🦁
DeepSeek R1! わくわく強化学習
前書き
DeepSeekすごい! 先々週末Transformer構造改善を読んですごいとは思ってた。木曜夜にR1の論文読んで、パラダイムシフト?とわくわくした。
読んで思ったこと
- DeepSeekのRLの改善方法いくつか考えた。幾つかは論文で明言してないけどやってそう。
"問題の選び方、報酬の設定のしかた等、現在人間がやっている部分もメタ的に強化学習、つまり強化学習の2段階構造にできないかな?"はやってないかも? - 最大サイズで、アイデア試したいが、蒸留モデルでもまあ賢いということで、瞬間風速的にならモデルクラス別で、リーダーボード世界一なれるかもと夢見た。
2/16深夜追記> コンテキスト長を8K -> 16K -> 24K と上げながら強化学習してAIMEで1.5Bの小さいモデルでo1-previewに勝ったとのこと。 "みじけえ夢だったな"ナウシカのクロトワのセリフ思い出した! - 自分がそう思うくらいだから、一家に一AI的に作るひとが増えるかも、企業も個別にAIを作る意味、メリット、デメリット考えるべきかと思った。この機会に速く動き出した方がいい?
- 強化学習だけで、できるようになると、社会(環境)と直接やりとりできる実験場があると有利。その意味だとAmazonとか大手で何かサービスしているところがやはり強いか?
- 個人で社会的実験場をどう戦略的にやればいいかを考えている。一例は、OperatorなどのwebAgentなどのAgentのtoolを使って....
- 上記は、シングラリティサロンの松田先生がカンブリア爆発起こる?とか話されていた。これで思い出したフェイフェイリーがImageNetのプレゼンでAIが視覚(カンブリア爆発起こった大きな理由)を得て、カンブリア爆発を起こす話。これはOpenAI operatorは画面をたしかHTMLでなく画面を視覚的に見てたことに繋がる。Operatorが社会の窓(視覚)
- 社会的には、DeepSeek(中)が、OpenAI(米)が隠してきた推論モデルの作り方をオープンにした可能性(盗んだわけでなく)や、少なくても(やっぱり?)強化学習だけでできるよ(しかも安く、完全ではないかも)と教えてくれた点で、少し米中の考え方の見直し必要かもと自分は思いました。
2/17早朝追記> open-R1というDeepSeekr1を再現しながらよりオープンにしようというプロジェクトが始まっている。 - 今回Deepsheek-V3-BASEが開始点、現状はこのくらい頭良くないと推論能力あげる強化学習できないとは思うが、完全乱数初期値の重みに近いところで、強化学習ができる最低セット何か?を考えたい。
視力があって、ある範囲をぼやかして、推論して、合っているか判断して喜ぶ信号をもらえる何か(人)とかになるのかな? (赤ちゃんをイメージしました)
天才(成田さん、ヒントン)の経験のみ与えて、機械に同じ知能与えられるか?
1. どんなもの?
アハ体験やモデルが以前の手順を再検討して再評価、問題解決への代替アプローチの探索などするモデルを作った!これは強化学習でAIが自分で手に入れた!

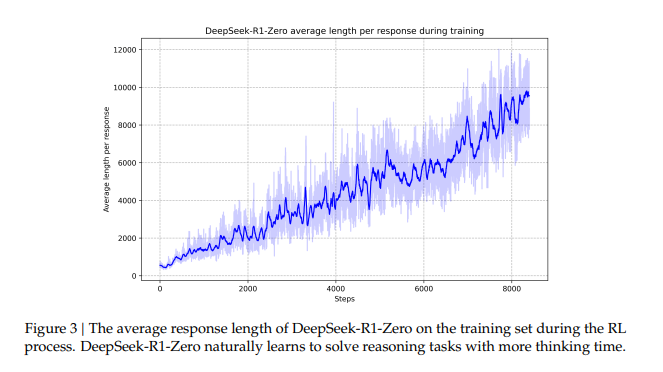
学習が進むと問題解決へつながる長い返答へ
AIMEベンチマークで15.6%から71.0%へ強化学習だけで成長!多数決でさらに86.7%に!

蒸留で推論能力を引き継げることも確認し、蒸留モデルも公開
2. 先行研究と比べてどこがすごいの?
報酬をルールベースにした。
また、GRPO(これは以前の論文から)で、ValueModelもいらないので、強化学習するうえで計算コストが、めちゃ少ない。学習も安定化すると思われる。
3. 技術や手法の"キモ"はどこにある?
LLMでの強化学習の可能性を見せつけた?!
今までも、いろんなとこが使って効果は出していただろうが、今はパラダイムシフトの印象
よく他のLLM+強化学習の論文、記事読んだら印象変わるかも
4.次に読むべきおすすめ論文
あとがき
まだまだ書きたいことあるが、更新続いたので2を週末でも書きます
記事よかったら、いいね♡ 押してね!
Discussion