📽️
写真 と ことば
前書き
- 輪読会でV&Lタスクの担当になった。土日で内容、論文等確認した。斜め読みではあるが、資料にもなるし自分の理解で記事にした。
- 2020年位の論文が、もう古く感じるからすごい。ちょっとまえまでは、事前学習はあるにしろ個別タスクでFTするみたいだが、今やLLMが画像も使えて、ゼロショットでしかも精度が高そう。
- AWSを初めてみて、俺必要なくなる(´;ω;`)と思い 、少し経って、規模の経済の大事さも気づいたのを思い出した。今の時代、画像タスクもLLMをまず頑張るのがいいような気がする。
V&Lタスクのまとめ
- 画像と言語使うタスクのことだから、そりゃーいろいろある。
- 難しい点でよく言われるのが、言語は離散的、画像は連続値で性質がことなる者同士を対応付けするのがむずい。画像は、少なくとも色は、コンピューター上では比例尺度、空間的にも他の物体がくるまで、連続的かな思う(edgeは離散的?)、言葉は、名義尺度になるのか。
- Transfoemerがでてくるまえは、この結び付けを、単に連結や要素積や外積、注意機構でやってたみたい。
- 画像の特徴抽出に関しては、大きく2つ。まず、CNN,Vitの中間特徴Map(グリッド特徴)を使う。あとは、物体検出モデルの物体領域から抽出した特徴を使う(Faster R-CNN使うが一般的だったらしい)。物体検出モデルの問題点は、高計算コスト、個々の物体検出が主な目的で文脈関係に弱い、検出漏れの可能性あり。
- 言葉の特徴抽出は、トークン化、単語埋め込み、RNNでの特徴抽出
ちょっと古い個別論文
Oscar
- 事前学習時に、物体検出がだしたTAGも入れて、7つの下流タスクで精度向上

- こちらは、クラスが重なっている画像のクラスをアンカーとして使う考えと、言葉の方が画像よりより明確に表現されているのを表している
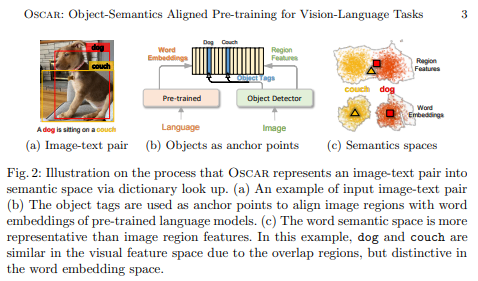
- 学習は、キャプションの単語やTagの15%をマスクして予測と物体Tagマッチングしているみたい(タグを入れ替えてるかどうかを2値分類)
- テキストとタグのトークン化方法は同じだから、テキスト同士の紐付けのほうが簡単そう
- ここで、自分のアイデアだが、タグの埋め込みを画像との中間的なのにしたら精度あがらないかな?思った。

VinVL
- 多分ほぼOscarのチームが、さらに発展したものだした
- VLの事前学習は、物体検出機の学習、言語と画像の統合機の学習と大きく2つあるが、通常後者ばっかりみんながんばってたところ、4つのデータセット使って、物体検出機向上したら、全体めっちゃよくなった論文

- 左はもとのX152-FPN物体検出機、右は4つのデータセットで学習したX142-C4、検出クラス等がめっちゃ増えている

CLIP
- webから集めた4億枚(画像とキャプションセット)で対比学習
キャプションの方がワンホットベクトルで表現できない概念が含まれている分、幅広い概念をベクトルに埋め込めていそう - 4億枚中、同じ写真なくても同じようなキャプションあるんじゃない?そしたら対比学習に悪影響ありそう。その観点からもアブレーションスタディとして、キャプションを正規化するしないでどんな変化あるか確認したら面白そう。
- 4億枚のペアで対比学習するまえに、画像、キャプションそれぞれで対比学習をその前にしても意味がありそう。
- 図の左が学習、右が推論

