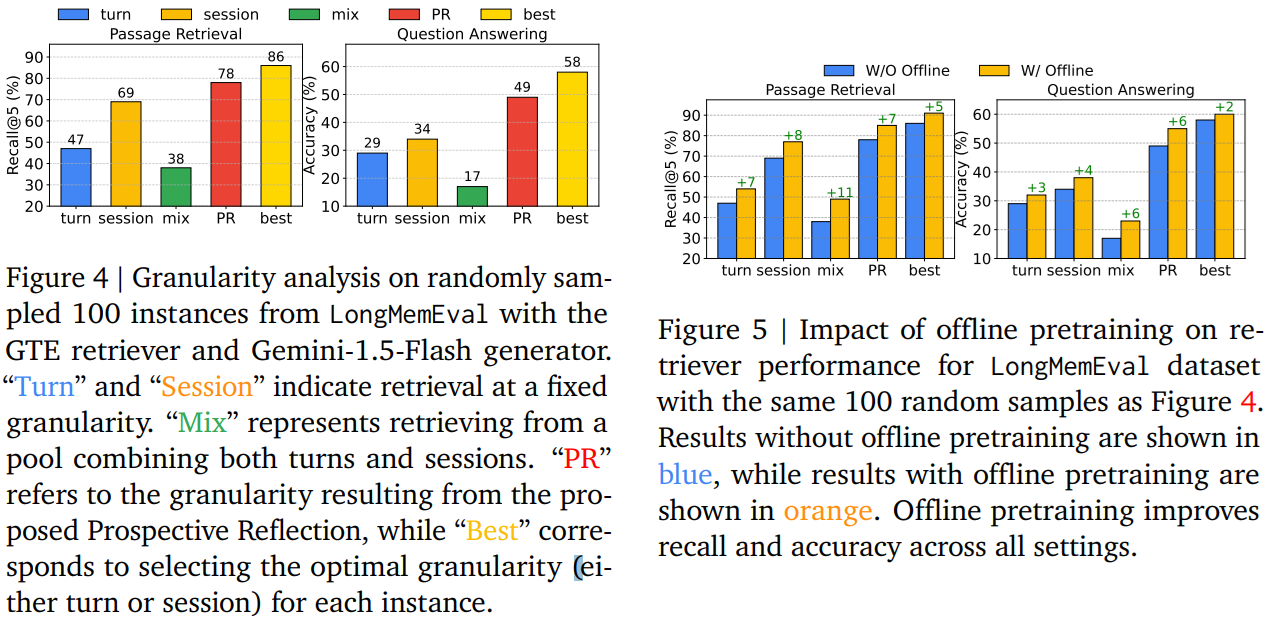
- 部品切り分けテスト、全部使うのが一番いい
- w/o rerankerはreranker使わず、reiriverをFTする(embeddingを行うモデルをFTすることだと思う)
- 「turn」(会話のターンごと)、「session」(会話のセッションごと)、「mix」(ターンとセッションを組み合わせたもの)の固定された粒度と、Prospective Reflectionで得られた粒度、最適なturnかsessionの組み合わせでの検索性能の比較
- Figure5では、オフラインで事前学習している(embedding部分だと思われる)
5. 議論はあるか?
- 普通の資料を保管するRAGなでに適用できそうか考えたが、追記することによる弊害がでそう
- エージェントフレームワークとかに、実装されていくのかな思うが、強化学習はオフラインにまずなるのかな思った。
あとがき
記事よかったら、いいね♡ 押してね!
Discussion