CyCLIP
- 左の図では、猫の画像が猫テキストには近いが、画像では犬に近い。つまり画像空間、言語空間で表現が一致していない。
- 右の図のようになるようにしたらいいよねって考えた!
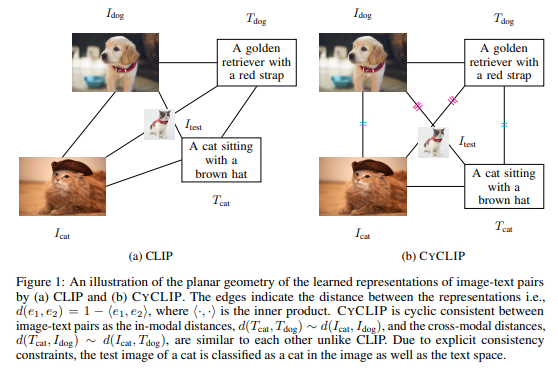
- 上が赤の2重線、下が青の重線のためのlosss計算

- これで0ショット性能上がった
PAINT (patching with interpolation)
- CLIPをFTすると、対象タスク以外の性能が大きく劣化してしまう破滅的忘却を防ぐ方法
- 最初のモデルとFT後のモデルの中間を使う(以下の線形補間で計算)

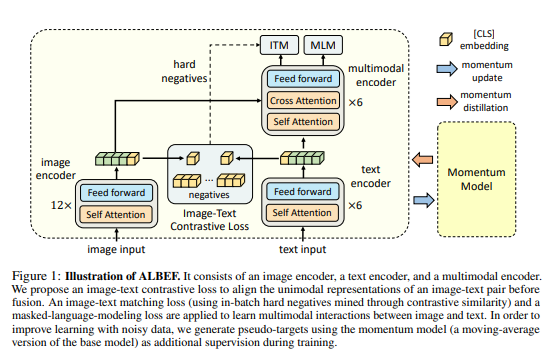
ALBEF
- 物体検出機いらなくした!
- 画像とことばを統合するまえに対比学習(ペアの正例と負例)でアライメントしたよ
- あと学習は、統合後の特徴で、マスク予測と画像、テキストのペアの正例と負例予測
- Momentum Modelを疑似ラベルにして蒸留している。(corruptしないのは、移動平均で少しモデル出力が違うからだけ?)
CoCa
- 事前学習でcaptionningしたら性能あがった!(難しいタスクだからかな?と思った)

- CLIPよりcaptionningさせたほうが、スケールメリットはじめいろいろいいみたい。
- 計算コストが問題とのことだが、これもMercuryとか拡散言語モデルで軽減するな思った。
- データに関しては、強化学習で用意できそう。画像見て、キャプショニングしたのを再度画像にして..再構成誤差をいろんな方式で試す
BLIP-2
- LLMを利用可能にした!?
- 学習ステップ1で、画像エンコーダの出力をLLMにあわせるQ-Fomerを画像、テキストの対比学習、マッチング、画像キャプション作成を通じて作成
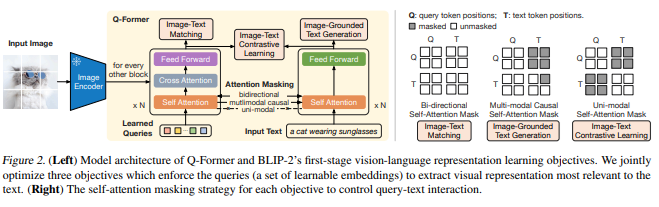
- 学習ステップ2の1,2で、LLMを学習

その他の画像とテキストの違い
構造化/非構造化 (Structured/Unstructured)
テキスト:文法規則に従った構造を持つ
画像:明示的な構造がなく、空間的に分布
象徴的/アナログ的 (Symbolic/Analog)
テキスト:記号(シンボル)の組み合わせで意味を表現
画像:連続的な変化で情報を表現
順序的/空間的 (Sequential/Spatial)
テキスト:一次元的な順序を持つ
画像:二次元的な空間情報を持つ
明示的/潜在的 (Explicit/Implicit)
テキスト:意味が比較的明示的に表現される
画像:情報が潜在的・暗黙的に埋め込まれている
低次元/高次元 (Low-dimensional/High-dimensional)
テキスト:語彙サイズに制約された次元性
画像:ピクセル数×色チャネルの高次元空間
スパース/デンス (Sparse/Dense)
テキスト:情報がスパース(疎)に分布
画像:情報が密(デンス)に分布
コンテキスト依存/自己完結的 (Context-dependent/Self-contained)
テキスト:多くの場合、完全な理解にはコンテキストが必要
画像:単体でより多くの情報を伝えられる場合がある
あとがき
記事よかったら、いいね♡ 押してね!
Discussion